 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Replication to Redesign: Exploring Pairwise Comparisons for LLM-Based Peer Review
Jun 12, 2025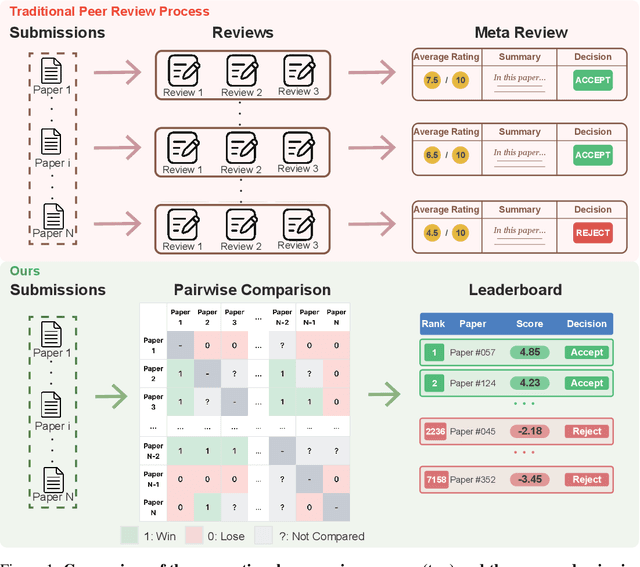
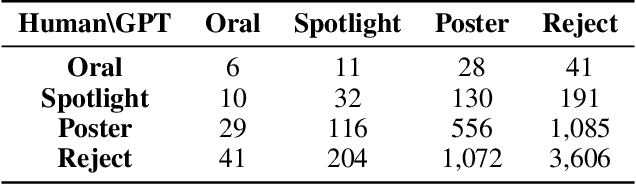
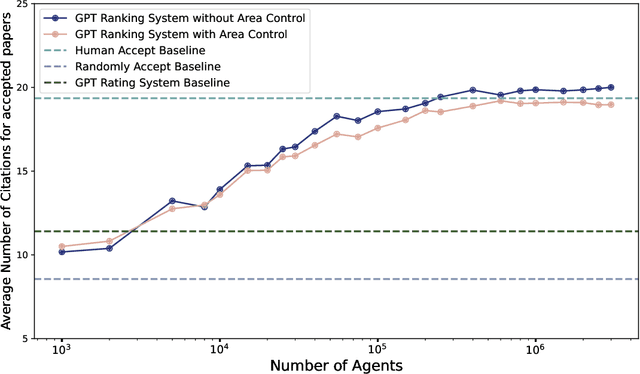
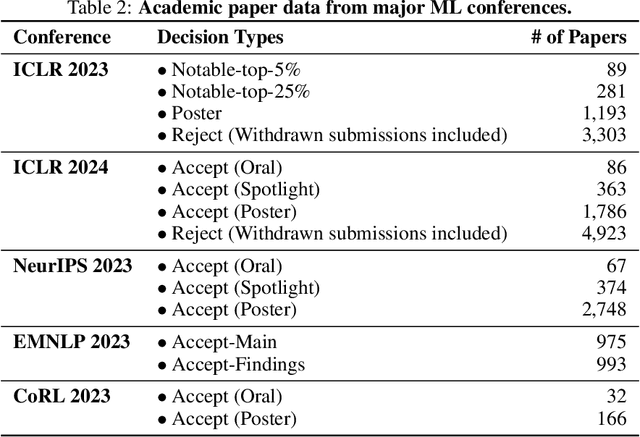
The advent of large language models (LLMs) offers unprecedented opportunities to reimagine peer review beyond the constraints of traditional workflows. Despite these opportunities, prior efforts have largely focused on replicating traditional review workflows with LLMs serving as direct substitutes for human reviewers, while limited attention has been given to exploring new paradigms that fundamentally rethink how LLMs can participate in the academic review process. In this paper, we introduce and explore a novel mechanism that employs LLM agents to perform pairwise comparisons among manuscripts instead of individual scoring. By aggregating outcomes from substantial pairwise evaluations, this approach enables a more accurate and robust measure of relative manuscript quality. Our experiments demonstrate that this comparative approach significantly outperforms traditional rating-based methods in identifying high-impact papers. However, our analysis also reveals emergent biases in the selection process, notably a reduced novelty in research topics and an increased institutional imbalance. These findings highlight both the transformative potential of rethinking peer review with LLMs and critical challenges that future systems must address to ensure equity and diversity.
FlowRetrieval: Flow-Guided Data Retrieval for Few-Shot Imitation Learning
Aug 29, 2024Few-shot imitation learning relies on only a small amount of task-specific demonstrations to efficiently adapt a policy for a given downstream tasks. Retrieval-based methods come with a promise of retrieving relevant past experiences to augment this target data when learning policies. However, existing data retrieval methods fall under two extremes: they either rely on the existence of exact behaviors with visually similar scenes in the prior data, which is impractical to assume; or they retrieve based on semantic similarity of high-level language descriptions of the task, which might not be that informative about the shared low-level behaviors or motions across tasks that is often a more important factor for retrieving relevant data for policy learning. In this work, we investigate how we can leverage motion similarity in the vast amount of cross-task data to improve few-shot imitation learning of the target task. Our key insight is that motion-similar data carries rich information about the effects of actions and object interactions that can be leveraged during few-shot adaptation. We propose FlowRetrieval, an approach that leverages optical flow representations for both extracting similar motions to target tasks from prior data, and for guiding learning of a policy that can maximally benefit from such data. Our results show FlowRetrieval significantly outperforms prior methods across simulated and real-world domains, achieving on average 27% higher success rate than the best retrieval-based prior method. In the Pen-in-Cup task with a real Franka Emika robot, FlowRetrieval achieves 3.7x the performance of the baseline imitation learning technique that learns from all prior and target data. Website: https://flow-retrieval.github.io
Self-supervision through Random Segments with Autoregressive Coding (RandSAC)
Mar 22, 2022

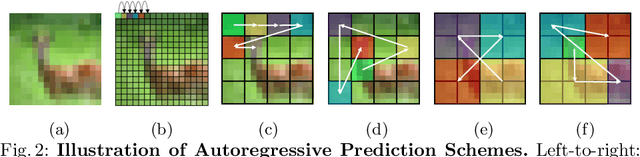

Inspired by the success of self-supervised autoregressive representation learning in natural language (GPT and its variants), and advances in recent visual architecture design with Vision Transformers (ViTs), in this paper, we explore the effects various design choices have on the success of applying such training strategies for visual feature learning. Specifically, we introduce a novel strategy that we call Random Segments with Autoregressive Coding (RandSAC). In RandSAC, we group patch representations (image tokens) into hierarchically arranged segments; within each segment, tokens are predicted in parallel, similar to BERT, while across segment predictions are sequential, similar to GPT. We illustrate that randomized serialization of the segments significantly improves the performance and results in distribution over spatially-long (across-segments) and -short (within-segment) predictions which are effective for feature learning. We illustrate the pertinence of these design choices and explore alternatives on a number of datasets (e.g., CIFAR10, ImageNet). While our pre-training strategy works with vanilla Transformer, we also propose a conceptually simple, but highly effective, addition to the decoder that allows learnable skip-connections to encoder feature layers, which further improves the performance. Our final model, trained on ImageNet, achieves new state-of-the-art linear probing performance 68.3% among comparative predictive self-supervised learning approaches.
Co-advise: Cross Inductive Bias Distillation
Jun 23, 2021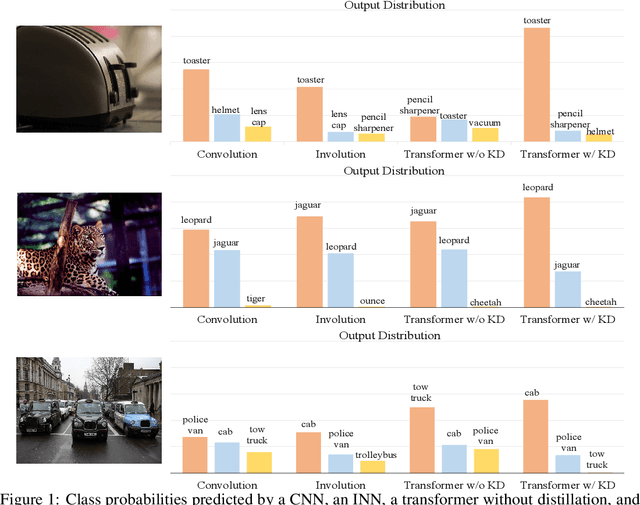
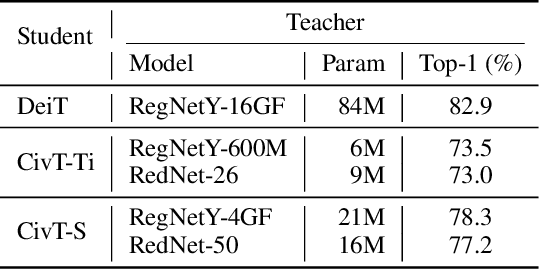

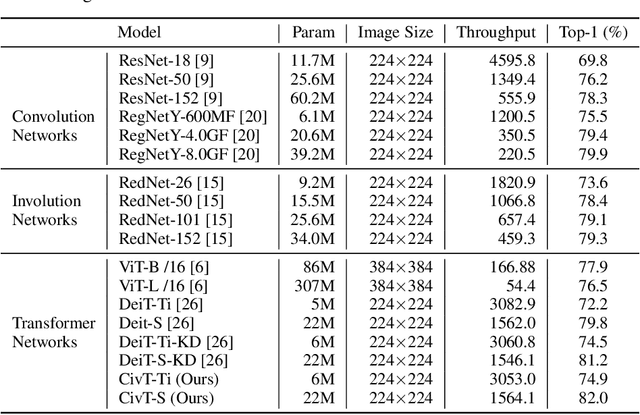
Transformers recently are adapted from the community of natural language processing as a promising substitute of convolution-based neural networks for visual learning tasks. However, its supremacy degenerates given an insufficient amount of training data (e.g., ImageNet). To make it into practical utility, we propose a novel distillation-based method to train vision transformers. Unlike previous works, where merely heavy convolution-based teachers are provided, we introduce lightweight teachers with different architectural inductive biases (e.g., convolution and involution) to co-advise the student transformer. The key is that teachers with different inductive biases attain different knowledge despite that they are trained on the same dataset, and such different knowledge compounds and boosts the student's performance during distillation. Equipped with this cross inductive bias distillation method, our vision transformers (termed as CivT) outperform all previous transformers of the same architecture on ImageNet.
Improving Multi-Modal Learning with Uni-Modal Teachers
Jun 21, 2021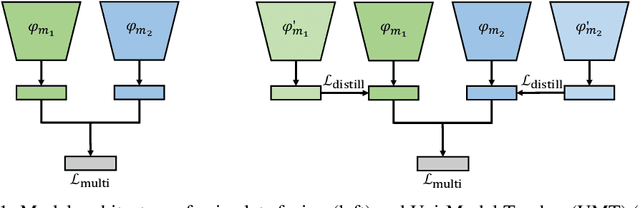
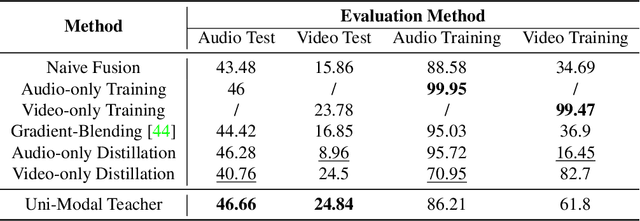
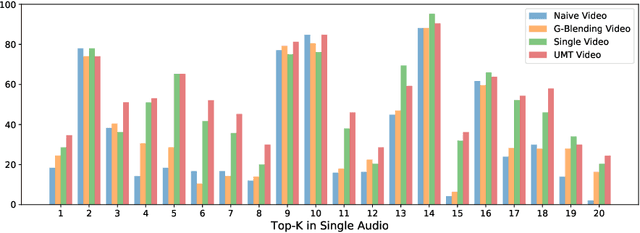

Learning multi-modal representations is an essential step towards real-world robotic applications, and various multi-modal fusion models have been developed for this purpose. However, we observe that existing models, whose objectives are mostly based on joint training, often suffer from learning inferior representations of each modality. We name this problem Modality Failure, and hypothesize that the imbalance of modalities and the implicit bias of common objectives in fusion method prevent encoders of each modality from sufficient feature learning. To this end, we propose a new multi-modal learning method, Uni-Modal Teacher, which combines the fusion objective and uni-modal distillation to tackle the modality failure problem. We show that our method not only drastically improves the representation of each modality, but also improves the overall multi-modal task performance. Our method can be effectively generalized to most multi-modal fusion approaches. We achieve more than 3% improvement on the VGGSound audio-visual classification task, as well as improving performance on the NYU depth V2 RGB-D image segmentation task.
On Feature Decorrelation in Self-Supervised Learning
May 02, 2021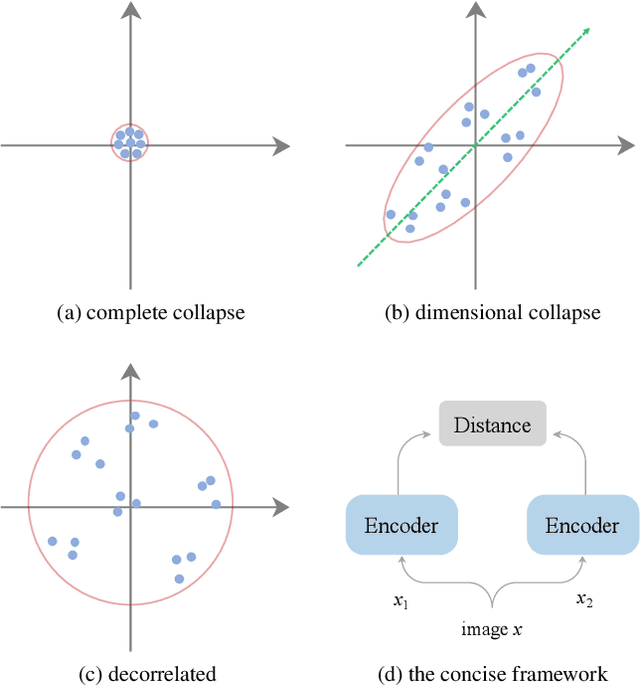
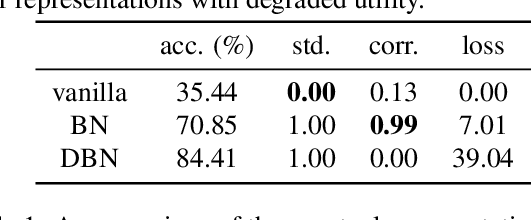

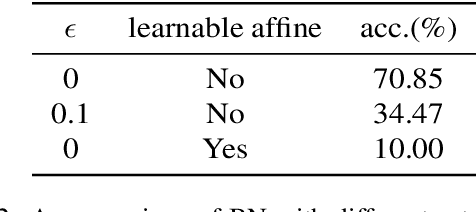
In self-supervised representation learning, a common idea behind most of the state-of-the-art approaches is to enforce the robustness of the representations to predefined augmentations. A potential issue of this idea is the existence of completely collapsed solutions (i.e., constant features), which are typically avoided implicitly by carefully chosen implementation details. In this work, we study a relatively concise framework containing the most common components from recent approaches. We verify the existence of complete collapse and discover another reachable collapse pattern that is usually overlooked, namely dimensional collapse. We connect dimensional collapse with strong correlations between axes and consider such connection as a strong motivation for feature decorrelation (i.e., standardizing the covariance matrix). The capability of correlation as an unsupervised metric and the gains from feature decorrelation are verified empirically to highlight the importance and the potential of this insight.
Exploiting Relationship for Complex-scene Image Generation
Apr 01, 2021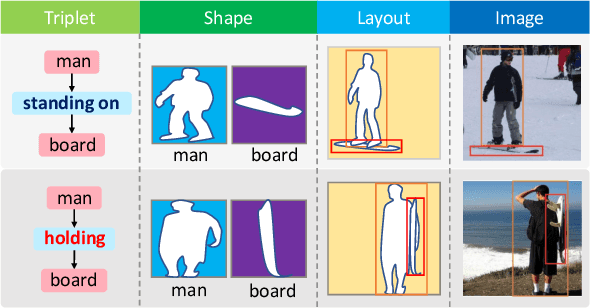
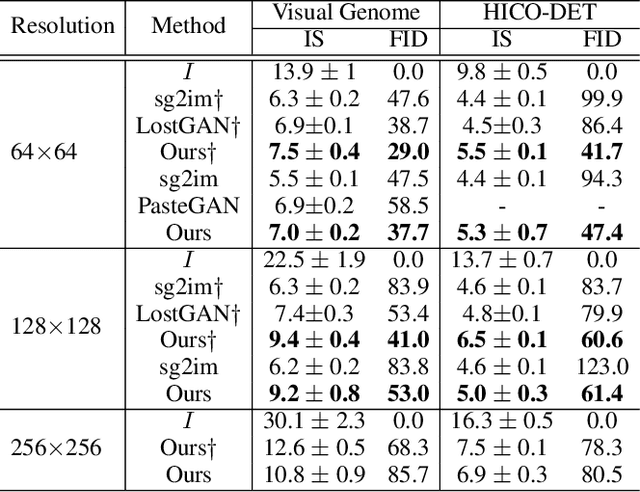
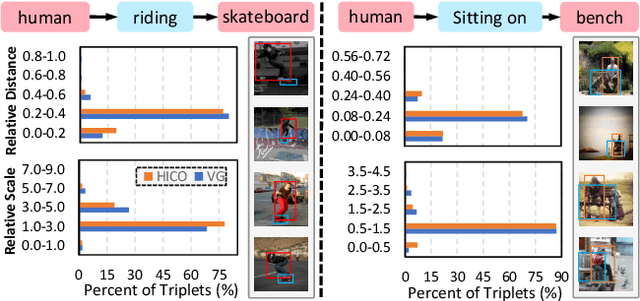

The significant progress on Generative Adversarial Networks (GANs) has facilitated realistic single-object image generation based on language input. However, complex-scene generation (with various interactions among multiple objects) still suffers from messy layouts and object distortions, due to diverse configurations in layouts and appearances. Prior methods are mostly object-driven and ignore their inter-relations that play a significant role in complex-scene images. This work explores relationship-aware complex-scene image generation, where multiple objects are inter-related as a scene graph. With the help of relationships, we propose three major updates in the generation framework. First, reasonable spatial layouts are inferred by jointly considering the semantics and relationships among objects. Compared to standard location regression, we show relative scales and distances serve a more reliable target. Second, since the relations between objects significantly influence an object's appearance, we design a relation-guided generator to generate objects reflecting their relationships. Third, a novel scene graph discriminator is proposed to guarantee the consistency between the generated image and the input scene graph. Our method tends to synthesize plausible layouts and objects, respecting the interplay of multiple objects in an image. Experimental results on Visual Genome and HICO-DET datasets show that our proposed method significantly outperforms prior arts in terms of IS and FID metrics. Based on our user study and visual inspection, our method is more effective in generating logical layout and appearance for complex-scenes.
Modeling Gestalt Visual Reasoning on the Raven's Progressive Matrices Intelligence Test Using Generative Image Inpainting Techniques
Nov 26, 2019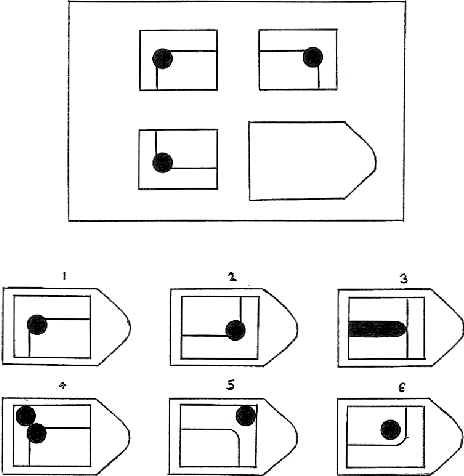


Psychologists recognize Raven's Progressive Matrices as a very effective test of general human intelligence. While many computational models have been developed by the AI community to investigate different forms of top-down, deliberative reasoning on the test, there has been less research on bottom-up perceptual processes, like Gestalt image completion, that are also critical in human test performance. In this work, we investigate how Gestalt visual reasoning on the Raven's test can be modeled using generative image inpainting techniques from computer vision. We demonstrate that a self-supervised inpainting model trained only on photorealistic images of objects achieves a score of 27/36 on the Colored Progressive Matrices, which corresponds to average performance for nine-year-old children. We also show that models trained on other datasets (faces, places, and textures) do not perform as well. Our results illustrate how learning visual regularities in real-world images can translate into successful reasoning about artificial test stimuli. On the flip side, our results also highlight the limitations of such transfer, which may explain why intelligence tests like the Raven's are often sensitive to people's individual sociocultural backgrounds.