 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Let the Video Speak: Audio-Contrastive Preference Optimization for Audio-Visual Language Models
Apr 15, 2026While Audio-Visual Language Models (AVLMs) have achieved remarkable progress over recent years, their reliability is bottlenecked by cross-modal hallucination. A particularly pervasive manifestation is video-driven audio hallucination: models routinely exploit visual shortcuts to hallucinate expected sounds, discarding true auditory evidence. To counteract this deeply ingrained visual dominance, we propose Audio-Contrastive Preference Optimization (ACPO). This dual-axis preference learning framework introduces an output-contrastive objective to penalize visual descriptions masquerading as audio facts, alongside an input-contrastive objective that swaps audio tracks to explicitly penalize generation invariant to the true auditory signal. Extensive experiments demonstrate that ACPO establishes highly faithful audio grounding and mitigates audio hallucination without compromising overarching multimodal capabilities.
SPOC: Spatially-Progressing Object State Change Segmentation in Video
Mar 15, 2025Object state changes in video reveal critical information about human and agent activity. However, existing methods are limited to temporal localization of when the object is in its initial state (e.g., the unchopped avocado) versus when it has completed a state change (e.g., the chopped avocado), which limits applicability for any task requiring detailed information about the progress of the actions and its spatial localization. We propose to deepen the problem by introducing the spatially-progressing object state change segmentation task. The goal is to segment at the pixel-level those regions of an object that are actionable and those that are transformed. We introduce the first model to address this task, designing a VLM-based pseudo-labeling approach, state-change dynamics constraints, and a novel WhereToChange benchmark built on in-the-wild Internet videos. Experiments on two datasets validate both the challenge of the new task as well as the promise of our model for localizing exactly where and how fast objects are changing in video. We further demonstrate useful implications for tracking activity progress to benefit robotic agents. Project page: https://vision.cs.utexas.edu/projects/spoc-spatially-progressing-osc
REG: Rectified Gradient Guidance for Conditional Diffusion Models
Jan 31, 2025Guidance techniques are simple yet effective for improving conditional generation in diffusion models. Albeit their empirical success, the practical implementation of guidance diverges significantly from its theoretical motivation. In this paper, we reconcile this discrepancy by replacing the scaled marginal distribution target, which we prove theoretically invalid, with a valid scaled joint distribution objective. Additionally, we show that the established guidance implementations are approximations to the intractable optimal solution under no future foresight constraint. Building on these theoretical insights, we propose rectified gradient guidance (REG), a versatile enhancement designed to boost the performance of existing guidance methods. Experiments on 1D and 2D demonstrate that REG provides a better approximation to the optimal solution than prior guidance techniques, validating the proposed theoretical framework. Extensive experiments on class-conditional ImageNet and text-to-image generation tasks show that incorporating REG consistently improves FID and Inception/CLIP scores across various settings compared to its absence.
Progress-Aware Video Frame Captioning
Dec 03, 2024
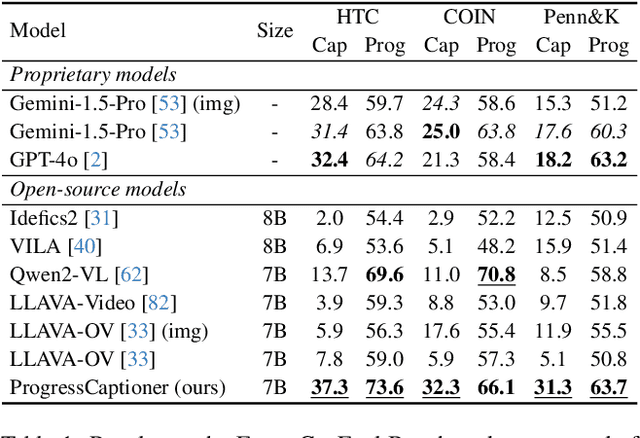
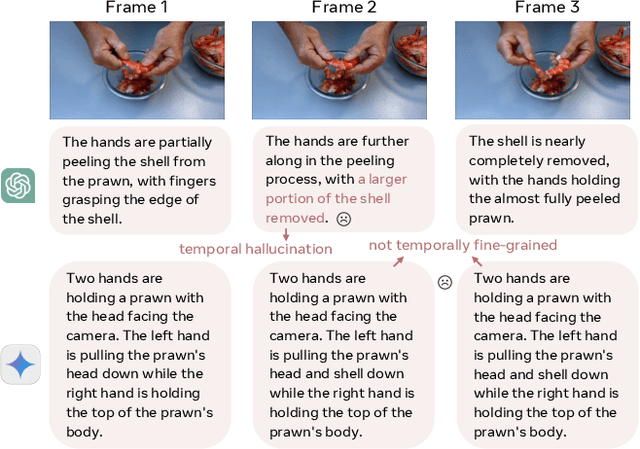
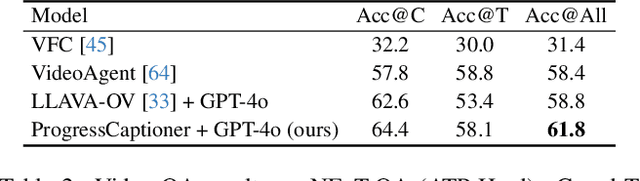
While image captioning provides isolated descriptions for individual images, and video captioning offers one single narrative for an entire video clip, our work explores an important middle ground: progress-aware video captioning at the frame level. This novel task aims to generate temporally fine-grained captions that not only accurately describe each frame but also capture the subtle progression of actions throughout a video sequence. Despite the strong capabilities of existing leading vision language models, they often struggle to discern the nuances of frame-wise differences. To address this, we propose ProgressCaptioner, a captioning model designed to capture the fine-grained temporal dynamics within an action sequence. Alongside, we develop the FrameCap dataset to support training and the FrameCapEval benchmark to assess caption quality. The results demonstrate that ProgressCaptioner significantly surpasses leading captioning models, producing precise captions that accurately capture action progression and set a new standard for temporal precision in video captioning. Finally, we showcase practical applications of our approach, specifically in aiding keyframe selection and advancing video understanding, highlighting its broad utility.
Action2Sound: Ambient-Aware Generation of Action Sounds from Egocentric Videos
Jun 13, 2024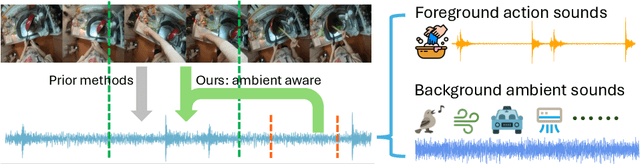


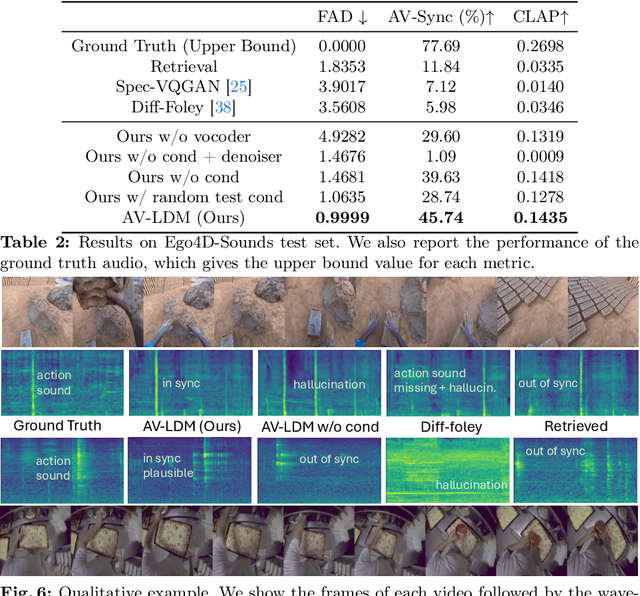
Generating realistic audio for human interactions is important for many applications, such as creating sound effects for films or virtual reality games. Existing approaches implicitly assume total correspondence between the video and audio during training, yet many sounds happen off-screen and have weak to no correspondence with the visuals -- resulting in uncontrolled ambient sounds or hallucinations at test time. We propose a novel ambient-aware audio generation model, AV-LDM. We devise a novel audio-conditioning mechanism to learn to disentangle foreground action sounds from the ambient background sounds in in-the-wild training videos. Given a novel silent video, our model uses retrieval-augmented generation to create audio that matches the visual content both semantically and temporally. We train and evaluate our model on two in-the-wild egocentric video datasets Ego4D and EPIC-KITCHENS. Our model outperforms an array of existing methods, allows controllable generation of the ambient sound, and even shows promise for generalizing to computer graphics game clips. Overall, our work is the first to focus video-to-audio generation faithfully on the observed visual content despite training from uncurated clips with natural background sounds.
HOI-Swap: Swapping Objects in Videos with Hand-Object Interaction Awareness
Jun 11, 2024


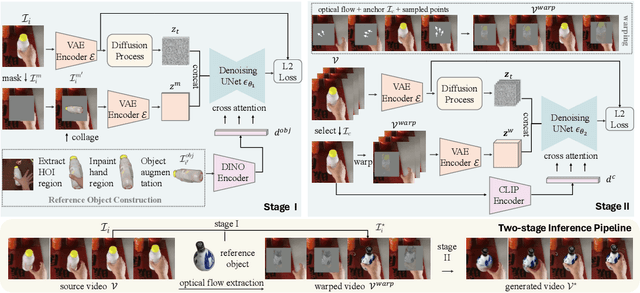
We study the problem of precisely swapping objects in videos, with a focus on those interacted with by hands, given one user-provided reference object image. Despite the great advancements that diffusion models have made in video editing recently, these models often fall short in handling the intricacies of hand-object interactions (HOI), failing to produce realistic edits -- especially when object swapping results in object shape or functionality changes. To bridge this gap, we present HOI-Swap, a novel diffusion-based video editing framework trained in a self-supervised manner. Designed in two stages, the first stage focuses on object swapping in a single frame with HOI awareness; the model learns to adjust the interaction patterns, such as the hand grasp, based on changes in the object's properties. The second stage extends the single-frame edit across the entire sequence; we achieve controllable motion alignment with the original video by: (1) warping a new sequence from the stage-I edited frame based on sampled motion points and (2) conditioning video generation on the warped sequence. Comprehensive qualitative and quantitative evaluations demonstrate that HOI-Swap significantly outperforms existing methods, delivering high-quality video edits with realistic HOIs.
Put Myself in Your Shoes: Lifting the Egocentric Perspective from Exocentric Videos
Mar 11, 2024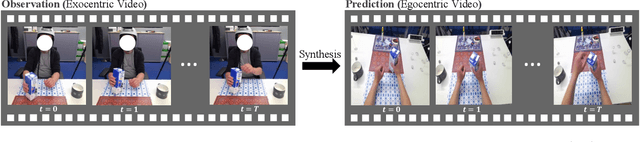
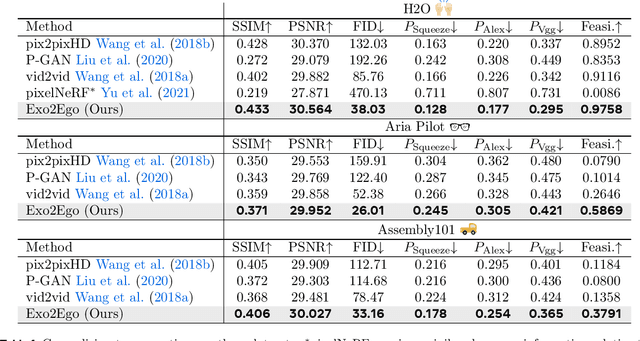
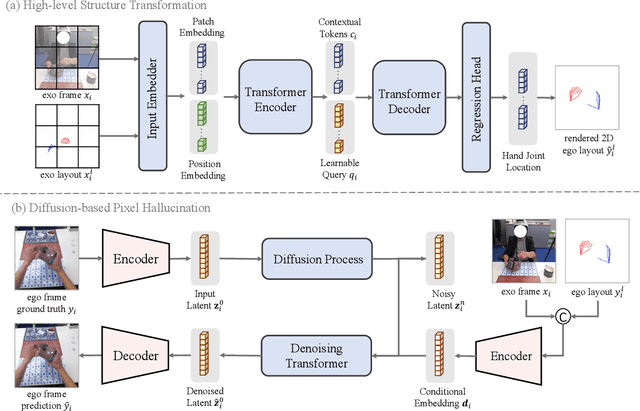
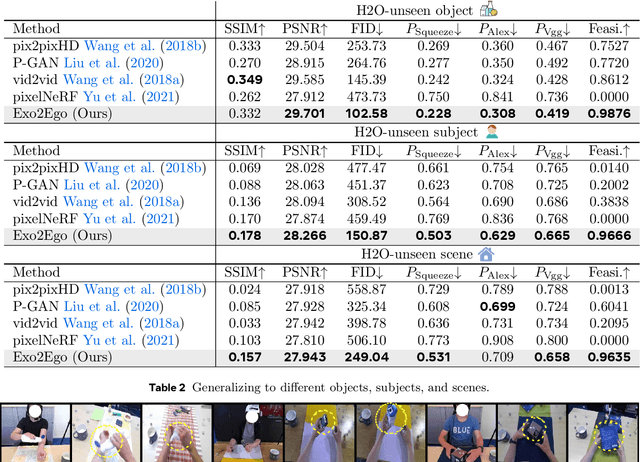
We investigate exocentric-to-egocentric cross-view translation, which aims to generate a first-person (egocentric) view of an actor based on a video recording that captures the actor from a third-person (exocentric) perspective. To this end, we propose a generative framework called Exo2Ego that decouples the translation process into two stages: high-level structure transformation, which explicitly encourages cross-view correspondence between exocentric and egocentric views, and a diffusion-based pixel-level hallucination, which incorporates a hand layout prior to enhance the fidelity of the generated egocentric view. To pave the way for future advancements in this field, we curate a comprehensive exo-to-ego cross-view translation benchmark. It consists of a diverse collection of synchronized ego-exo tabletop activity video pairs sourced from three public datasets: H2O, Aria Pilot, and Assembly101. The experimental results validate that Exo2Ego delivers photorealistic video results with clear hand manipulation details and outperforms several baselines in terms of both synthesis quality and generalization ability to new actions.
Detours for Navigating Instructional Videos
Jan 03, 2024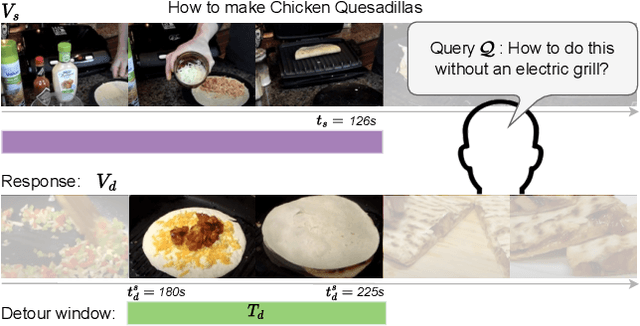
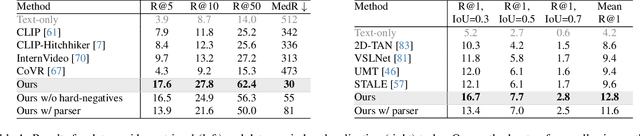

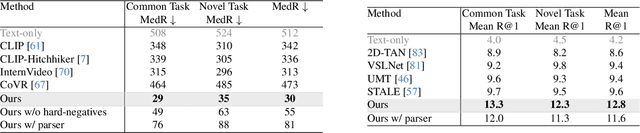
We introduce the video detours problem for navigating instructional videos. Given a source video and a natural language query asking to alter the how-to video's current path of execution in a certain way, the goal is to find a related ''detour video'' that satisfies the requested alteration. To address this challenge, we propose VidDetours, a novel video-language approach that learns to retrieve the targeted temporal segments from a large repository of how-to's using video-and-text conditioned queries. Furthermore, we devise a language-based pipeline that exploits how-to video narration text to create weakly supervised training data. We demonstrate our idea applied to the domain of how-to cooking videos, where a user can detour from their current recipe to find steps with alternate ingredients, tools, and techniques. Validating on a ground truth annotated dataset of 16K samples, we show our model's significant improvements over best available methods for video retrieval and question answering, with recall rates exceeding the state of the art by 35%.
Learning Object State Changes in Videos: An Open-World Perspective
Dec 19, 2023
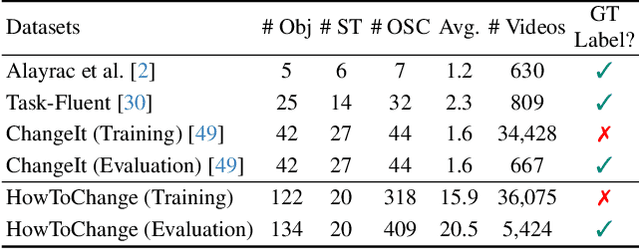
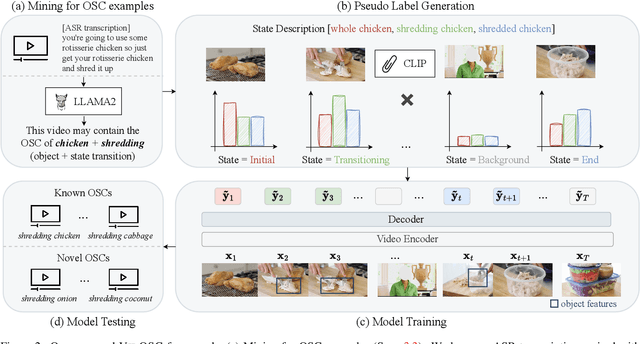
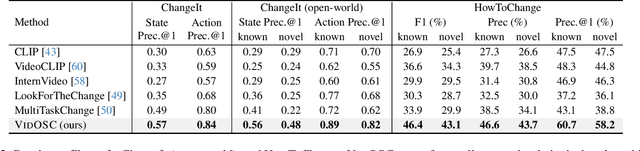
Object State Changes (OSCs) are pivotal for video understanding. While humans can effortlessly generalize OSC understanding from familiar to unknown objects, current approaches are confined to a closed vocabulary. Addressing this gap, we introduce a novel open-world formulation for the video OSC problem. The goal is to temporally localize the three stages of an OSC -- the object's initial state, its transitioning state, and its end state -- whether or not the object has been observed during training. Towards this end, we develop VidOSC, a holistic learning approach that: (1) leverages text and vision-language models for supervisory signals to obviate manually labeling OSC training data, and (2) abstracts fine-grained shared state representations from objects to enhance generalization. Furthermore, we present HowToChange, the first open-world benchmark for video OSC localization, which offers an order of magnitude increase in the label space and annotation volume compared to the best existing benchmark. Experimental results demonstrate the efficacy of our approach, in both traditional closed-world and open-world scenarios.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.