 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Multimodal Contrastive Learning and Incorporating Unpaired Data
Paper and Code



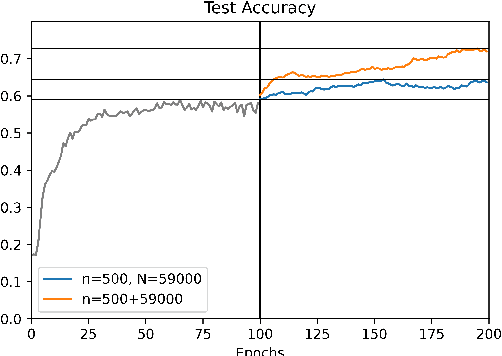
Language-supervised vision models have recently attracted great attention in computer vision. A common approach to build such models is to use contrastive learning on paired data across the two modalities, as exemplified by Contrastive Language-Image Pre-Training (CLIP). In this paper, under linear representation settings, (i) we initiate the investigation of a general class of nonlinear loss functions for multimodal contrastive learning (MMCL) including CLIP loss and show its connection to singular value decomposition (SVD). Namely, we show that each step of loss minimization by gradient descent can be seen as performing SVD on a contrastive cross-covariance matrix. Based on this insight, (ii) we analyze the performance of MMCL. We quantitatively show that the feature learning ability of MMCL can be better than that of unimodal contrastive learning applied to each modality even under the presence of wrongly matched pairs. This characterizes the robustness of MMCL to noisy data. Furthermore, when we have access to additional unpaired data, (iii) we propose a new MMCL loss that incorporates additional unpaired datasets. We show that the algorithm can detect the ground-truth pairs and improve performance by fully exploiting unpaired datasets. The performance of the proposed algorithm was verified by numerical experiments.