 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Registration in 30 Years: A Survey
Dec 19, 2024



3D point cloud registration is a fundamental problem in computer vision, computer graphics, robotics, remote sensing, and etc. Over the last thirty years, we have witnessed the amazing advancement in this area with numerous kinds of solutions. Although a handful of relevant surveys have been conducted, their coverage is still limited. In this work, we present a comprehensive survey on 3D point cloud registration, covering a set of sub-areas such as pairwise coarse registration, pairwise fine registration, multi-view registration, cross-scale registration, and multi-instance registration. The datasets, evaluation metrics, method taxonomy, discussions of the merits and demerits, insightful thoughts of future directions are comprehensively presented in this survey. The regularly updated project page of the survey is available at https://github.com/Amyyyy11/3D-Registration-in-30-Years-A-Survey.
Instance by Instance: An Iterative Framework for Multi-instance 3D Registration
Feb 06, 2024



Multi-instance registration is a challenging problem in computer vision and robotics, where multiple instances of an object need to be registered in a standard coordinate system. In this work, we propose the first iterative framework called instance-by-instance (IBI) for multi-instance 3D registration (MI-3DReg). It successively registers all instances in a given scenario, starting from the easiest and progressing to more challenging ones. Throughout the iterative process, outliers are eliminated continuously, leading to an increasing inlier rate for the remaining and more challenging instances. Under the IBI framework, we further propose a sparse-to-dense-correspondence-based multi-instance registration method (IBI-S2DC) to achieve robust MI-3DReg. Experiments on the synthetic and real datasets have demonstrated the effectiveness of IBI and suggested the new state-of-the-art performance of IBI-S2DC, e.g., our MHF1 is 12.02%/12.35% higher than the existing state-of-the-art method ECC on the synthetic/real datasets.
Machine Learning Based Detection of Clickbait Posts in Social Media
Oct 05, 2017
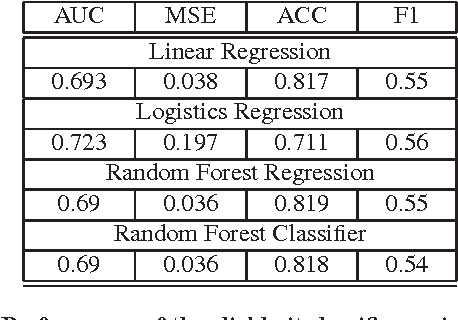
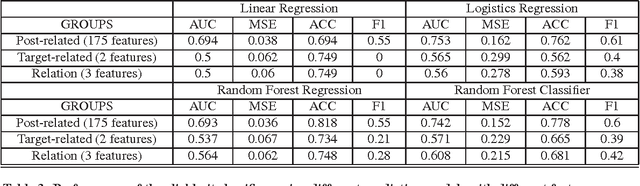

Clickbait (headlines) make use of misleading titles that hide critical information from or exaggerate the content on the landing target pages to entice clicks. As clickbaits often use eye-catching wording to attract viewers, target contents are often of low quality. Clickbaits are especially widespread on social media such as Twitter, adversely impacting user experience by causing immense dissatisfaction. Hence, it has become increasingly important to put forward a widely applicable approach to identify and detect clickbaits. In this paper, we make use of a dataset from the clickbait challenge 2017 (clickbait-challenge.com) comprising of over 21,000 headlines/titles, each of which is annotated by at least five judgments from crowdsourcing on how clickbait it is. We attempt to build an effective computational clickbait detection model on this dataset. We first considered a total of 331 features, filtered out many features to avoid overfitting and improve the running time of learning, and eventually selected the 60 most important features for our final model. Using these features, Random Forest Regression achieved the following results: MSE=0.035 MSE, Accuracy=0.82, and F1-sore=0.61 on the clickbait class.