 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoneWorld: Scaling Phone-Use Agent Environments
May 28, 2026A central bottleneck for phone-use agents is that controllable, reproducible environments covering real mobile behavior are hard to build at scale. Existing mobile-agent benchmarks have made important progress on evaluation, but they do not by themselves provide a scalable way to construct many new phone-use environments. We present PhoneWorld, a reusable pipeline that converts real GUI trajectories and screenshots into controllable phone-use environments, executable tasks, automatic verifiers, and training rollouts. Rather than hand-building one mobile benchmark at a time, PhoneWorld uses real trajectories to recover which screens matter, how screens connect, which interactions must change environment state, and which user goals admit automatic verification. From these signals, it builds runnable mock Android apps backed by read-only app content and mutable state, then derives executable tasks, rule-based verifiers, and training rollouts from the same environments. In its current instantiation, PhoneWorld covers 34 apps across 16 domains, spanning common consumer mobile behaviors such as search, browsing, shopping, booking, media, and social interaction. Under a fixed training budget, replacing 10K steps from an auxiliary AndroidWorld corpus in an AndroidWorld-based baseline with broad PhoneWorld supervision improves all four evaluation benchmarks at once, raising HYMobileBench by 17.7 points, AndroidControl by 6.0 points, AndroidWorld by 14.7 points, and PhoneWorld by 52.5 points. We then study two additional scaling questions: increasing the amount of PhoneWorld supervision strongly improves PhoneWorld performance, and under a fixed PhoneWorld budget, expanding app coverage yields even larger gains. Overall, PhoneWorld shifts the focus from building one mobile benchmark at a time to scaling the supply of phone-use environments themselves.
Smart Fast Finish: Preventing Overdelivery via Daily Budget Pacing at DoorDash
Sep 09, 2025We present a budget pacing feature called Smart Fast Finish (SFF). SFF builds upon the industry standard Fast Finish (FF) feature in budget pacing systems that depletes remaining advertising budget as quickly as possible towards the end of some fixed time period. SFF dynamically updates system parameters such as start time and throttle rate depending on historical ad-campaign data. SFF is currently in use at DoorDash, one of the largest delivery platforms in the US, and is part of its budget pacing system. We show via online budget-split experimentation data and offline simulations that SFF is a robust solution for overdelivery mitigation when pacing budget.
Reinforcement Unlearning
Dec 26, 2023



Machine unlearning refers to the process of mitigating the influence of specific training data on machine learning models based on removal requests from data owners. However, one important area that has been largely overlooked in the research of unlearning is reinforcement learning. Reinforcement learning focuses on training an agent to make optimal decisions within an environment to maximize its cumulative rewards. During the training, the agent tends to memorize the features of the environment, which raises a significant concern about privacy. As per data protection regulations, the owner of the environment holds the right to revoke access to the agent's training data, thus necessitating the development of a novel and pressing research field, known as \emph{reinforcement unlearning}. Reinforcement unlearning focuses on revoking entire environments rather than individual data samples. This unique characteristic presents three distinct challenges: 1) how to propose unlearning schemes for environments; 2) how to avoid degrading the agent's performance in remaining environments; and 3) how to evaluate the effectiveness of unlearning. To tackle these challenges, we propose two reinforcement unlearning methods. The first method is based on decremental reinforcement learning, which aims to erase the agent's previously acquired knowledge gradually. The second method leverages environment poisoning attacks, which encourage the agent to learn new, albeit incorrect, knowledge to remove the unlearning environment. Particularly, to tackle the third challenge, we introduce the concept of ``environment inference attack'' to evaluate the unlearning outcomes. The source code is available at \url{https://anonymous.4open.science/r/Reinforcement-Unlearning-D347}.
GAN based Data Augmentation to Resolve Class Imbalance
Jun 12, 2022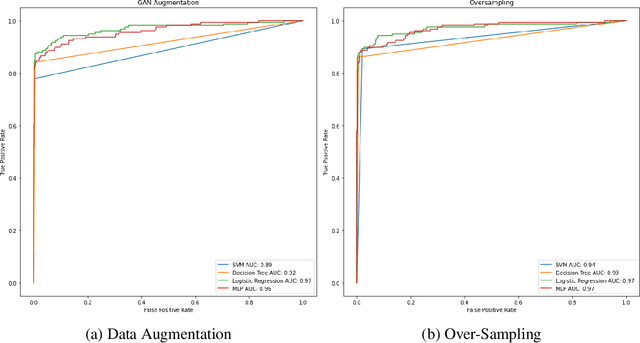
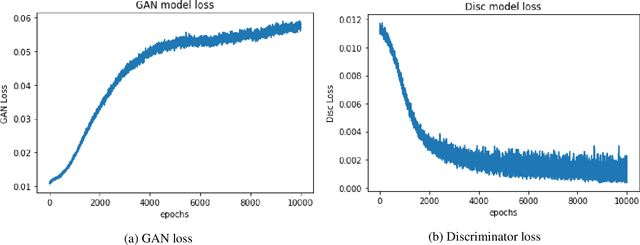

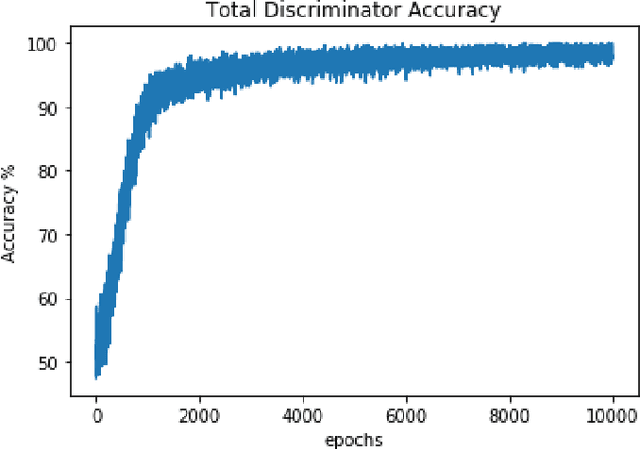
The number of credit card fraud has been growing as technology grows and people can take advantage of it. Therefore, it is very important to implement a robust and effective method to detect such frauds. The machine learning algorithms are appropriate for these tasks since they try to maximize the accuracy of predictions and hence can be relied upon. However, there is an impending flaw where in machine learning models may not perform well due to the presence of an imbalance across classes distribution within the sample set. So, in many related tasks, the datasets have a very small number of observed fraud cases (sometimes around 1 percent positive fraud instances found). Therefore, this imbalance presence may impact any learning model's behavior by predicting all labels as the majority class, hence allowing no scope for generalization in the predictions made by the model. We trained Generative Adversarial Network(GAN) to generate a large number of convincing (and reliable) synthetic examples of the minority class that can be used to alleviate the class imbalance within the training set and hence generalize the learning of the data more effectively.
Deep Reinforcement Learning for Personalized Search Story Recommendation
Jul 26, 2019
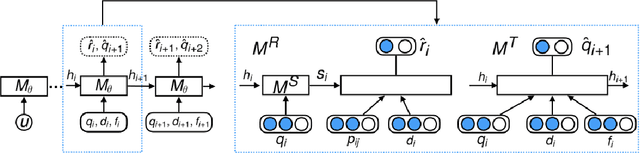
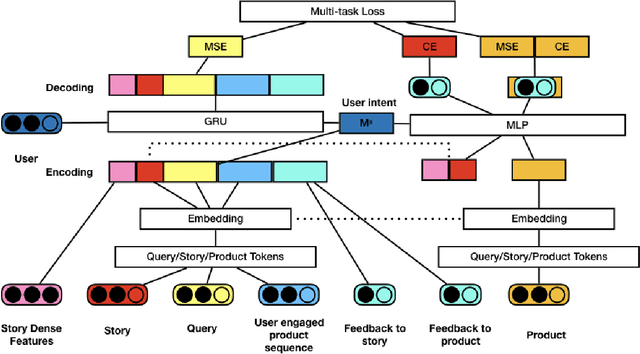
In recent years, \emph{search story}, a combined display with other organic channels, has become a major source of user traffic on platforms such as e-commerce search platforms, news feed platforms and web and image search platforms. The recommended search story guides a user to identify her own preference and personal intent, which subsequently influences the user's real-time and long-term search behavior. %With such an increased importance of search stories, As search stories become increasingly important, in this work, we study the problem of personalized search story recommendation within a search engine, which aims to suggest a search story relevant to both a search keyword and an individual user's interest. To address the challenge of modeling both immediate and future values of recommended search stories (i.e., cross-channel effect), for which conventional supervised learning framework is not applicable, we resort to a Markov decision process and propose a deep reinforcement learning architecture trained by both imitation learning and reinforcement learning. We empirically demonstrate the effectiveness of our proposed approach through extensive experiments on real-world data sets from JD.com.
Machine Learning Based Detection of Clickbait Posts in Social Media
Oct 05, 2017
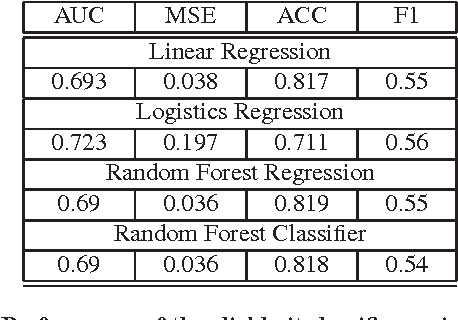
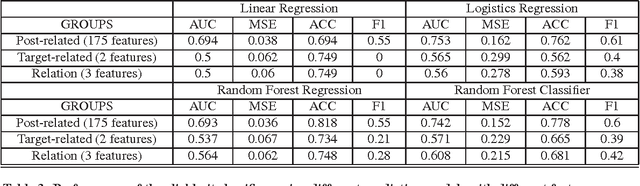

Clickbait (headlines) make use of misleading titles that hide critical information from or exaggerate the content on the landing target pages to entice clicks. As clickbaits often use eye-catching wording to attract viewers, target contents are often of low quality. Clickbaits are especially widespread on social media such as Twitter, adversely impacting user experience by causing immense dissatisfaction. Hence, it has become increasingly important to put forward a widely applicable approach to identify and detect clickbaits. In this paper, we make use of a dataset from the clickbait challenge 2017 (clickbait-challenge.com) comprising of over 21,000 headlines/titles, each of which is annotated by at least five judgments from crowdsourcing on how clickbait it is. We attempt to build an effective computational clickbait detection model on this dataset. We first considered a total of 331 features, filtered out many features to avoid overfitting and improve the running time of learning, and eventually selected the 60 most important features for our final model. Using these features, Random Forest Regression achieved the following results: MSE=0.035 MSE, Accuracy=0.82, and F1-sore=0.61 on the clickbait class.