 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Leakage Defense with Key-Lock Module for Federated Learning
Paper and Code
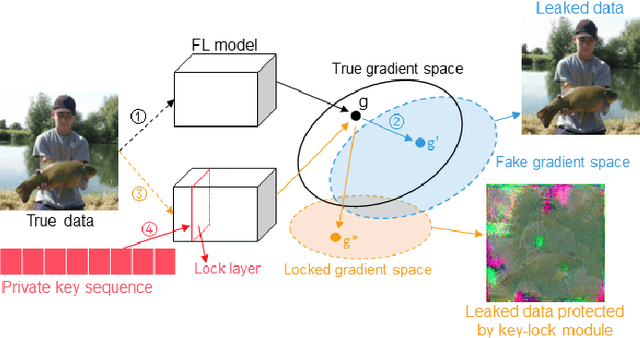

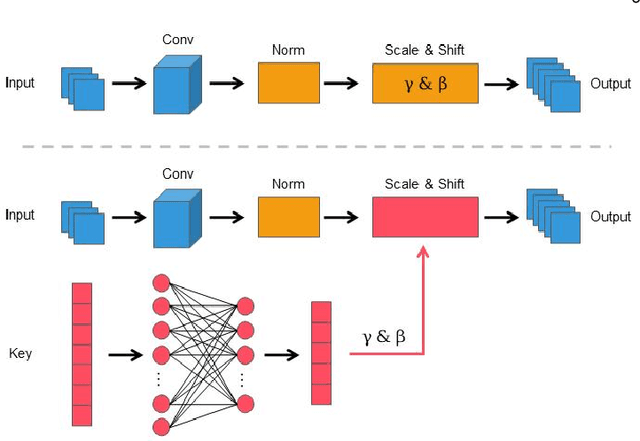
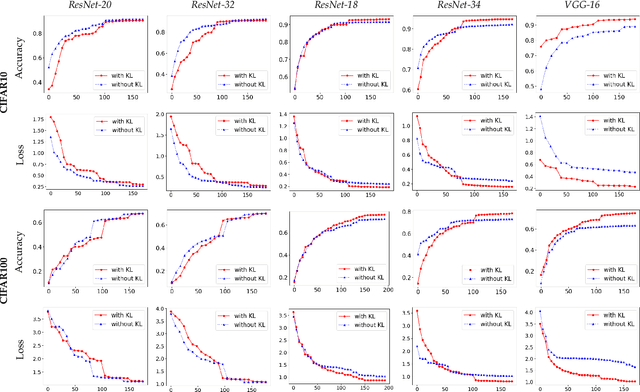
Federated Learning (FL) is a widely adopted privacy-preserving machine learning approach where private data remains local, enabling secure computations and the exchange of local model gradients between local clients and third-party parameter servers. However, recent findings reveal that privacy may be compromised and sensitive information potentially recovered from shared gradients. In this study, we offer detailed analysis and a novel perspective on understanding the gradient leakage problem. These theoretical works lead to a new gradient leakage defense technique that secures arbitrary model architectures using a private key-lock module. Only the locked gradient is transmitted to the parameter server for global model aggregation. Our proposed learning method is resistant to gradient leakage attacks, and the key-lock module is designed and trained to ensure that, without the private information of the key-lock module: a) reconstructing private training data from the shared gradient is infeasible; and b) the global model's inference performance is significantly compromised. We discuss the theoretical underpinnings of why gradients can leak private information and provide theoretical proof of our method's effectiveness. We conducted extensive empirical evaluations with a total of forty-four models on several popular benchmarks, demonstrating the robustness of our proposed approach in both maintaining model performance and defending against gradient leakage attacks.