 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVL-X: Advancing and Accelerating InternVL Series with Efficient Visual Token Compression
Mar 27, 2025Most multimodal large language models (MLLMs) treat visual tokens as "a sequence of text", integrating them with text tokens into a large language model (LLM). However, a great quantity of visual tokens significantly increases the demand for computational resources and time. In this paper, we propose InternVL-X, which outperforms the InternVL model in both performance and efficiency by incorporating three visual token compression methods. First, we propose a novel vision-language projector, PVTC. This component integrates adjacent visual embeddings to form a local query and utilizes the transformed CLS token as a global query, then performs point-to-region cross-attention through these local and global queries to more effectively convert visual features. Second, we present a layer-wise visual token compression module, LVTC, which compresses tokens in the LLM shallow layers and then expands them through upsampling and residual connections in the deeper layers. This significantly enhances the model computational efficiency. Futhermore, we propose an efficient high resolution slicing method, RVTC, which dynamically adjusts the number of visual tokens based on image area or length filtering. RVTC greatly enhances training efficiency with only a slight reduction in performance. By utilizing 20% or fewer visual tokens, InternVL-X achieves state-of-the-art performance on 7 public MLLM benchmarks, and improves the average metric by 2.34% across 12 tasks.
OSKDet: Towards Orientation-sensitive Keypoint Localization for Rotated Object Detection
Apr 18, 2021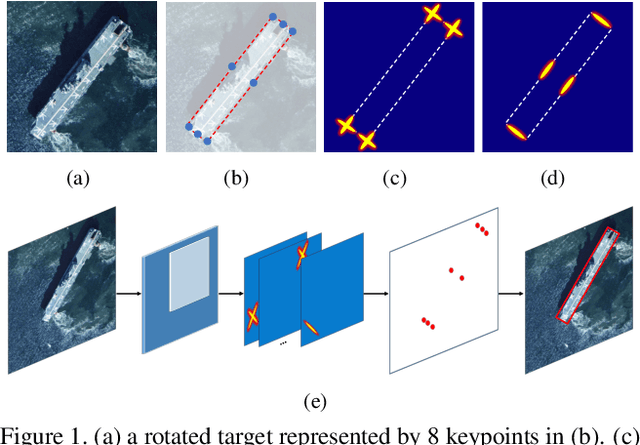

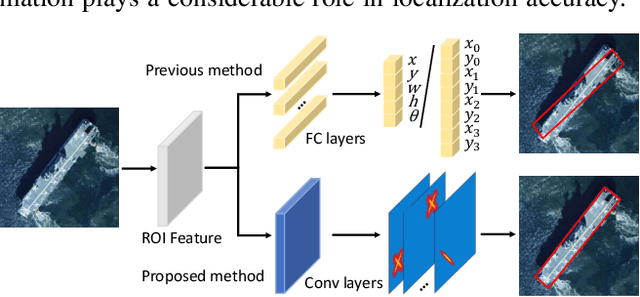

Rotated object detection is a challenging issue of computer vision field. Loss of spatial information and confusion of parametric order have been the bottleneck for rotated detection accuracy. In this paper, we propose an orientation-sensitive keypoint based rotated detector OSKDet. We adopt a set of keypoints to characterize the target and predict the keypoint heatmap on ROI to form a rotated target. By proposing the orientation-sensitive heatmap, OSKDet could learn the shape and direction of rotated target implicitly and has stronger modeling capabilities for target representation, which improves the localization accuracy and acquires high quality detection results. To extract highly effective features at border areas, we design a rotation-aware deformable convolution module. Furthermore, we explore a new keypoint reorder algorithm and feature fusion module based on the angle distribution to eliminate the confusion of keypoint order. Experimental results on several public benchmarks show the state-of-the-art performance of OSKDet. Specifically, we achieve an AP of 77.81% on DOTA, 89.91% on HRSC2016, and 97.18% on UCAS-AOD, respectively.