 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAMMS: Graph based Adversarial Multiagent Modeling Simulator
Feb 04, 2026As intelligent systems and multi-agent coordination become increasingly central to real-world applications, there is a growing need for simulation tools that are both scalable and accessible. Existing high-fidelity simulators, while powerful, are often computationally expensive and ill-suited for rapid prototyping or large-scale agent deployments. We present GAMMS (Graph based Adversarial Multiagent Modeling Simulator), a lightweight yet extensible simulation framework designed to support fast development and evaluation of agent behavior in environments that can be represented as graphs. GAMMS emphasizes five core objectives: scalability, ease of use, integration-first architecture, fast visualization feedback, and real-world grounding. It enables efficient simulation of complex domains such as urban road networks and communication systems, supports integration with external tools (e.g., machine learning libraries, planning solvers), and provides built-in visualization with minimal configuration. GAMMS is agnostic to policy type, supporting heuristic, optimization-based, and learning-based agents, including those using large language models. By lowering the barrier to entry for researchers and enabling high-performance simulations on standard hardware, GAMMS facilitates experimentation and innovation in multi-agent systems, autonomous planning, and adversarial modeling. The framework is open-source and available at https://github.com/GAMMSim/GAMMS/
Transformer IMU Calibrator: Dynamic On-body IMU Calibration for Inertial Motion Capture
Jun 12, 2025In this paper, we propose a novel dynamic calibration method for sparse inertial motion capture systems, which is the first to break the restrictive absolute static assumption in IMU calibration, i.e., the coordinate drift RG'G and measurement offset RBS remain constant during the entire motion, thereby significantly expanding their application scenarios. Specifically, we achieve real-time estimation of RG'G and RBS under two relaxed assumptions: i) the matrices change negligibly in a short time window; ii) the human movements/IMU readings are diverse in such a time window. Intuitively, the first assumption reduces the number of candidate matrices, and the second assumption provides diverse constraints, which greatly reduces the solution space and allows for accurate estimation of RG'G and RBS from a short history of IMU readings in real time. To achieve this, we created synthetic datasets of paired RG'G, RBS matrices and IMU readings, and learned their mappings using a Transformer-based model. We also designed a calibration trigger based on the diversity of IMU readings to ensure that assumption ii) is met before applying our method. To our knowledge, we are the first to achieve implicit IMU calibration (i.e., seamlessly putting IMUs into use without the need for an explicit calibration process), as well as the first to enable long-term and accurate motion capture using sparse IMUs. The code and dataset are available at https://github.com/ZuoCX1996/TIC.
Volumetric Material Decomposition Using Spectral Diffusion Posterior Sampling with a Compressed Polychromatic Forward Model
Mar 28, 2025


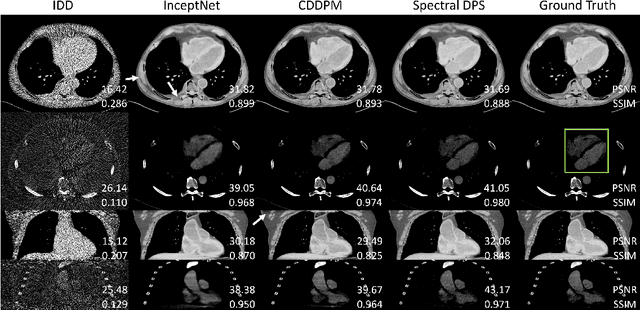
We have previously introduced Spectral Diffusion Posterior Sampling (Spectral DPS) as a framework for accurate one-step material decomposition by integrating analytic spectral system models with priors learned from large datasets. This work extends the 2D Spectral DPS algorithm to 3D by addressing potentially limiting large-memory requirements with a pre-trained 2D diffusion model for slice-by-slice processing and a compressed polychromatic forward model to ensure accurate physical modeling. Simulation studies demonstrate that the proposed memory-efficient 3D Spectral DPS enables material decomposition of clinically significant volume sizes. Quantitative analysis reveals that Spectral DPS outperforms other deep-learning algorithms, such as InceptNet and conditional DDPM in contrast quantification, inter-slice continuity, and resolution preservation. This study establishes a foundation for advancing one-step material decomposition in volumetric spectral CT.
HyperFree: A Channel-adaptive and Tuning-free Foundation Model for Hyperspectral Remote Sensing Imagery
Mar 27, 2025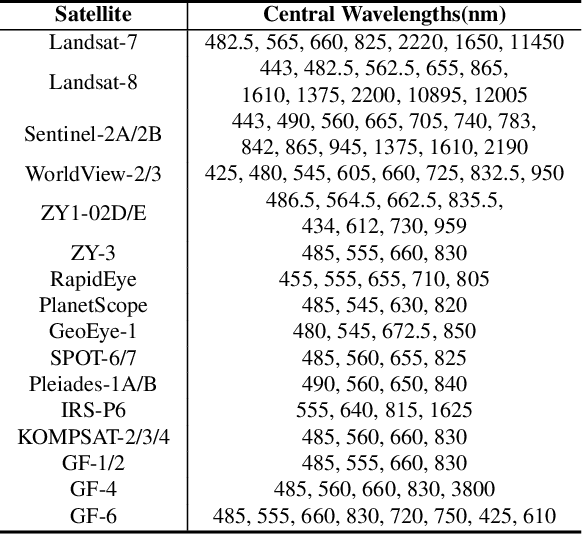
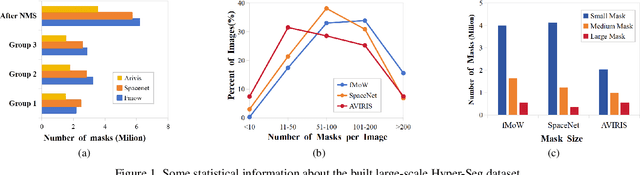
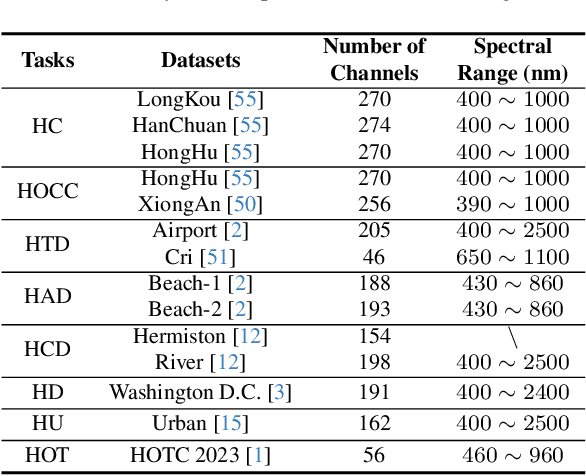
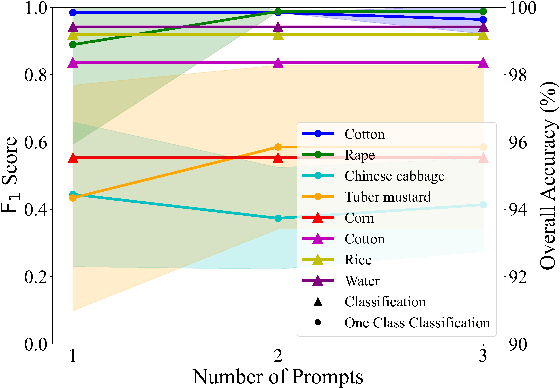
Advanced interpretation of hyperspectral remote sensing images benefits many precise Earth observation tasks. Recently, visual foundation models have promoted the remote sensing interpretation but concentrating on RGB and multispectral images. Due to the varied hyperspectral channels,existing foundation models would face image-by-image tuning situation, imposing great pressure on hardware and time resources. In this paper, we propose a tuning-free hyperspectral foundation model called HyperFree, by adapting the existing visual prompt engineering. To process varied channel numbers, we design a learned weight dictionary covering full-spectrum from $0.4 \sim 2.5 \, \mu\text{m}$, supporting to build the embedding layer dynamically. To make the prompt design more tractable, HyperFree can generate multiple semantic-aware masks for one prompt by treating feature distance as semantic-similarity. After pre-training HyperFree on constructed large-scale high-resolution hyperspectral images, HyperFree (1 prompt) has shown comparable results with specialized models (5 shots) on 5 tasks and 11 datasets.Code and dataset are accessible at https://rsidea.whu.edu.cn/hyperfree.htm.
CTorch: PyTorch-Compatible GPU-Accelerated Auto-Differentiable Projector Toolbox for Computed Tomography
Mar 20, 2025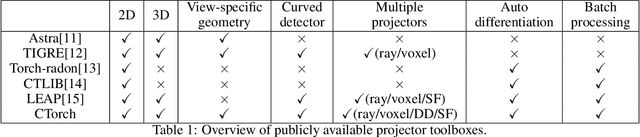

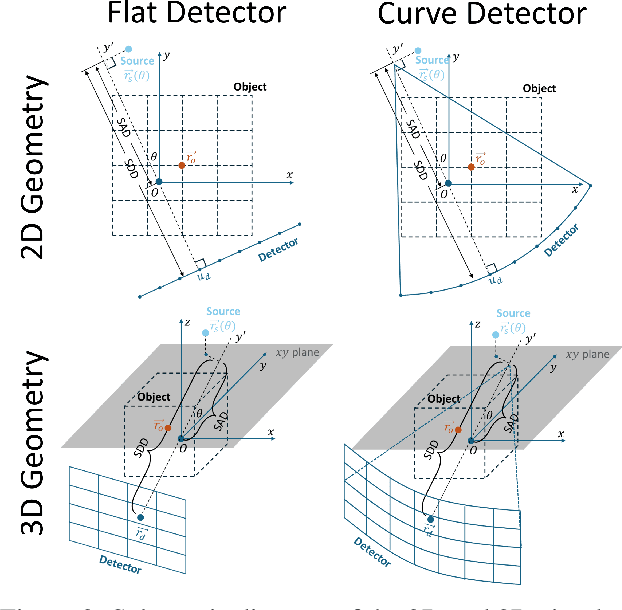
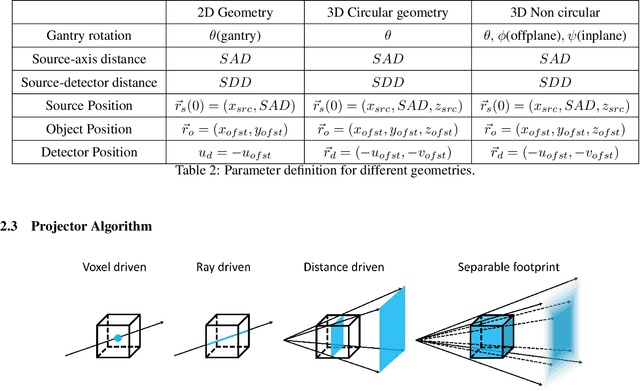
This work introduces CTorch, a PyTorch-compatible, GPU-accelerated, and auto-differentiable projector toolbox designed to handle various CT geometries with configurable projector algorithms. CTorch provides flexible scanner geometry definition, supporting 2D fan-beam, 3D circular cone-beam, and 3D non-circular cone-beam geometries. Each geometry allows view-specific definitions to accommodate variations during scanning. Both flat- and curved-detector models may be specified to accommodate various clinical devices. CTorch implements four projector algorithms: voxel-driven, ray-driven, distance-driven (DD), and separable footprint (SF), allowing users to balance accuracy and computational efficiency based on their needs. All the projectors are primarily built using CUDA C for GPU acceleration, then compiled as Python-callable functions, and wrapped as PyTorch network module. This design allows direct use of PyTorch tensors, enabling seamless integration into PyTorch's auto-differentiation framework. These features make CTorch an flexible and efficient tool for CT imaging research, with potential applications in accurate CT simulations, efficient iterative reconstruction, and advanced deep-learning-based CT reconstruction.
ADV2E: Bridging the Gap Between Analogue Circuit and Discrete Frames in the Video-to-Events Simulator
Nov 19, 2024



Event cameras operate fundamentally differently from traditional Active Pixel Sensor (APS) cameras, offering significant advantages. Recent research has developed simulators to convert video frames into events, addressing the shortage of real event datasets. Current simulators primarily focus on the logical behavior of event cameras. However, the fundamental analogue properties of pixel circuits are seldom considered in simulator design. The gap between analogue pixel circuit and discrete video frames causes the degeneration of synthetic events, particularly in high-contrast scenes. In this paper, we propose a novel method of generating reliable event data based on a detailed analysis of the pixel circuitry in event cameras. We incorporate the analogue properties of event camera pixel circuits into the simulator design: (1) analogue filtering of signals from light intensity to events, and (2) a cutoff frequency that is independent of video frame rate. Experimental results on two relevant tasks, including semantic segmentation and image reconstruction, validate the reliability of simulated event data, even in high-contrast scenes. This demonstrates that deep neural networks exhibit strong generalization from simulated to real event data, confirming that the synthetic events generated by the proposed method are both realistic and well-suited for effective training.
Strategies for CT Reconstruction using Diffusion Posterior Sampling with a Nonlinear Model
Jul 17, 2024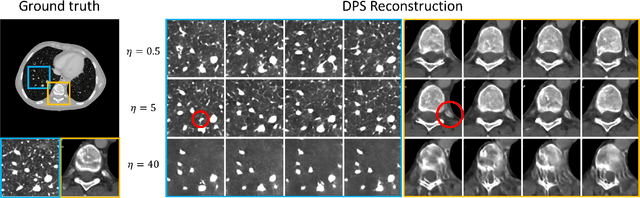
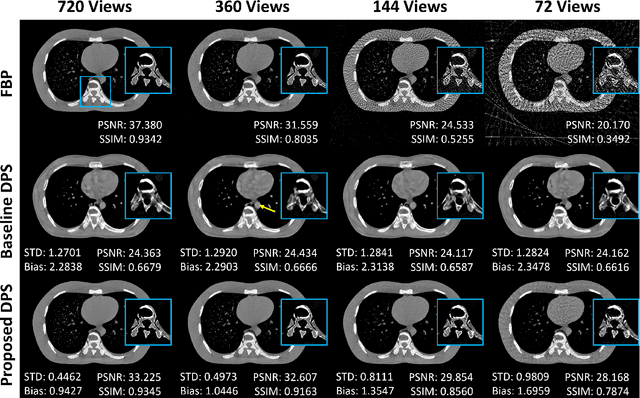
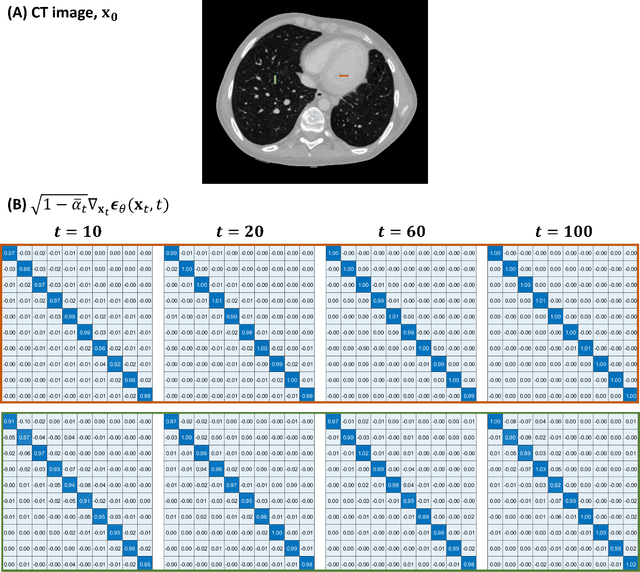
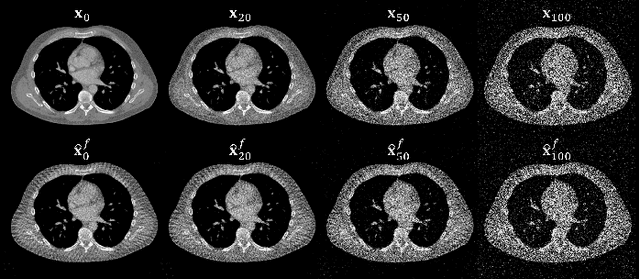
Diffusion Posterior Sampling(DPS) methodology is a novel framework that permits nonlinear CT reconstruction by integrating a diffusion prior and an analytic physical system model, allowing for one-time training for different applications. However, baseline DPS can struggle with large variability, hallucinations, and slow reconstruction. This work introduces a number of strategies designed to enhance the stability and efficiency of DPS CT reconstruction. Specifically, jumpstart sampling allows one to skip many reverse time steps, significantly reducing the reconstruction time as well as the sampling variability. Additionally, the likelihood update is modified to simplify the Jacobian computation and improve data consistency more efficiently. Finally, a hyperparameter sweep is conducted to investigate the effects of parameter tuning and to optimize the overall reconstruction performance. Simulation studies demonstrated that the proposed DPS technique achieves up to 46.72% PSNR and 51.50% SSIM enhancement in a low-mAs setting, and an over 31.43% variability reduction in a sparse-view setting. Moreover, reconstruction time is sped up from >23.5 s/slice to <1.5 s/slice. In a physical data study, the proposed DPS exhibits robustness on an anthropomorphic phantom reconstruction which does not strictly follow the prior distribution. Quantitative analysis demonstrates that the proposed DPS can accommodate various dose levels and number of views. With 10% dose, only a 5.60% and 4.84% reduction of PSNR and SSIM was observed for the proposed approach. Both simulation and phantom studies demonstrate that the proposed method can significantly improve reconstruction accuracy and reduce computational costs, greatly enhancing the practicality of DPS CT reconstruction.
Characterization of dim light response in DVS pixel: Discontinuity of event triggering time
Apr 30, 2024Dynamic Vision Sensors (DVS) have recently generated great interest because of the advantages of wide dynamic range and low latency compared with conventional frame-based cameras. However, the complicated behaviors in dim light conditions are still not clear, restricting the applications of DVS. In this paper, we analyze the typical DVS circuit, and find that there exists discontinuity of event triggering time. In dim light conditions, the discontinuity becomes prominent. We point out that the discontinuity depends exclusively on the changing speed of light intensity. Experimental results on real event data validate the analysis and the existence of discontinuity that reveals the non-first-order behaviors of DVS in dim light conditions.
CT Material Decomposition using Spectral Diffusion Posterior Sampling
Feb 05, 2024



In this work, we introduce a new deep learning approach based on diffusion posterior sampling (DPS) to perform material decomposition from spectral CT measurements. This approach combines sophisticated prior knowledge from unsupervised training with a rigorous physical model of the measurements. A faster and more stable variant is proposed that uses a jumpstarted process to reduce the number of time steps required in the reverse process and a gradient approximation to reduce the computational cost. Performance is investigated for two spectral CT systems: dual-kVp and dual-layer detector CT. On both systems, DPS achieves high Structure Similarity Index Metric Measure(SSIM) with only 10% of iterations as used in the model-based material decomposition(MBMD). Jumpstarted DPS (JSDPS) further reduces computational time by over 85% and achieves the highest accuracy, the lowest uncertainty, and the lowest computational costs compared to classic DPS and MBMD. The results demonstrate the potential of JSDPS for providing relatively fast and accurate material decomposition based on spectral CT data.
HybridGazeNet: Geometric model guided Convolutional Neural Networks for gaze estimation
Nov 23, 2021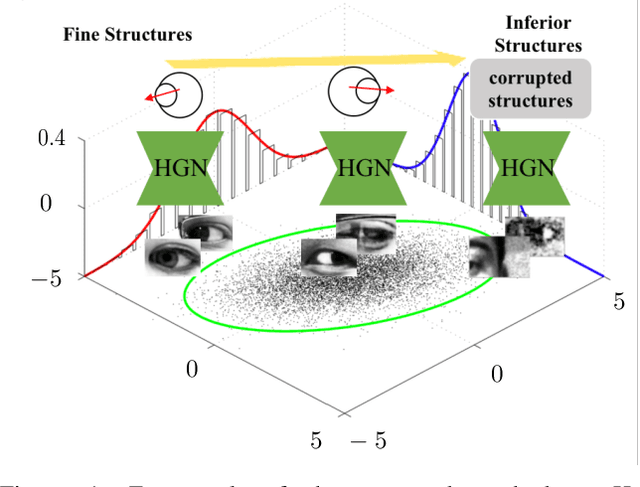

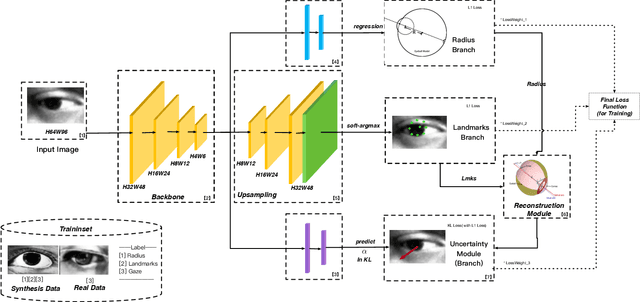
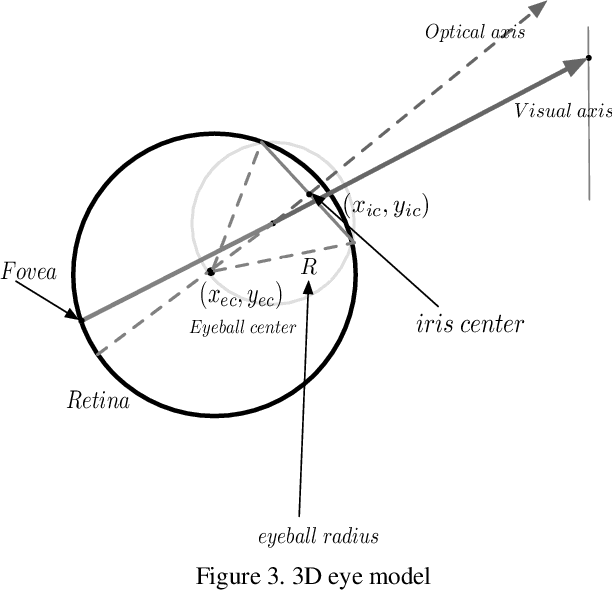
As a critical cue for understanding human intention, human gaze provides a key signal for Human-Computer Interaction(HCI) applications. Appearance-based gaze estimation, which directly regresses the gaze vector from eye images, has made great progress recently based on Convolutional Neural Networks(ConvNets) architecture and open-source large-scale gaze datasets. However, encoding model-based knowledge into CNN model to further improve the gaze estimation performance remains a topic that needs to be explored. In this paper, we propose HybridGazeNet(HGN), a unified framework that encodes the geometric eyeball model into the appearance-based CNN architecture explicitly. Composed of a multi-branch network and an uncertainty module, HybridGazeNet is trained using a hyridized strategy. Experiments on multiple challenging gaze datasets shows that HybridGazeNet has better accuracy and generalization ability compared with existing SOTA methods. The code will be released later.