 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridGazeNet: Geometric model guided Convolutional Neural Networks for gaze estimation
Paper and Code
Nov 23, 2021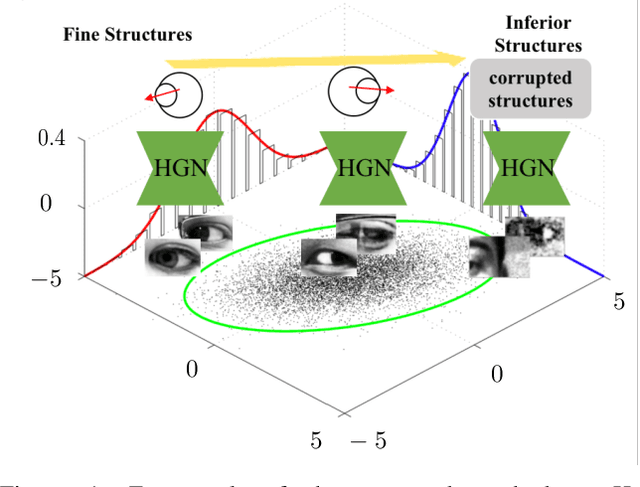

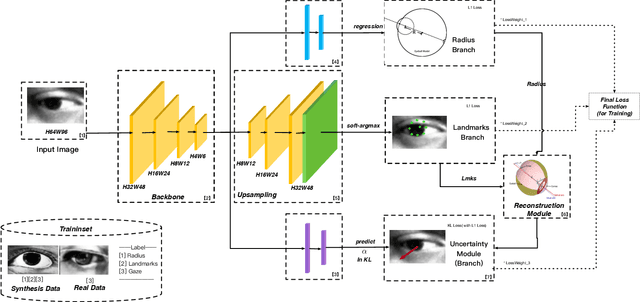
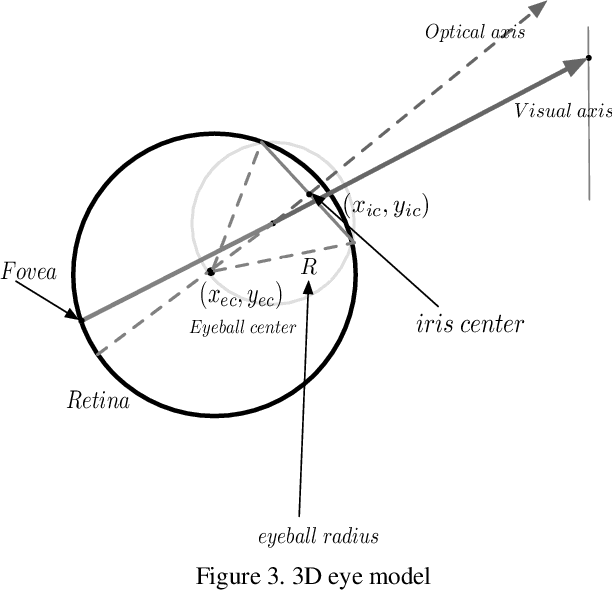
As a critical cue for understanding human intention, human gaze provides a key signal for Human-Computer Interaction(HCI) applications. Appearance-based gaze estimation, which directly regresses the gaze vector from eye images, has made great progress recently based on Convolutional Neural Networks(ConvNets) architecture and open-source large-scale gaze datasets. However, encoding model-based knowledge into CNN model to further improve the gaze estimation performance remains a topic that needs to be explored. In this paper, we propose HybridGazeNet(HGN), a unified framework that encodes the geometric eyeball model into the appearance-based CNN architecture explicitly. Composed of a multi-branch network and an uncertainty module, HybridGazeNet is trained using a hyridized strategy. Experiments on multiple challenging gaze datasets shows that HybridGazeNet has better accuracy and generalization ability compared with existing SOTA methods. The code will be released later.