 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesh-Learner: Texturing Mesh with Spherical Harmonics
Apr 28, 2025In this paper, we present a 3D reconstruction and rendering framework termed Mesh-Learner that is natively compatible with traditional rasterization pipelines. It integrates mesh and spherical harmonic (SH) texture (i.e., texture filled with SH coefficients) into the learning process to learn each mesh s view-dependent radiance end-to-end. Images are rendered by interpolating surrounding SH Texels at each pixel s sampling point using a novel interpolation method. Conversely, gradients from each pixel are back-propagated to the related SH Texels in SH textures. Mesh-Learner exploits graphic features of rasterization pipeline (texture sampling, deferred rendering) to render, which makes Mesh-Learner naturally compatible with tools (e.g., Blender) and tasks (e.g., 3D reconstruction, scene rendering, reinforcement learning for robotics) that are based on rasterization pipelines. Our system can train vast, unlimited scenes because we transfer only the SH textures within the frustum to the GPU for training. At other times, the SH textures are stored in CPU RAM, which results in moderate GPU memory usage. The rendering results on interpolation and extrapolation sequences in the Replica and FAST-LIVO2 datasets achieve state-of-the-art performance compared to existing state-of-the-art methods (e.g., 3D Gaussian Splatting and M2-Mapping). To benefit the society, the code will be available at https://github.com/hku-mars/Mesh-Learner.
Efficient Swept Volume-Based Trajectory Generation for Arbitrary-Shaped Ground Robot Navigation
Apr 10, 2025Navigating an arbitrary-shaped ground robot safely in cluttered environments remains a challenging problem. The existing trajectory planners that account for the robot's physical geometry severely suffer from the intractable runtime. To achieve both computational efficiency and Continuous Collision Avoidance (CCA) of arbitrary-shaped ground robot planning, we proposed a novel coarse-to-fine navigation framework that significantly accelerates planning. In the first stage, a sampling-based method selectively generates distinct topological paths that guarantee a minimum inflated margin. In the second stage, a geometry-aware front-end strategy is designed to discretize these topologies into full-state robot motion sequences while concurrently partitioning the paths into SE(2) sub-problems and simpler R2 sub-problems for back-end optimization. In the final stage, an SVSDF-based optimizer generates trajectories tailored to these sub-problems and seamlessly splices them into a continuous final motion plan. Extensive benchmark comparisons show that the proposed method is one to several orders of magnitude faster than the cutting-edge methods in runtime while maintaining a high planning success rate and ensuring CCA.
GS-SDF: LiDAR-Augmented Gaussian Splatting and Neural SDF for Geometrically Consistent Rendering and Reconstruction
Mar 13, 2025Digital twins are fundamental to the development of autonomous driving and embodied artificial intelligence. However, achieving high-granularity surface reconstruction and high-fidelity rendering remains a challenge. Gaussian splatting offers efficient photorealistic rendering but struggles with geometric inconsistencies due to fragmented primitives and sparse observational data in robotics applications. Existing regularization methods, which rely on render-derived constraints, often fail in complex environments. Moreover, effectively integrating sparse LiDAR data with Gaussian splatting remains challenging. We propose a unified LiDAR-visual system that synergizes Gaussian splatting with a neural signed distance field. The accurate LiDAR point clouds enable a trained neural signed distance field to offer a manifold geometry field, This motivates us to offer an SDF-based Gaussian initialization for physically grounded primitive placement and a comprehensive geometric regularization for geometrically consistent rendering and reconstruction. Experiments demonstrate superior reconstruction accuracy and rendering quality across diverse trajectories. To benefit the community, the codes will be released at https://github.com/hku-mars/GS-SDF.
VSC-RL: Advancing Autonomous Vision-Language Agents with Variational Subgoal-Conditioned Reinforcement Learning
Feb 11, 2025State-of-the-art (SOTA) reinforcement learning (RL) methods enable the vision-language agents to learn from interactions with the environment without human supervision. However, they struggle with learning inefficiencies in tackling real-world complex sequential decision-making tasks, especially with sparse reward signals and long-horizon dependencies. To effectively address the issue, we introduce Variational Subgoal-Conditioned RL (VSC-RL), which reformulates the vision-language sequential decision-making task as a variational goal-conditioned RL problem, allowing us to leverage advanced optimization methods to enhance learning efficiency. Specifically, VSC-RL optimizes the SubGoal Evidence Lower BOund (SGC-ELBO), which consists of (a) maximizing the subgoal-conditioned return via RL and (b) minimizing the subgoal-conditioned difference with the reference policy. We theoretically demonstrate that SGC-ELBO is equivalent to the original optimization objective, ensuring improved learning efficiency without sacrificing performance guarantees. Additionally, for real-world complex decision-making tasks, VSC-RL leverages the vision-language model to autonomously decompose the goal into feasible subgoals, enabling efficient learning. Across various benchmarks, including challenging real-world mobile device control tasks, VSC-RL significantly outperforms the SOTA vision-language agents, achieving superior performance and remarkable improvement in learning efficiency.
OCMDP: Observation-Constrained Markov Decision Process
Nov 12, 2024In many practical applications, decision-making processes must balance the costs of acquiring information with the benefits it provides. Traditional control systems often assume full observability, an unrealistic assumption when observations are expensive. We tackle the challenge of simultaneously learning observation and control strategies in such cost-sensitive environments by introducing the Observation-Constrained Markov Decision Process (OCMDP), where the policy influences the observability of the true state. To manage the complexity arising from the combined observation and control actions, we develop an iterative, model-free deep reinforcement learning algorithm that separates the sensing and control components of the policy. This decomposition enables efficient learning in the expanded action space by focusing on when and what to observe, as well as determining optimal control actions, without requiring knowledge of the environment's dynamics. We validate our approach on a simulated diagnostic task and a realistic healthcare environment using HeartPole. Given both scenarios, the experimental results demonstrate that our model achieves a substantial reduction in observation costs on average, significantly outperforming baseline methods by a notable margin in efficiency.
Detect an Object At Once without Fine-tuning
Nov 04, 2024



When presented with one or a few photos of a previously unseen object, humans can instantly recognize it in different scenes. Although the human brain mechanism behind this phenomenon is still not fully understood, this work introduces a novel technical realization of this task. It consists of two phases: (1) generating a Similarity Density Map (SDM) by convolving the scene image with the given object image patch(es) so that the highlight areas in the SDM indicate the possible locations; (2) obtaining the object occupied areas in the scene through a Region Alignment Network (RAN). The RAN is constructed on a backbone of Deep Siamese Network (DSN), and different from the traditional DSNs, it aims to obtain the object accurate regions by regressing the location and area differences between the ground truths and the predicted ones indicated by the highlight areas in SDM. By pre-learning from labels annotated in traditional datasets, the SDM-RAN can detect previously unknown objects without fine-tuning. Experiments were conducted on the MS COCO, PASCAL VOC datasets. The results indicate that the proposed method outperforms state-of-the-art methods on the same task.
DistRL: An Asynchronous Distributed Reinforcement Learning Framework for On-Device Control Agents
Oct 18, 2024



On-device control agents, especially on mobile devices, are responsible for operating mobile devices to fulfill users' requests, enabling seamless and intuitive interactions. Integrating Multimodal Large Language Models (MLLMs) into these agents enhances their ability to understand and execute complex commands, thereby improving user experience. However, fine-tuning MLLMs for on-device control presents significant challenges due to limited data availability and inefficient online training processes. This paper introduces DistRL, a novel framework designed to enhance the efficiency of online RL fine-tuning for mobile device control agents. DistRL employs centralized training and decentralized data acquisition to ensure efficient fine-tuning in the context of dynamic online interactions. Additionally, the framework is backed by our tailor-made RL algorithm, which effectively balances exploration with the prioritized utilization of collected data to ensure stable and robust training. Our experiments show that, on average, DistRL delivers a 3X improvement in training efficiency and enables training data collection 2.4X faster than the leading synchronous multi-machine methods. Notably, after training, DistRL achieves a 20% relative improvement in success rate compared to state-of-the-art methods on general Android tasks from an open benchmark, significantly outperforming existing approaches while maintaining the same training time. These results validate DistRL as a scalable and efficient solution, offering substantial improvements in both training efficiency and agent performance for real-world, in-the-wild device control tasks.
Neural Surface Reconstruction and Rendering for LiDAR-Visual Systems
Sep 09, 2024



This paper presents a unified surface reconstruction and rendering framework for LiDAR-visual systems, integrating Neural Radiance Fields (NeRF) and Neural Distance Fields (NDF) to recover both appearance and structural information from posed images and point clouds. We address the structural visible gap between NeRF and NDF by utilizing a visible-aware occupancy map to classify space into the free, occupied, visible unknown, and background regions. This classification facilitates the recovery of a complete appearance and structure of the scene. We unify the training of the NDF and NeRF using a spatial-varying scale SDF-to-density transformation for levels of detail for both structure and appearance. The proposed method leverages the learned NDF for structure-aware NeRF training by an adaptive sphere tracing sampling strategy for accurate structure rendering. In return, NeRF further refines structural in recovering missing or fuzzy structures in the NDF. Extensive experiments demonstrate the superior quality and versatility of the proposed method across various scenarios. To benefit the community, the codes will be released at \url{https://github.com/hku-mars/M2Mapping}.
Towards Real-time Scalable Dense Mapping using Robot-centric Implicit Representation
Jun 18, 2023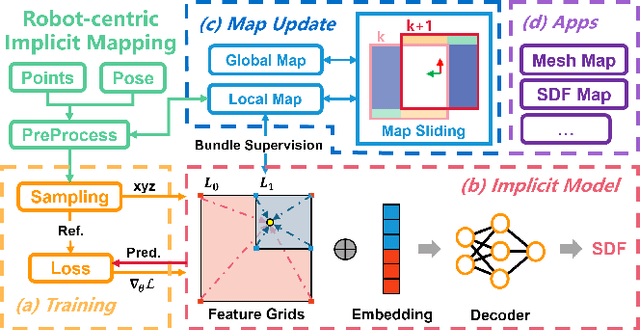



Real-time and high-quailty dense mapping is essential for robots to perform fine tasks. However, most existing methods can not achieve both speed and quality. Recent works have shown that implicit neural representations of 3D scenes can produce remarkable results, but they are limited to small scenes and lack real-time performance. To address these limitations, we propose a real-time scalable mapping method using robot-centric implicit representation. We train implicit features with a multi-resolution local map and decode them as signed distance values through a shallow neural network. We maintain the learned features in a scalable manner using a global map that consists of a hash table and a submap set. We exploit the characteristics of the local map to achieve highly efficient training and mitigate the catastrophic forgetting problem in incremental implicit mapping. Extensive experiments validate that our method outperforms existing methods in reconstruction quality, real-time performance, and applicability. The code of our system will be available at \url{https://github.com/HITSZ-NRSL/RIM.git}.
RGB-D Inertial Odometry for a Resource-Restricted Robot in Dynamic Environments
Apr 21, 2023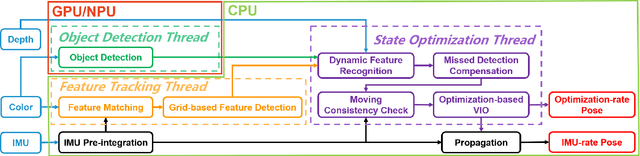

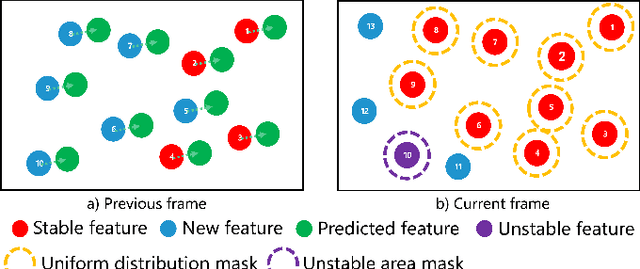
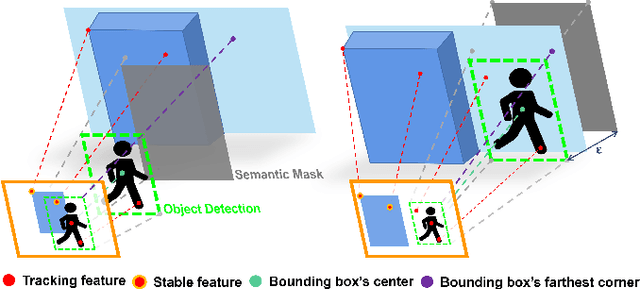
Current simultaneous localization and mapping (SLAM) algorithms perform well in static environments but easily fail in dynamic environments. Recent works introduce deep learning-based semantic information to SLAM systems to reduce the influence of dynamic objects. However, it is still challenging to apply a robust localization in dynamic environments for resource-restricted robots. This paper proposes a real-time RGB-D inertial odometry system for resource-restricted robots in dynamic environments named Dynamic-VINS. Three main threads run in parallel: object detection, feature tracking, and state optimization. The proposed Dynamic-VINS combines object detection and depth information for dynamic feature recognition and achieves performance comparable to semantic segmentation. Dynamic-VINS adopts grid-based feature detection and proposes a fast and efficient method to extract high-quality FAST feature points. IMU is applied to predict motion for feature tracking and moving consistency check. The proposed method is evaluated on both public datasets and real-world applications and shows competitive localization accuracy and robustness in dynamic environments. Yet, to the best of our knowledge, it is the best-performance real-time RGB-D inertial odometry for resource-restricted platforms in dynamic environments for now. The proposed system is open source at: https://github.com/HITSZ-NRSL/Dynamic-VINS.git