 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluAudio: A Comprehensive Benchmark for Hallucination Detection in Large Audio-Language Models
Apr 21, 2026Large Audio-Language Models (LALMs) have recently achieved strong performance across various audio-centric tasks. However, hallucination, where models generate responses that are semantically incorrect or acoustically unsupported, remains largely underexplored in the audio domain. Existing hallucination benchmarks mainly focus on text or vision, while the few audio-oriented studies are limited in scale, modality coverage, and diagnostic depth. We therefore introduce HalluAudio, the first large-scale benchmark for evaluating hallucinations across speech, environmental sound, and music. HalluAudio comprises over 5K human-verified QA pairs and spans diverse task types, including binary judgments, multi-choice reasoning, attribute verification, and open-ended QA. To systematically induce hallucinations, we design adversarial prompts and mixed-audio conditions. Beyond accuracy, our evaluation protocol measures hallucination rate, yes/no bias, error-type analysis, and refusal rate, enabling a fine-grained analysis of LALM failure modes. We benchmark a broad range of open-source and proprietary models, providing the first large-scale comparison across speech, sound, and music. Our results reveal significant deficiencies in acoustic grounding, temporal reasoning, and music attribute understanding, underscoring the need for reliable and robust LALMs.
TIGFlow-GRPO: Trajectory Forecasting via Interaction-Aware Flow Matching and Reward-Driven Optimization
Mar 26, 2026Human trajectory forecasting is important for intelligent multimedia systems operating in visually complex environments, such as autonomous driving and crowd surveillance. Although Conditional Flow Matching (CFM) has shown strong ability in modeling trajectory distributions from spatio-temporal observations, existing approaches still focus primarily on supervised fitting, which may leave social norms and scene constraints insufficiently reflected in generated trajectories. To address this issue, we propose TIGFlow-GRPO, a two-stage generative framework that aligns flow-based trajectory generation with behavioral rules. In the first stage, we build a CFM-based predictor with a Trajectory-Interaction-Graph (TIG) module to model fine-grained visual-spatial interactions and strengthen context encoding. This stage captures both agent-agent and agent-scene relations more effectively, providing more informative conditional features for subsequent alignment. In the second stage, we perform Flow-GRPO post-training,where deterministic flow rollout is reformulated as stochastic ODE-to-SDE sampling to enable trajectory exploration, and a composite reward combines view-aware social compliance with map-aware physical feasibility. By evaluating trajectories explored through SDE rollout, GRPO progressively steers multimodal predictions toward behaviorally plausible futures. Experiments on the ETH/UCY and SDD datasets show that TIGFlow-GRPO improves forecasting accuracy and long-horizon stability while generating trajectories that are more socially compliant and physically feasible. These results suggest that the proposed framework provides an effective way to connect flow-based trajectory modeling with behavior-aware alignment in dynamic multimedia environments.
Whisper-MLA: Reducing GPU Memory Consumption of ASR Models based on MHA2MLA Conversion
Feb 28, 2026The Transformer-based Whisper model has achieved state-of-the-art performance in Automatic Speech Recognition (ASR). However, its Multi-Head Attention (MHA) mechanism results in significant GPU memory consumption due to the linearly growing Key-Value (KV) cache usage, which is problematic for many applications especially with long-form audio. To address this, we introduce Whisper-MLA, a novel architecture that incorporates Multi-Head Latent Attention (MLA) into the Whisper model. Specifically, we adapt MLA for Whisper's absolute positional embeddings and systematically investigate its application across encoder self-attention, decoder self-attention, and cross-attention modules. Empirical results indicate that applying MLA exclusively to decoder self-attention yields the desired balance between performance and memory efficiency. Our proposed approach allows conversion of a pretrained Whisper model to Whisper-MLA with minimal fine-tuning. Extensive experiments on the LibriSpeech benchmark validate the effectiveness of this conversion, demonstrating that Whisper-MLA reduces the KV cache size by up to 87.5% while maintaining competitive accuracy.
SoulX-Singer: Towards High-Quality Zero-Shot Singing Voice Synthesis
Feb 08, 2026While recent years have witnessed rapid progress in speech synthesis, open-source singing voice synthesis (SVS) systems still face significant barriers to industrial deployment, particularly in terms of robustness and zero-shot generalization. In this report, we introduce SoulX-Singer, a high-quality open-source SVS system designed with practical deployment considerations in mind. SoulX-Singer supports controllable singing generation conditioned on either symbolic musical scores (MIDI) or melodic representations, enabling flexible and expressive control in real-world production workflows. Trained on more than 42,000 hours of vocal data, the system supports Mandarin Chinese, English, and Cantonese and consistently achieves state-of-the-art synthesis quality across languages under diverse musical conditions. Furthermore, to enable reliable evaluation of zero-shot SVS performance in practical scenarios, we construct SoulX-Singer-Eval, a dedicated benchmark with strict training-test disentanglement, facilitating systematic assessment in zero-shot settings.
Listening for "You": Enhancing Speech Image Retrieval via Target Speaker Extraction
Sep 11, 2025Image retrieval using spoken language cues has emerged as a promising direction in multimodal perception, yet leveraging speech in multi-speaker scenarios remains challenging. We propose a novel Target Speaker Speech-Image Retrieval task and a framework that learns the relationship between images and multi-speaker speech signals in the presence of a target speaker. Our method integrates pre-trained self-supervised audio encoders with vision models via target speaker-aware contrastive learning, conditioned on a Target Speaker Extraction and Retrieval module. This enables the system to extract spoken commands from the target speaker and align them with corresponding images. Experiments on SpokenCOCO2Mix and SpokenCOCO3Mix show that TSRE significantly outperforms existing methods, achieving 36.3% and 29.9% Recall@1 in 2 and 3 speaker scenarios, respectively - substantial improvements over single speaker baselines and state-of-the-art models. Our approach demonstrates potential for real-world deployment in assistive robotics and multimodal interaction systems.
Detect an Object At Once without Fine-tuning
Nov 04, 2024



When presented with one or a few photos of a previously unseen object, humans can instantly recognize it in different scenes. Although the human brain mechanism behind this phenomenon is still not fully understood, this work introduces a novel technical realization of this task. It consists of two phases: (1) generating a Similarity Density Map (SDM) by convolving the scene image with the given object image patch(es) so that the highlight areas in the SDM indicate the possible locations; (2) obtaining the object occupied areas in the scene through a Region Alignment Network (RAN). The RAN is constructed on a backbone of Deep Siamese Network (DSN), and different from the traditional DSNs, it aims to obtain the object accurate regions by regressing the location and area differences between the ground truths and the predicted ones indicated by the highlight areas in SDM. By pre-learning from labels annotated in traditional datasets, the SDM-RAN can detect previously unknown objects without fine-tuning. Experiments were conducted on the MS COCO, PASCAL VOC datasets. The results indicate that the proposed method outperforms state-of-the-art methods on the same task.
Synergistic Dual Spatial-aware Generation of Image-to-Text and Text-to-Image
Oct 20, 2024



In the visual spatial understanding (VSU) area, spatial image-to-text (SI2T) and spatial text-to-image (ST2I) are two fundamental tasks that appear in dual form. Existing methods for standalone SI2T or ST2I perform imperfectly in spatial understanding, due to the difficulty of 3D-wise spatial feature modeling. In this work, we consider modeling the SI2T and ST2I together under a dual learning framework. During the dual framework, we then propose to represent the 3D spatial scene features with a novel 3D scene graph (3DSG) representation that can be shared and beneficial to both tasks. Further, inspired by the intuition that the easier 3D$\to$image and 3D$\to$text processes also exist symmetrically in the ST2I and SI2T, respectively, we propose the Spatial Dual Discrete Diffusion (SD$^3$) framework, which utilizes the intermediate features of the 3D$\to$X processes to guide the hard X$\to$3D processes, such that the overall ST2I and SI2T will benefit each other. On the visual spatial understanding dataset VSD, our system outperforms the mainstream T2I and I2T methods significantly. Further in-depth analysis reveals how our dual learning strategy advances.
You Only Speak Once to See
Sep 27, 2024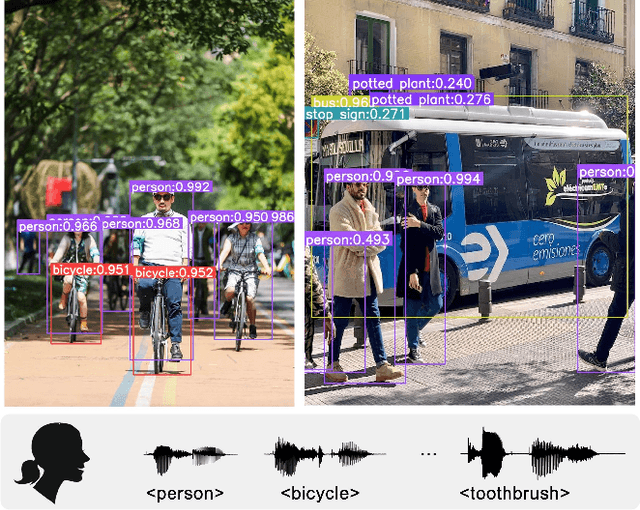
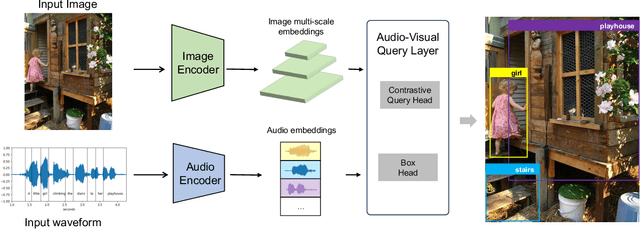
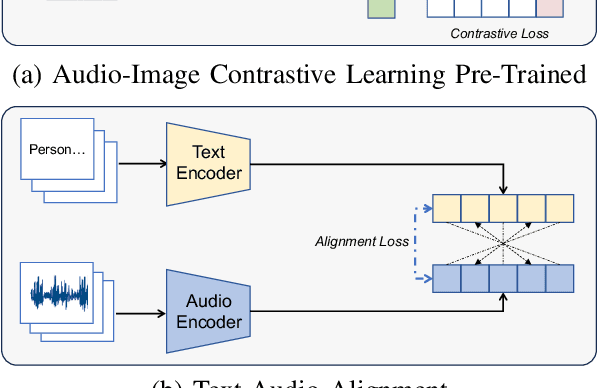
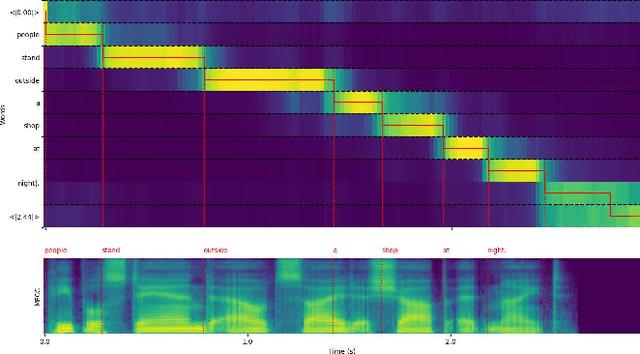
Grounding objects in images using visual cues is a well-established approach in computer vision, yet the potential of audio as a modality for object recognition and grounding remains underexplored. We introduce YOSS, "You Only Speak Once to See," to leverage audio for grounding objects in visual scenes, termed Audio Grounding. By integrating pre-trained audio models with visual models using contrastive learning and multi-modal alignment, our approach captures speech commands or descriptions and maps them directly to corresponding objects within images. Experimental results indicate that audio guidance can be effectively applied to object grounding, suggesting that incorporating audio guidance may enhance the precision and robustness of current object grounding methods and improve the performance of robotic systems and computer vision applications. This finding opens new possibilities for advanced object recognition, scene understanding, and the development of more intuitive and capable robotic systems.
Channel Adaptation for Speaker Verification Using Optimal Transport with Pseudo Label
Sep 14, 2024



Domain gap often degrades the performance of speaker verification (SV) systems when the statistical distributions of training data and real-world test speech are mismatched. Channel variation, a primary factor causing this gap, is less addressed than other issues (e.g., noise). Although various domain adaptation algorithms could be applied to handle this domain gap problem, most algorithms could not take the complex distribution structure in domain alignment with discriminative learning. In this paper, we propose a novel unsupervised domain adaptation method, i.e., Joint Partial Optimal Transport with Pseudo Label (JPOT-PL), to alleviate the channel mismatch problem. Leveraging the geometric-aware distance metric of optimal transport in distribution alignment, we further design a pseudo label-based discriminative learning where the pseudo label can be regarded as a new type of soft speaker label derived from the optimal coupling. With the JPOT-PL, we carry out experiments on the SV channel adaptation task with VoxCeleb as the basis corpus. Experiments show our method reduces EER by over 10% compared with several state-of-the-art channel adaptation algorithms.
Integrated Multi-Level Knowledge Distillation for Enhanced Speaker Verification
Sep 14, 2024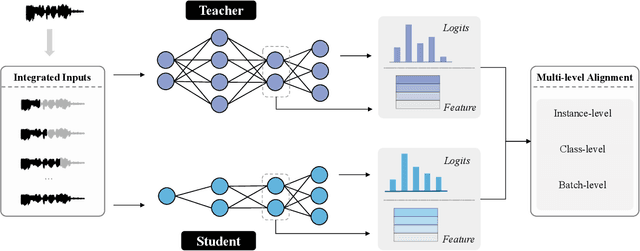
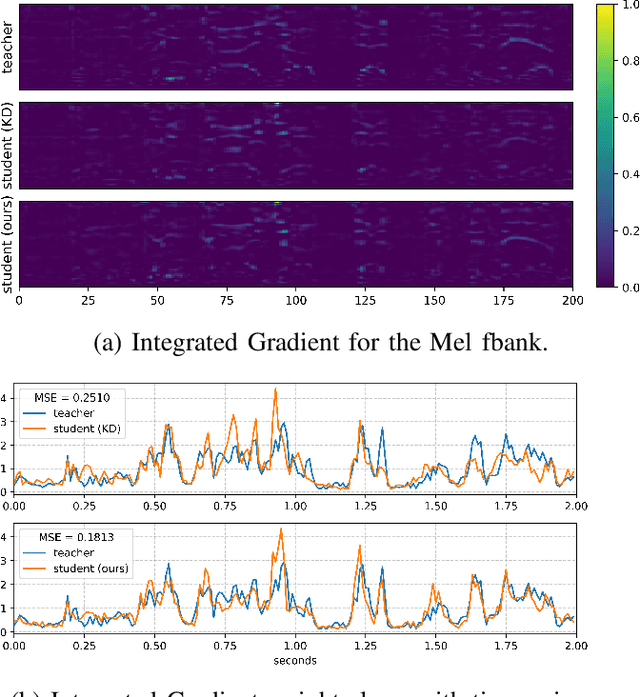

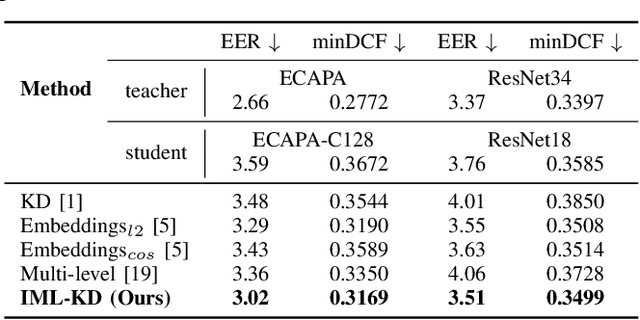
Knowledge distillation (KD) is widely used in audio tasks, such as speaker verification (SV), by transferring knowledge from a well-trained large model (the teacher) to a smaller, more compact model (the student) for efficiency and portability. Existing KD methods for SV often mirror those used in image processing, focusing on approximating predicted probabilities and hidden representations. However, these methods fail to account for the multi-level temporal properties of speech audio. In this paper, we propose a novel KD method, i.e., Integrated Multi-level Knowledge Distillation (IML-KD), to transfer knowledge of various temporal-scale features of speech from a teacher model to a student model. In the IML-KD, temporal context information from the teacher model is integrated into novel Integrated Gradient-based input-sensitive representations from speech segments with various durations, and the student model is trained to infer these representations with multi-level alignment for the output. We conduct SV experiments on the VoxCeleb1 dataset to evaluate the proposed method. Experimental results demonstrate that IML-KD significantly enhances KD performance, reducing the Equal Error Rate (EER) by 5%.