 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Multi-Level Knowledge Distillation for Enhanced Speaker Verification
Paper and Code
Sep 14, 2024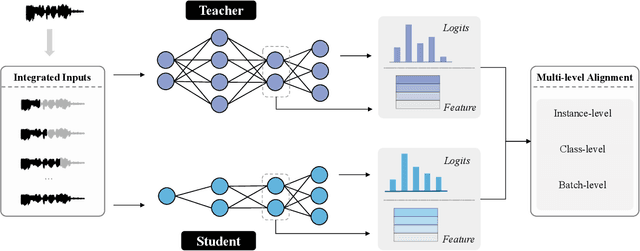
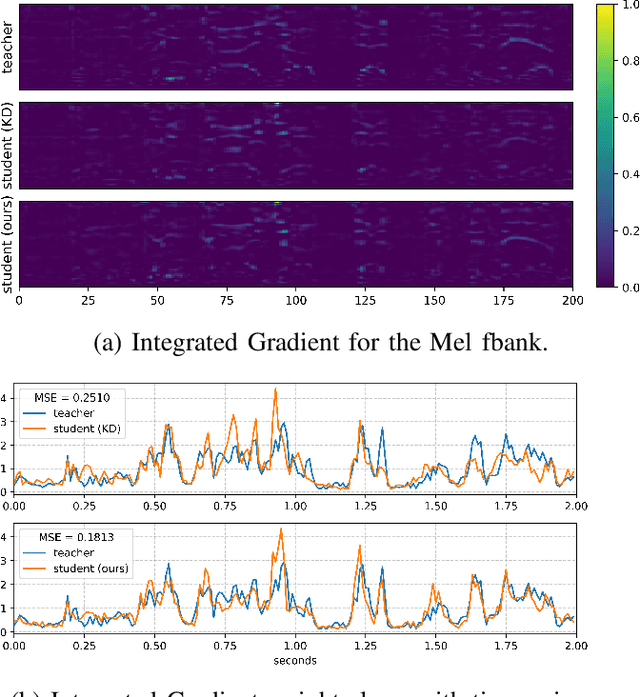

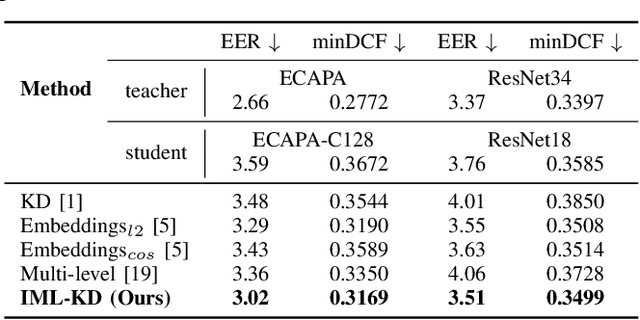
Knowledge distillation (KD) is widely used in audio tasks, such as speaker verification (SV), by transferring knowledge from a well-trained large model (the teacher) to a smaller, more compact model (the student) for efficiency and portability. Existing KD methods for SV often mirror those used in image processing, focusing on approximating predicted probabilities and hidden representations. However, these methods fail to account for the multi-level temporal properties of speech audio. In this paper, we propose a novel KD method, i.e., Integrated Multi-level Knowledge Distillation (IML-KD), to transfer knowledge of various temporal-scale features of speech from a teacher model to a student model. In the IML-KD, temporal context information from the teacher model is integrated into novel Integrated Gradient-based input-sensitive representations from speech segments with various durations, and the student model is trained to infer these representations with multi-level alignment for the output. We conduct SV experiments on the VoxCeleb1 dataset to evaluate the proposed method. Experimental results demonstrate that IML-KD significantly enhances KD performance, reducing the Equal Error Rate (EER) by 5%.