 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluAudio: A Comprehensive Benchmark for Hallucination Detection in Large Audio-Language Models
Apr 21, 2026Large Audio-Language Models (LALMs) have recently achieved strong performance across various audio-centric tasks. However, hallucination, where models generate responses that are semantically incorrect or acoustically unsupported, remains largely underexplored in the audio domain. Existing hallucination benchmarks mainly focus on text or vision, while the few audio-oriented studies are limited in scale, modality coverage, and diagnostic depth. We therefore introduce HalluAudio, the first large-scale benchmark for evaluating hallucinations across speech, environmental sound, and music. HalluAudio comprises over 5K human-verified QA pairs and spans diverse task types, including binary judgments, multi-choice reasoning, attribute verification, and open-ended QA. To systematically induce hallucinations, we design adversarial prompts and mixed-audio conditions. Beyond accuracy, our evaluation protocol measures hallucination rate, yes/no bias, error-type analysis, and refusal rate, enabling a fine-grained analysis of LALM failure modes. We benchmark a broad range of open-source and proprietary models, providing the first large-scale comparison across speech, sound, and music. Our results reveal significant deficiencies in acoustic grounding, temporal reasoning, and music attribute understanding, underscoring the need for reliable and robust LALMs.
TIGFlow-GRPO: Trajectory Forecasting via Interaction-Aware Flow Matching and Reward-Driven Optimization
Mar 26, 2026Human trajectory forecasting is important for intelligent multimedia systems operating in visually complex environments, such as autonomous driving and crowd surveillance. Although Conditional Flow Matching (CFM) has shown strong ability in modeling trajectory distributions from spatio-temporal observations, existing approaches still focus primarily on supervised fitting, which may leave social norms and scene constraints insufficiently reflected in generated trajectories. To address this issue, we propose TIGFlow-GRPO, a two-stage generative framework that aligns flow-based trajectory generation with behavioral rules. In the first stage, we build a CFM-based predictor with a Trajectory-Interaction-Graph (TIG) module to model fine-grained visual-spatial interactions and strengthen context encoding. This stage captures both agent-agent and agent-scene relations more effectively, providing more informative conditional features for subsequent alignment. In the second stage, we perform Flow-GRPO post-training,where deterministic flow rollout is reformulated as stochastic ODE-to-SDE sampling to enable trajectory exploration, and a composite reward combines view-aware social compliance with map-aware physical feasibility. By evaluating trajectories explored through SDE rollout, GRPO progressively steers multimodal predictions toward behaviorally plausible futures. Experiments on the ETH/UCY and SDD datasets show that TIGFlow-GRPO improves forecasting accuracy and long-horizon stability while generating trajectories that are more socially compliant and physically feasible. These results suggest that the proposed framework provides an effective way to connect flow-based trajectory modeling with behavior-aware alignment in dynamic multimedia environments.
Whisper-MLA: Reducing GPU Memory Consumption of ASR Models based on MHA2MLA Conversion
Feb 28, 2026The Transformer-based Whisper model has achieved state-of-the-art performance in Automatic Speech Recognition (ASR). However, its Multi-Head Attention (MHA) mechanism results in significant GPU memory consumption due to the linearly growing Key-Value (KV) cache usage, which is problematic for many applications especially with long-form audio. To address this, we introduce Whisper-MLA, a novel architecture that incorporates Multi-Head Latent Attention (MLA) into the Whisper model. Specifically, we adapt MLA for Whisper's absolute positional embeddings and systematically investigate its application across encoder self-attention, decoder self-attention, and cross-attention modules. Empirical results indicate that applying MLA exclusively to decoder self-attention yields the desired balance between performance and memory efficiency. Our proposed approach allows conversion of a pretrained Whisper model to Whisper-MLA with minimal fine-tuning. Extensive experiments on the LibriSpeech benchmark validate the effectiveness of this conversion, demonstrating that Whisper-MLA reduces the KV cache size by up to 87.5% while maintaining competitive accuracy.
Listening for "You": Enhancing Speech Image Retrieval via Target Speaker Extraction
Sep 11, 2025Image retrieval using spoken language cues has emerged as a promising direction in multimodal perception, yet leveraging speech in multi-speaker scenarios remains challenging. We propose a novel Target Speaker Speech-Image Retrieval task and a framework that learns the relationship between images and multi-speaker speech signals in the presence of a target speaker. Our method integrates pre-trained self-supervised audio encoders with vision models via target speaker-aware contrastive learning, conditioned on a Target Speaker Extraction and Retrieval module. This enables the system to extract spoken commands from the target speaker and align them with corresponding images. Experiments on SpokenCOCO2Mix and SpokenCOCO3Mix show that TSRE significantly outperforms existing methods, achieving 36.3% and 29.9% Recall@1 in 2 and 3 speaker scenarios, respectively - substantial improvements over single speaker baselines and state-of-the-art models. Our approach demonstrates potential for real-world deployment in assistive robotics and multimodal interaction systems.
You Only Speak Once to See
Sep 27, 2024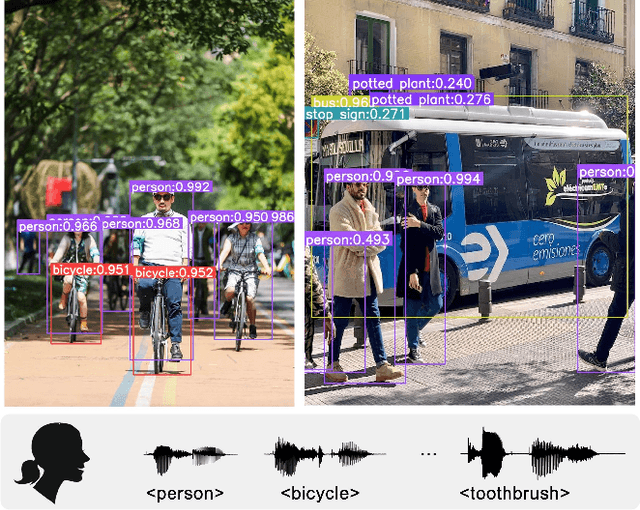
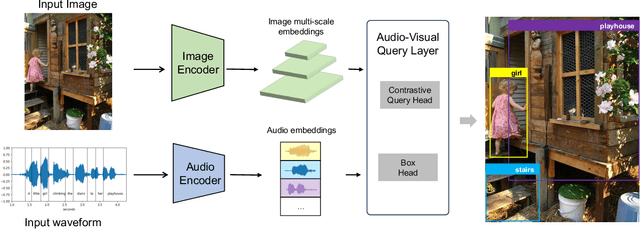
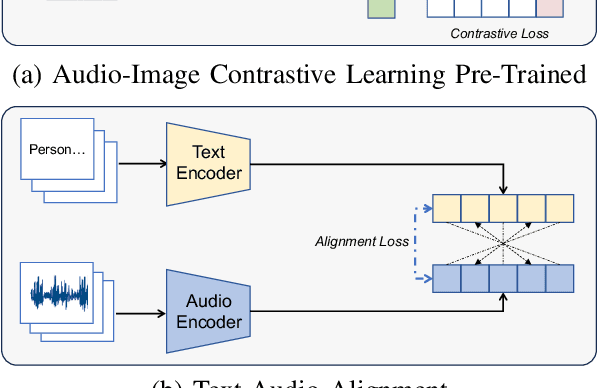
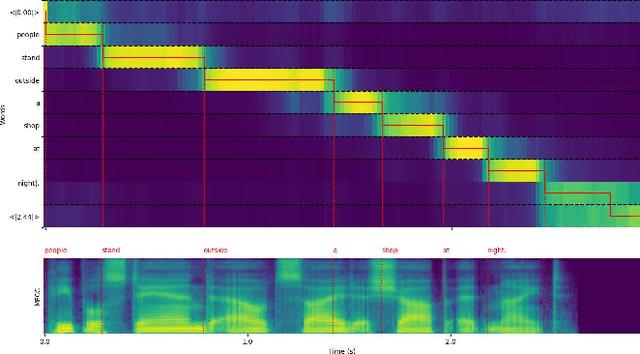
Grounding objects in images using visual cues is a well-established approach in computer vision, yet the potential of audio as a modality for object recognition and grounding remains underexplored. We introduce YOSS, "You Only Speak Once to See," to leverage audio for grounding objects in visual scenes, termed Audio Grounding. By integrating pre-trained audio models with visual models using contrastive learning and multi-modal alignment, our approach captures speech commands or descriptions and maps them directly to corresponding objects within images. Experimental results indicate that audio guidance can be effectively applied to object grounding, suggesting that incorporating audio guidance may enhance the precision and robustness of current object grounding methods and improve the performance of robotic systems and computer vision applications. This finding opens new possibilities for advanced object recognition, scene understanding, and the development of more intuitive and capable robotic systems.
Integrated Multi-Level Knowledge Distillation for Enhanced Speaker Verification
Sep 14, 2024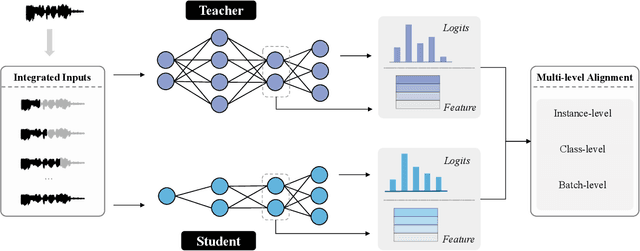
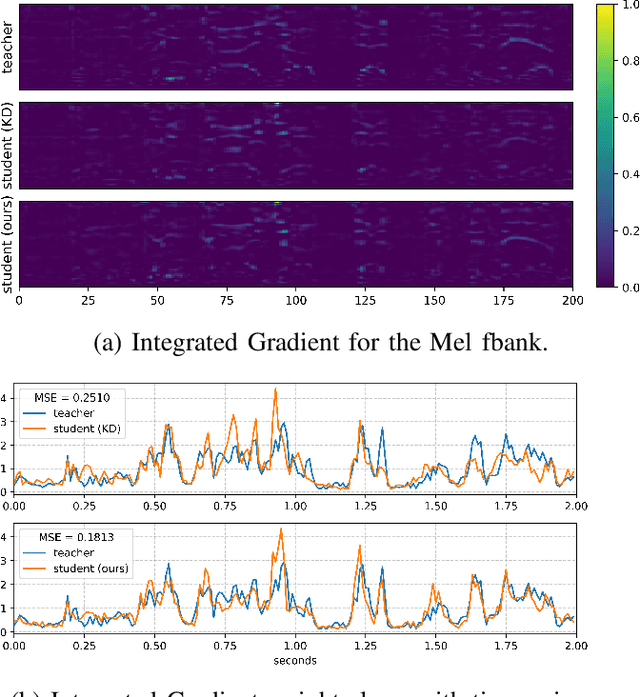

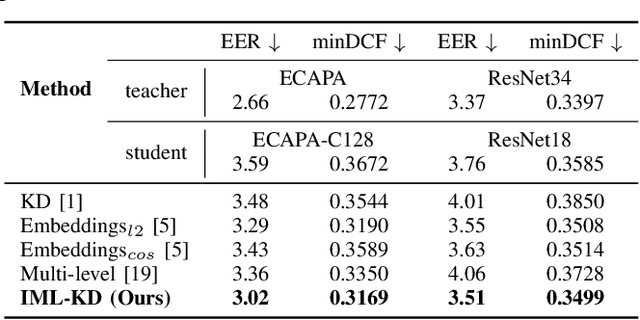
Knowledge distillation (KD) is widely used in audio tasks, such as speaker verification (SV), by transferring knowledge from a well-trained large model (the teacher) to a smaller, more compact model (the student) for efficiency and portability. Existing KD methods for SV often mirror those used in image processing, focusing on approximating predicted probabilities and hidden representations. However, these methods fail to account for the multi-level temporal properties of speech audio. In this paper, we propose a novel KD method, i.e., Integrated Multi-level Knowledge Distillation (IML-KD), to transfer knowledge of various temporal-scale features of speech from a teacher model to a student model. In the IML-KD, temporal context information from the teacher model is integrated into novel Integrated Gradient-based input-sensitive representations from speech segments with various durations, and the student model is trained to infer these representations with multi-level alignment for the output. We conduct SV experiments on the VoxCeleb1 dataset to evaluate the proposed method. Experimental results demonstrate that IML-KD significantly enhances KD performance, reducing the Equal Error Rate (EER) by 5%.
Channel Adaptation for Speaker Verification Using Optimal Transport with Pseudo Label
Sep 14, 2024



Domain gap often degrades the performance of speaker verification (SV) systems when the statistical distributions of training data and real-world test speech are mismatched. Channel variation, a primary factor causing this gap, is less addressed than other issues (e.g., noise). Although various domain adaptation algorithms could be applied to handle this domain gap problem, most algorithms could not take the complex distribution structure in domain alignment with discriminative learning. In this paper, we propose a novel unsupervised domain adaptation method, i.e., Joint Partial Optimal Transport with Pseudo Label (JPOT-PL), to alleviate the channel mismatch problem. Leveraging the geometric-aware distance metric of optimal transport in distribution alignment, we further design a pseudo label-based discriminative learning where the pseudo label can be regarded as a new type of soft speaker label derived from the optimal coupling. With the JPOT-PL, we carry out experiments on the SV channel adaptation task with VoxCeleb as the basis corpus. Experiments show our method reduces EER by over 10% compared with several state-of-the-art channel adaptation algorithms.
Robust Channel Learning for Large-Scale Radio Speaker Verification
Jun 16, 2024Recent research in speaker verification has increasingly focused on achieving robust and reliable recognition under challenging channel conditions and noisy environments. Identifying speakers in radio communications is particularly difficult due to inherent limitations such as constrained bandwidth and pervasive noise interference. To address this issue, we present a Channel Robust Speaker Learning (CRSL) framework that enhances the robustness of the current speaker verification pipeline, considering data source, data augmentation, and the efficiency of model transfer processes. Our framework introduces an augmentation module that mitigates bandwidth variations in radio speech datasets by manipulating the bandwidth of training inputs. It also addresses unknown noise by introducing noise within the manifold space. Additionally, we propose an efficient fine-tuning method that reduces the need for extensive additional training time and large amounts of data. Moreover, we develop a toolkit for assembling a large-scale radio speech corpus and establish a benchmark specifically tailored for radio scenario speaker verification studies. Experimental results demonstrate that our proposed methodology effectively enhances performance and mitigates degradation caused by radio transmission in speaker verification tasks. The code will be available on Github.
Weakly-Supervised Video Anomaly Detection with Snippet Anomalous Attention
Sep 28, 2023



With a focus on abnormal events contained within untrimmed videos, there is increasing interest among researchers in video anomaly detection. Among different video anomaly detection scenarios, weakly-supervised video anomaly detection poses a significant challenge as it lacks frame-wise labels during the training stage, only relying on video-level labels as coarse supervision. Previous methods have made attempts to either learn discriminative features in an end-to-end manner or employ a twostage self-training strategy to generate snippet-level pseudo labels. However, both approaches have certain limitations. The former tends to overlook informative features at the snippet level, while the latter can be susceptible to noises. In this paper, we propose an Anomalous Attention mechanism for weakly-supervised anomaly detection to tackle the aforementioned problems. Our approach takes into account snippet-level encoded features without the supervision of pseudo labels. Specifically, our approach first generates snippet-level anomalous attention and then feeds it together with original anomaly scores into a Multi-branch Supervision Module. The module learns different areas of the video, including areas that are challenging to detect, and also assists the attention optimization. Experiments on benchmark datasets XDViolence and UCF-Crime verify the effectiveness of our method. Besides, thanks to the proposed snippet-level attention, we obtain a more precise anomaly localization.
TMS: A Temporal Multi-scale Backbone Design for Speaker Embedding
Mar 17, 2022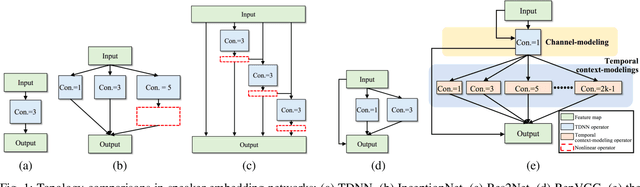
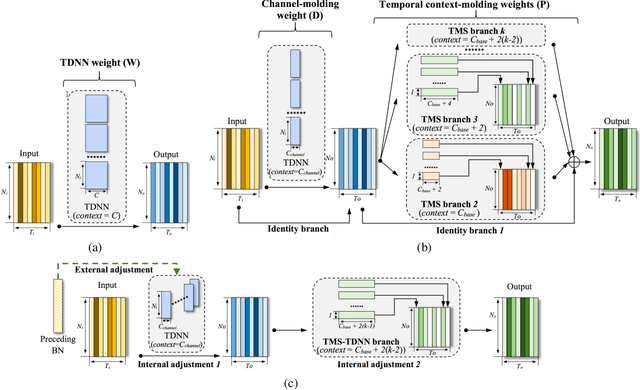
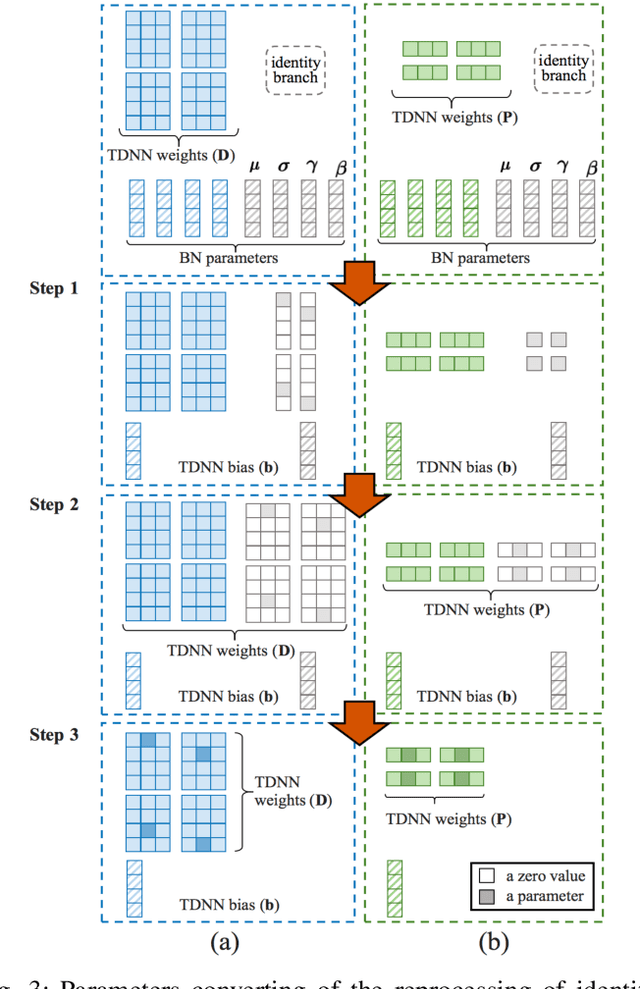
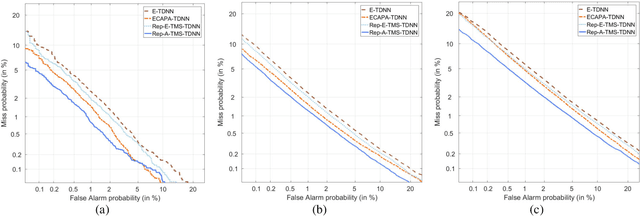
Speaker embedding is an important front-end module to explore discriminative speaker features for many speech applications where speaker information is needed. Current SOTA backbone networks for speaker embedding are designed to aggregate multi-scale features from an utterance with multi-branch network architectures for speaker representation. However, naively adding many branches of multi-scale features with the simple fully convolutional operation could not efficiently improve the performance due to the rapid increase of model parameters and computational complexity. Therefore, in the most current state-of-the-art network architectures, only a few branches corresponding to a limited number of temporal scales could be designed for speaker embeddings. To address this problem, in this paper, we propose an effective temporal multi-scale (TMS) model where multi-scale branches could be efficiently designed in a speaker embedding network almost without increasing computational costs. The new model is based on the conventional TDNN, where the network architecture is smartly separated into two modeling operators: a channel-modeling operator and a temporal multi-branch modeling operator. Adding temporal multi-scale in the temporal multi-branch operator needs only a little bit increase of the number of parameters, and thus save more computational budget for adding more branches with large temporal scales. Moreover, in the inference stage, we further developed a systemic re-parameterization method to convert the TMS-based model into a single-path-based topology in order to increase inference speed. We investigated the performance of the new TMS method for automatic speaker verification (ASV) on in-domain and out-of-domain conditions. Results show that the TMS-based model obtained a significant increase in the performance over the SOTA ASV models, meanwhile, had a faster inference speed.