 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Algorithms and RAG Enhancing Semi-Supervised Text Classification with Large LLMs
Nov 09, 2024



This paper introduces an innovative semi-supervised learning approach for text classification, addressing the challenge of abundant data but limited labeled examples. Our methodology integrates few-shot learning with retrieval-augmented generation (RAG) and conventional statistical clustering, enabling effective learning from a minimal number of labeled instances while generating high-quality labeled data. To the best of our knowledge, we are the first to incorporate RAG alongside clustering in text data generation. Our experiments on the Reuters and Web of Science datasets demonstrate state-of-the-art performance, with few-shot augmented data alone producing results nearly equivalent to those achieved with fully labeled datasets. Notably, accuracies of 95.41\% and 82.43\% were achieved for complex text document classification tasks, where the number of categories can exceed 100.
Weakly-Supervised Video Anomaly Detection with Snippet Anomalous Attention
Sep 28, 2023



With a focus on abnormal events contained within untrimmed videos, there is increasing interest among researchers in video anomaly detection. Among different video anomaly detection scenarios, weakly-supervised video anomaly detection poses a significant challenge as it lacks frame-wise labels during the training stage, only relying on video-level labels as coarse supervision. Previous methods have made attempts to either learn discriminative features in an end-to-end manner or employ a twostage self-training strategy to generate snippet-level pseudo labels. However, both approaches have certain limitations. The former tends to overlook informative features at the snippet level, while the latter can be susceptible to noises. In this paper, we propose an Anomalous Attention mechanism for weakly-supervised anomaly detection to tackle the aforementioned problems. Our approach takes into account snippet-level encoded features without the supervision of pseudo labels. Specifically, our approach first generates snippet-level anomalous attention and then feeds it together with original anomaly scores into a Multi-branch Supervision Module. The module learns different areas of the video, including areas that are challenging to detect, and also assists the attention optimization. Experiments on benchmark datasets XDViolence and UCF-Crime verify the effectiveness of our method. Besides, thanks to the proposed snippet-level attention, we obtain a more precise anomaly localization.
Improving Semantic Matching through Dependency-Enhanced Pre-trained Model with Adaptive Fusion
Oct 16, 2022
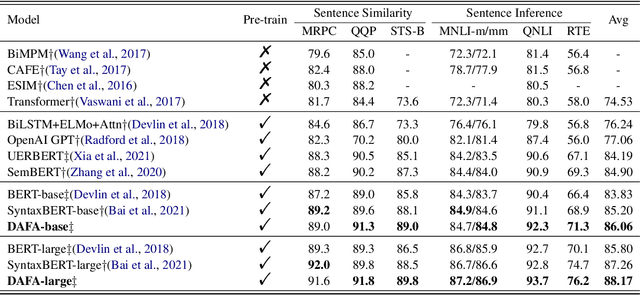
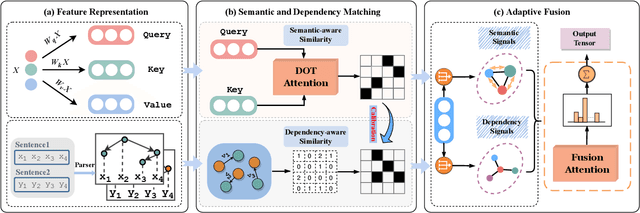
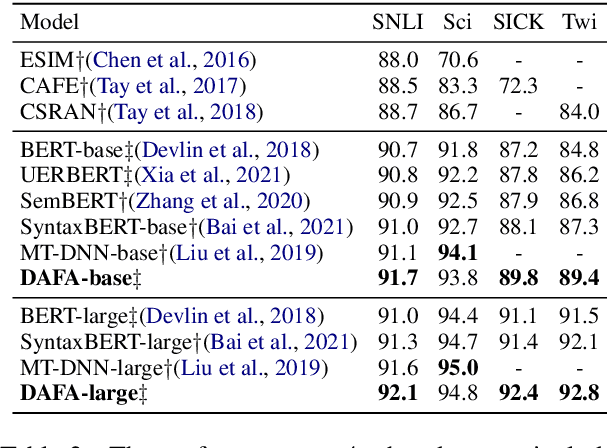
Transformer-based pre-trained models like BERT have achieved great progress on Semantic Sentence Matching. Meanwhile, dependency prior knowledge has also shown general benefits in multiple NLP tasks. However, how to efficiently integrate dependency prior structure into pre-trained models to better model complex semantic matching relations is still unsettled. In this paper, we propose the \textbf{D}ependency-Enhanced \textbf{A}daptive \textbf{F}usion \textbf{A}ttention (\textbf{DAFA}), which explicitly introduces dependency structure into pre-trained models and adaptively fuses it with semantic information. Specifically, \textbf{\emph{(i)}} DAFA first proposes a structure-sensitive paradigm to construct a dependency matrix for calibrating attention weights. It adopts an adaptive fusion module to integrate the obtained dependency information and the original semantic signals. Moreover, DAFA reconstructs the attention calculation flow and provides better interpretability. By applying it on BERT, our method achieves state-of-the-art or competitive performance on 10 public datasets, demonstrating the benefits of adaptively fusing dependency structure in semantic matching task.
GTM: Gray Temporal Model for Video Recognition
Oct 20, 2021
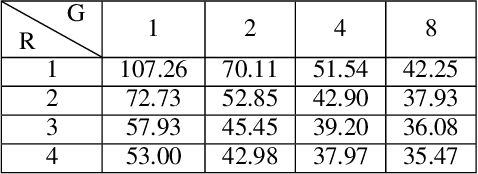

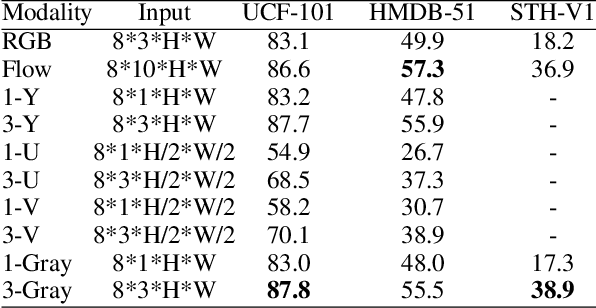
Data input modality plays an important role in video action recognition. Normally, there are three types of input: RGB, flow stream and compressed data. In this paper, we proposed a new input modality: gray stream. Specifically, taken the stacked consecutive 3 gray images as input, which is the same size of RGB, can not only skip the conversion process from video decoding data to RGB, but also improve the spatio-temporal modeling ability at zero computation and zero parameters. Meanwhile, we proposed a 1D Identity Channel-wise Spatio-temporal Convolution(1D-ICSC) which captures the temporal relationship at channel-feature level within a controllable computation budget(by parameters G & R). Finally, we confirm its effectiveness and efficiency on several action recognition benchmarks, such as Kinetics, Something-Something, HMDB-51 and UCF-101, and achieve impressive results.