 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTM: Gray Temporal Model for Video Recognition
Paper and Code
Oct 20, 2021
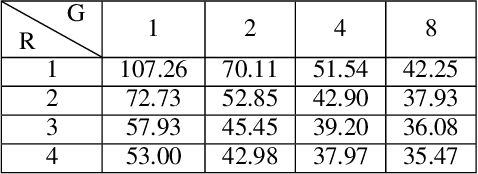

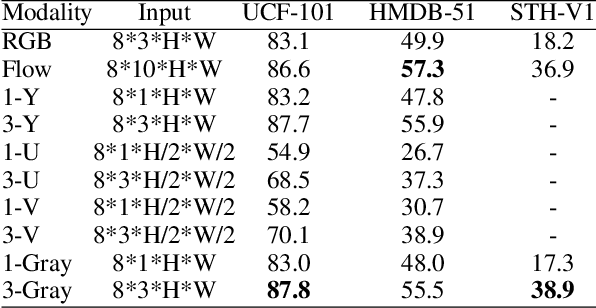
Data input modality plays an important role in video action recognition. Normally, there are three types of input: RGB, flow stream and compressed data. In this paper, we proposed a new input modality: gray stream. Specifically, taken the stacked consecutive 3 gray images as input, which is the same size of RGB, can not only skip the conversion process from video decoding data to RGB, but also improve the spatio-temporal modeling ability at zero computation and zero parameters. Meanwhile, we proposed a 1D Identity Channel-wise Spatio-temporal Convolution(1D-ICSC) which captures the temporal relationship at channel-feature level within a controllable computation budget(by parameters G & R). Finally, we confirm its effectiveness and efficiency on several action recognition benchmarks, such as Kinetics, Something-Something, HMDB-51 and UCF-101, and achieve impressive results.