 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy are hyperbolic neural networks effective? A study on hierarchical representation capability
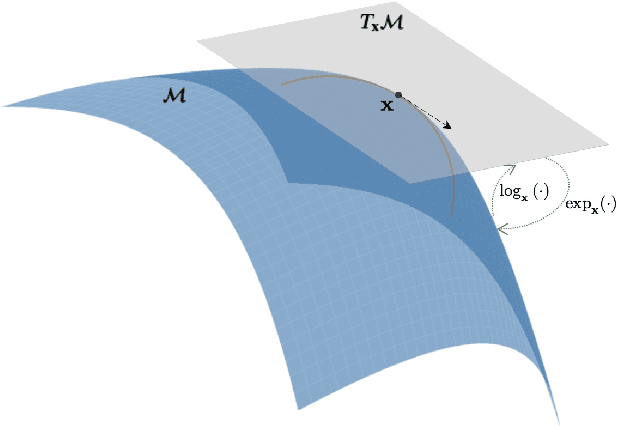
Feb 04, 2024Hyperbolic Neural Networks (HNNs), operating in hyperbolic space, have been widely applied in recent years, motivated by the existence of an optimal embedding in hyperbolic space that can preserve data hierarchical relationships (termed Hierarchical Representation Capability, HRC) more accurately than Euclidean space. However, there is no evidence to suggest that HNNs can achieve this theoretical optimal embedding, leading to much research being built on flawed motivations. In this paper, we propose a benchmark for evaluating HRC and conduct a comprehensive analysis of why HNNs are effective through large-scale experiments. Inspired by the analysis results, we propose several pre-training strategies to enhance HRC and improve the performance of downstream tasks, further validating the reliability of the analysis. Experiments show that HNNs cannot achieve the theoretical optimal embedding. The HRC is significantly affected by the optimization objectives and hierarchical structures, and enhancing HRC through pre-training strategies can significantly improve the performance of HNNs.
TMA: Temporal Motion Aggregation for Event-based Optical Flow
Mar 21, 2023Event cameras have the ability to record continuous and detailed trajectories of objects with high temporal resolution, thereby providing intuitive motion cues for optical flow estimation. Nevertheless, most existing learning-based approaches for event optical flow estimation directly remould the paradigm of conventional images by representing the consecutive event stream as static frames, ignoring the inherent temporal continuity of event data. In this paper, we argue that temporal continuity is a vital element of event-based optical flow and propose a novel Temporal Motion Aggregation (TMA) approach to unlock its potential. Technically, TMA comprises three components: an event splitting strategy to incorporate intermediate motion information underlying the temporal context, a linear lookup strategy to align temporally continuous motion features and a novel motion pattern aggregation module to emphasize consistent patterns for motion feature enhancement. By incorporating temporally continuous motion information, TMA can derive better flow estimates than existing methods at early stages, which not only enables TMA to obtain more accurate final predictions, but also greatly reduces the demand for a number of refinements. Extensive experiments on DESC-Flow and MVSEC datasets verify the effectiveness and superiority of our TMA. Remarkably, compared to E-RAFT, TMA achieves a 6% improvement in accuracy and a 40% reduction in inference time on DSEC-Flow.
Hyperbolic Hierarchical Knowledge Graph Embeddings for Link Prediction in Low Dimensions
Apr 28, 2022
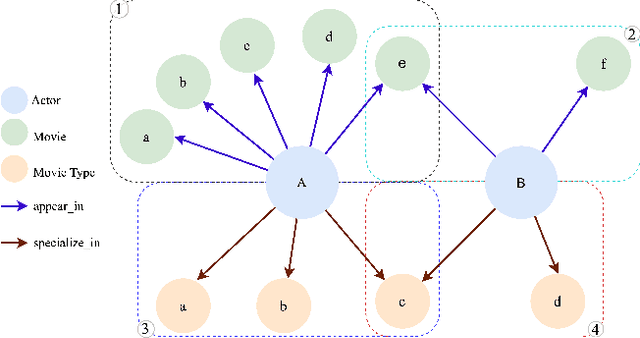
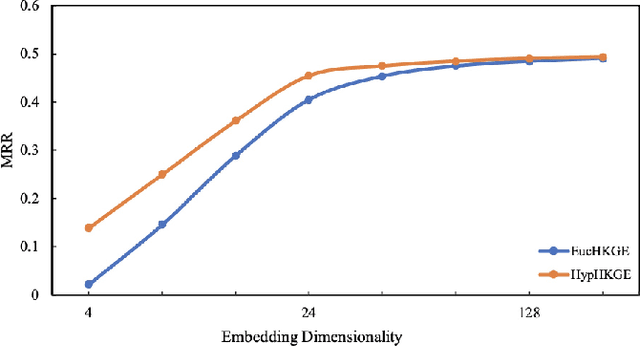
Knowledge graph embeddings (KGE) have been validated as powerful methods for inferring missing links in knowledge graphs (KGs) since they map entities into Euclidean space and treat relations as transformations of entities. Currently, some Euclidean KGE methods model semantic hierarchies prevalent in KGs and promote the performance of link prediction. For hierarchical data, instead of traditional Euclidean space, hyperbolic space as an embedding space has shown the promise of high fidelity and low memory consumption; however, existing hyperbolic KGE methods neglect to model them. To address this issue, we propose a novel KGE model -- hyperbolic hierarchical KGE (HypHKGE). To be specific, we first design the attention-based learnable curvatures for hyperbolic space to preserve rich semantic hierarchies. Moreover, we define the hyperbolic hierarchical transformations based on the theory of hyperbolic geometry, which utilize hierarchies that we preserved to infer the links. Experiments show that HypHKGE can effectively model semantic hierarchies in hyperbolic space and outperforms the state-of-the-art hyperbolic methods, especially in low dimensions.
Coherence-Based Distributed Document Representation Learning for Scientific Documents
Jan 08, 2022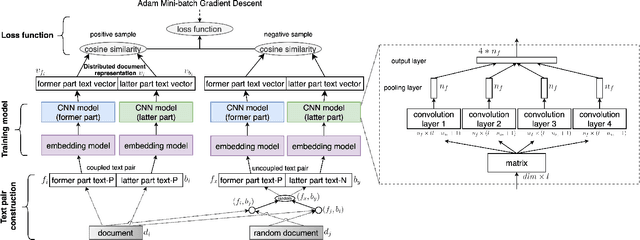
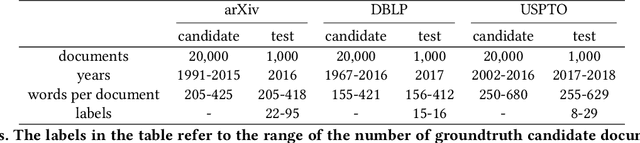
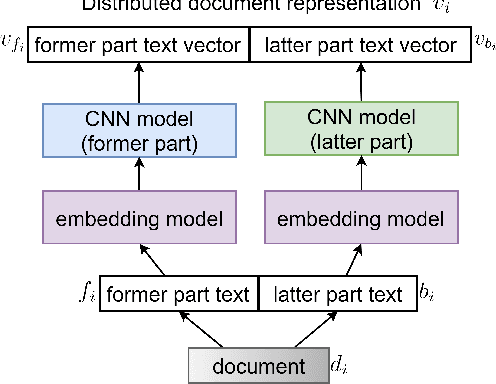
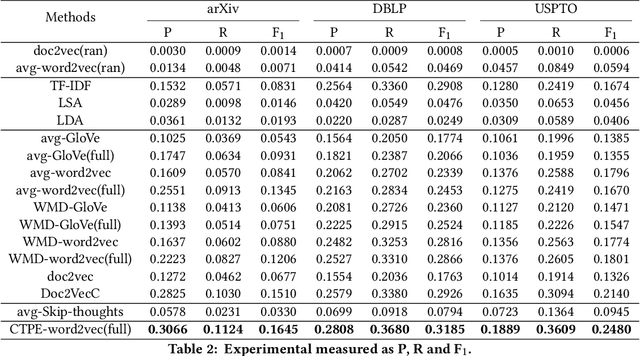
Distributed document representation is one of the basic problems in natural language processing. Currently distributed document representation methods mainly consider the context information of words or sentences. These methods do not take into account the coherence of the document as a whole, e.g., a relation between the paper title and abstract, headline and description, or adjacent bodies in the document. The coherence shows whether a document is meaningful, both logically and syntactically, especially in scientific documents (papers or patents, etc.). In this paper, we propose a coupled text pair embedding (CTPE) model to learn the representation of scientific documents, which maintains the coherence of the document with coupled text pairs formed by segmenting the document. First, we divide the document into two parts (e.g., title and abstract, etc) which construct a coupled text pair. Then, we adopt negative sampling to construct uncoupled text pairs whose two parts are from different documents. Finally, we train the model to judge whether the text pair is coupled or uncoupled and use the obtained embedding of coupled text pairs as the embedding of documents. We perform experiments on three datasets for one information retrieval task and two recommendation tasks. The experimental results verify the effectiveness of the proposed CTPE model.
GTM: Gray Temporal Model for Video Recognition
Oct 20, 2021
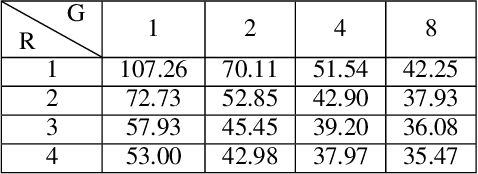

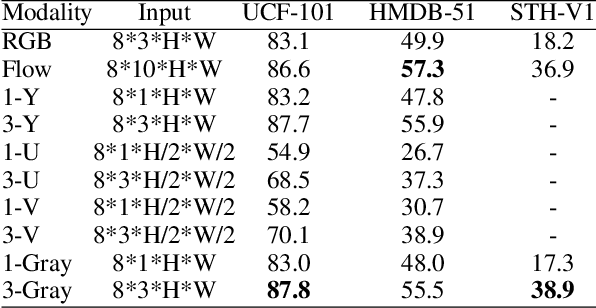
Data input modality plays an important role in video action recognition. Normally, there are three types of input: RGB, flow stream and compressed data. In this paper, we proposed a new input modality: gray stream. Specifically, taken the stacked consecutive 3 gray images as input, which is the same size of RGB, can not only skip the conversion process from video decoding data to RGB, but also improve the spatio-temporal modeling ability at zero computation and zero parameters. Meanwhile, we proposed a 1D Identity Channel-wise Spatio-temporal Convolution(1D-ICSC) which captures the temporal relationship at channel-feature level within a controllable computation budget(by parameters G & R). Finally, we confirm its effectiveness and efficiency on several action recognition benchmarks, such as Kinetics, Something-Something, HMDB-51 and UCF-101, and achieve impressive results.
JAS-GAN: Generative Adversarial Network Based Joint Atrium and Scar Segmentations on Unbalanced Atrial Targets
May 01, 2021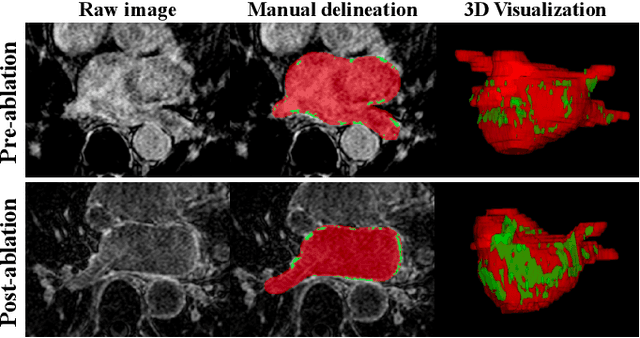
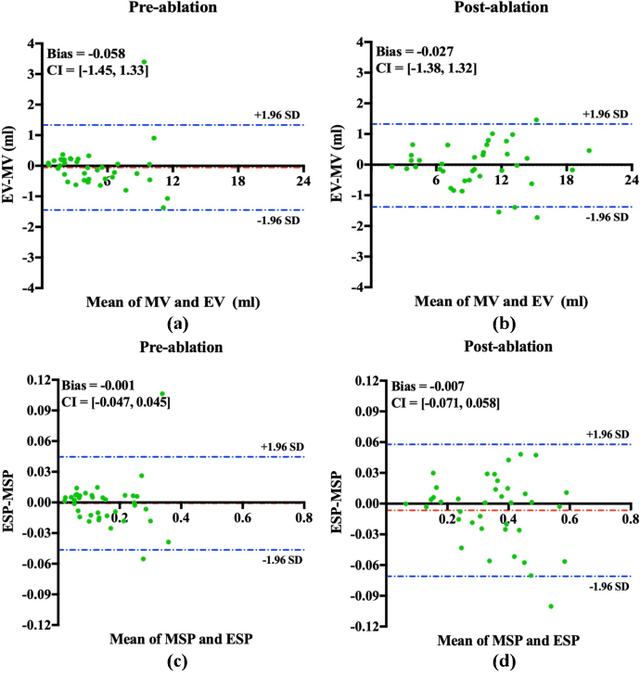
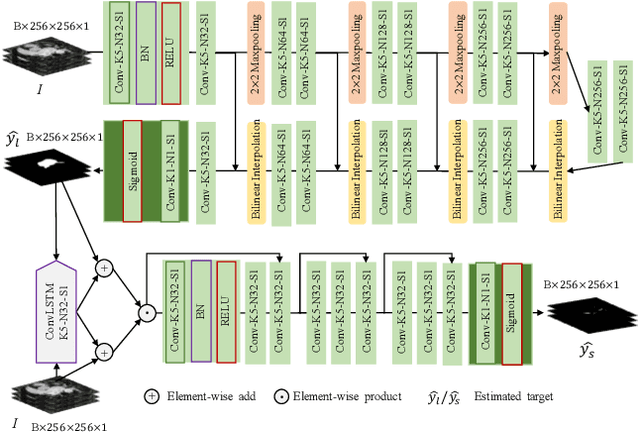
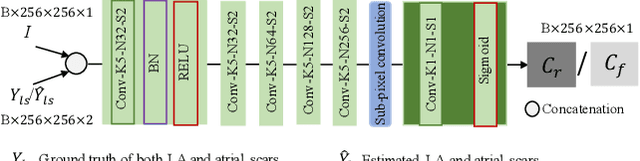
Automated and accurate segmentations of left atrium (LA) and atrial scars from late gadolinium-enhanced cardiac magnetic resonance (LGE CMR) images are in high demand for quantifying atrial scars. The previous quantification of atrial scars relies on a two-phase segmentation for LA and atrial scars due to their large volume difference (unbalanced atrial targets). In this paper, we propose an inter-cascade generative adversarial network, namely JAS-GAN, to segment the unbalanced atrial targets from LGE CMR images automatically and accurately in an end-to-end way. Firstly, JAS-GAN investigates an adaptive attention cascade to automatically correlate the segmentation tasks of the unbalanced atrial targets. The adaptive attention cascade mainly models the inclusion relationship of the two unbalanced atrial targets, where the estimated LA acts as the attention map to adaptively focus on the small atrial scars roughly. Then, an adversarial regularization is applied to the segmentation tasks of the unbalanced atrial targets for making a consistent optimization. It mainly forces the estimated joint distribution of LA and atrial scars to match the real ones. We evaluated the performance of our JAS-GAN on a 3D LGE CMR dataset with 192 scans. Compared with the state-of-the-art methods, our proposed approach yielded better segmentation performance (Average Dice Similarity Coefficient (DSC) values of 0.946 and 0.821 for LA and atrial scars, respectively), which indicated the effectiveness of our proposed approach for segmenting unbalanced atrial targets.
Simultaneous Left Atrium Anatomy and Scar Segmentations via Deep Learning in Multiview Information with Attention
Feb 02, 2020
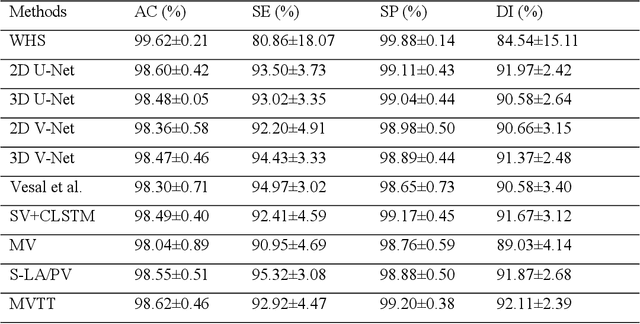

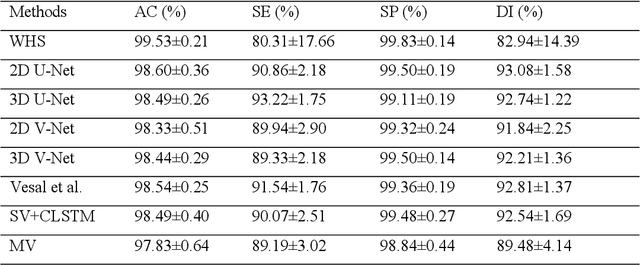
Three-dimensional late gadolinium enhanced (LGE) cardiac MR (CMR) of left atrial scar in patients with atrial fibrillation (AF) has recently emerged as a promising technique to stratify patients, to guide ablation therapy and to predict treatment success. This requires a segmentation of the high intensity scar tissue and also a segmentation of the left atrium (LA) anatomy, the latter usually being derived from a separate bright-blood acquisition. Performing both segmentations automatically from a single 3D LGE CMR acquisition would eliminate the need for an additional acquisition and avoid subsequent registration issues. In this paper, we propose a joint segmentation method based on multiview two-task (MVTT) recursive attention model working directly on 3D LGE CMR images to segment the LA (and proximal pulmonary veins) and to delineate the scar on the same dataset. Using our MVTT recursive attention model, both the LA anatomy and scar can be segmented accurately (mean Dice score of 93% for the LA anatomy and 87% for the scar segmentations) and efficiently (~0.27 seconds to simultaneously segment the LA anatomy and scars directly from the 3D LGE CMR dataset with 60-68 2D slices). Compared to conventional unsupervised learning and other state-of-the-art deep learning based methods, the proposed MVTT model achieved excellent results, leading to an automatic generation of a patient-specific anatomical model combined with scar segmentation for patients in AF.
Direct Quantification for Coronary Artery Stenosis Using Multiview Learning
Aug 02, 2019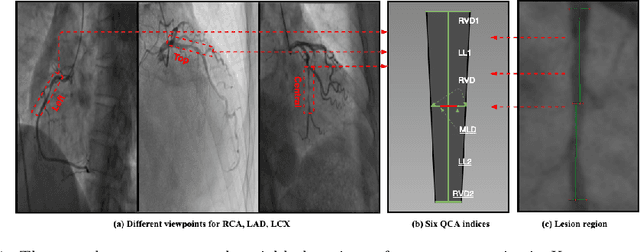
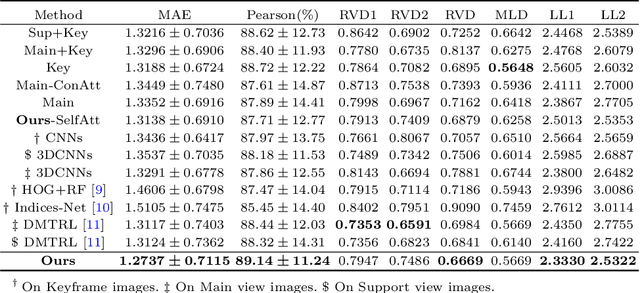
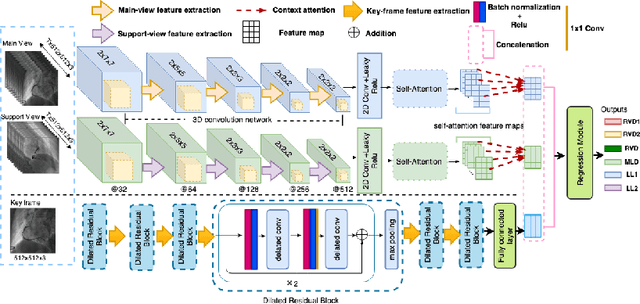
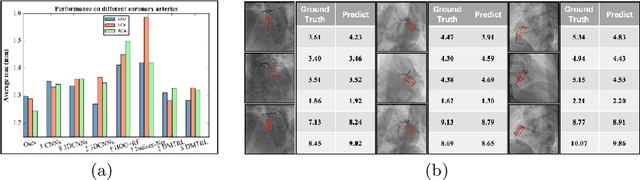
The quantification of the coronary artery stenosis is of significant clinical importance in coronary artery disease diagnosis and intervention treatment. It aims to quantify the morphological indices of the coronary artery lesions such as minimum lumen diameter, reference vessel diameter, lesion length, and these indices are the reference of the interventional stent placement. In this study, we propose a direct multiview quantitative coronary angiography (DMQCA) model as an automatic clinical tool to quantify the coronary artery stenosis from X-ray coronary angiography images. The proposed DMQCA model consists of a multiview module with two attention mechanisms, a key-frame module, and a regression module, to achieve direct accurate multiple-index estimation. The multi-view module comprehensively learns the Spatio-temporal features of coronary arteries through a three-dimensional convolution. The attention mechanisms of each view focus on the subtle feature of the lesion region and capture the important context information. The key-frame module learns the subtle features of the stenosis through successive dilated residual blocks. The regression module finally generates the indices estimation from multiple features.
Discriminative Consistent Domain Generation for Semi-supervised Learning
Jul 24, 2019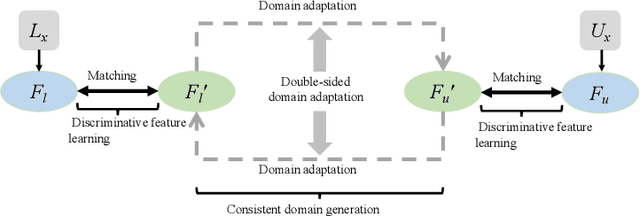
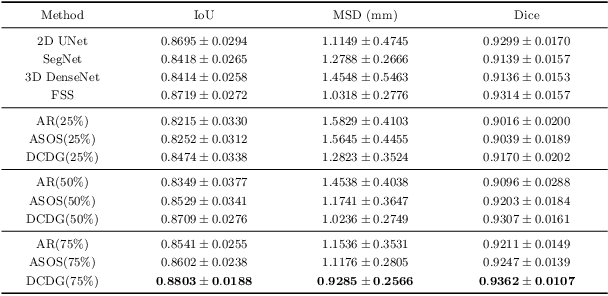
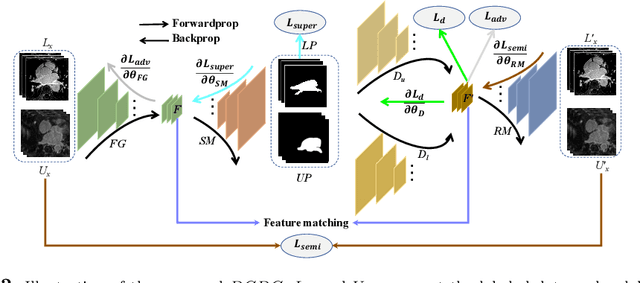
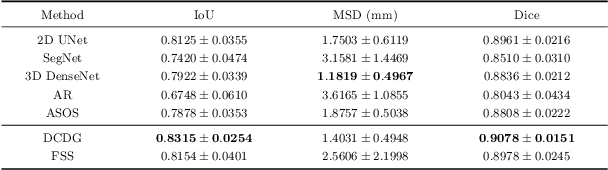
Deep learning based task systems normally rely on a large amount of manually labeled training data, which is expensive to obtain and subject to operator variations. Moreover, it does not always hold that the manually labeled data and the unlabeled data are sitting in the same distribution. In this paper, we alleviate these problems by proposing a discriminative consistent domain generation (DCDG) approach to achieve a semi-supervised learning. The discriminative consistent domain is achieved by a double-sided domain adaptation. The double-sided domain adaptation aims to make a fusion of the feature spaces of labeled data and unlabeled data. In this way, we can fit the differences of various distributions between labeled data and unlabeled data. In order to keep the discriminativeness of generated consistent domain for the task learning, we apply an indirect learning for the double-sided domain adaptation. Based on the generated discriminative consistent domain, we can use the unlabeled data to learn the task model along with the labeled data via a consistent image generation. We demonstrate the performance of our proposed DCDG on the late gadolinium enhancement cardiac MRI (LGE-CMRI) images acquired from patients with atrial fibrillation in two clinical centers for the segmentation of the left atrium anatomy (LA) and proximal pulmonary veins (PVs). The experiments show that our semi-supervised approach achieves compelling segmentation results, which can prove the robustness of DCDG for the semi-supervised learning using the unlabeled data along with labeled data acquired from a single center or multicenter studies.
Multiview Two-Task Recursive Attention Model for Left Atrium and Atrial Scars Segmentation
Jun 12, 2018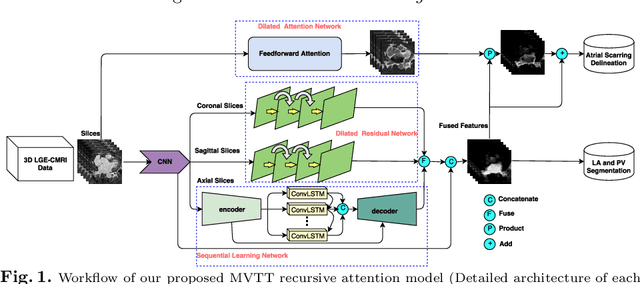
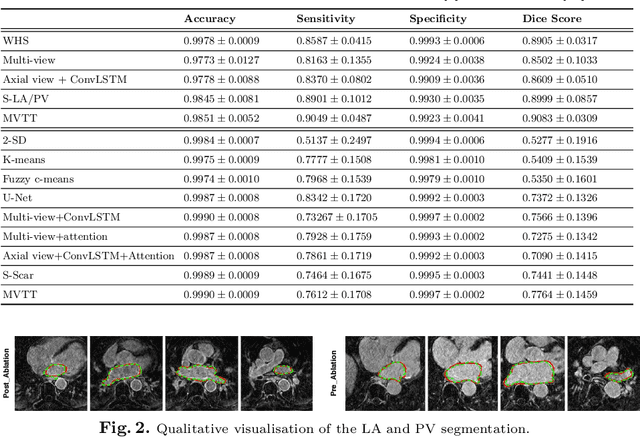
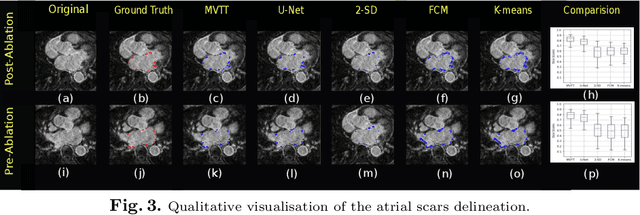
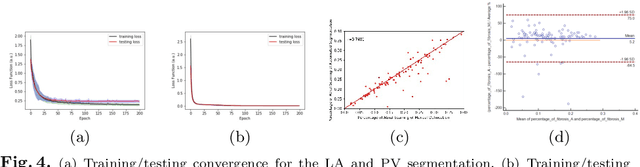
Late Gadolinium Enhanced Cardiac MRI (LGE-CMRI) for detecting atrial scars in atrial fibrillation (AF) patients has recently emerged as a promising technique to stratify patients, guide ablation therapy and predict treatment success. Visualisation and quantification of scar tissues require a segmentation of both the left atrium (LA) and the high intensity scar regions from LGE-CMRI images. These two segmentation tasks are challenging due to the cancelling of healthy tissue signal, low signal-to-noise ratio and often limited image quality in these patients. Most approaches require manual supervision and/or a second bright-blood MRI acquisition for anatomical segmentation. Segmenting both the LA anatomy and the scar tissues automatically from a single LGE-CMRI acquisition is highly in demand. In this study, we proposed a novel fully automated multiview two-task (MVTT) recursive attention model working directly on LGE-CMRI images that combines a sequential learning and a dilated residual learning to segment the LA (including attached pulmonary veins) and delineate the atrial scars simultaneously via an innovative attention model. Compared to other state-of-the-art methods, the proposed MVTT achieves compelling improvement, enabling to generate a patient-specific anatomical and atrial scar assessment model.