 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCS-Rep: Making Speaker Verification Networks Embracing Re-parameterization
Paper and Code
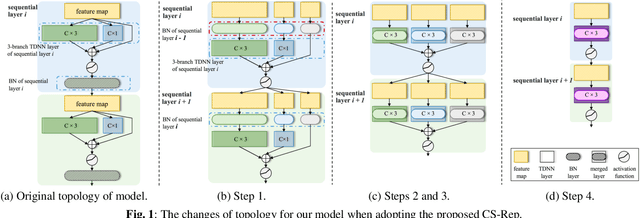
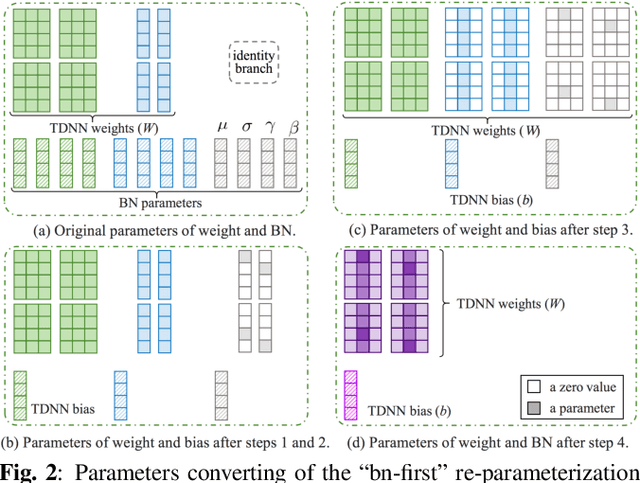
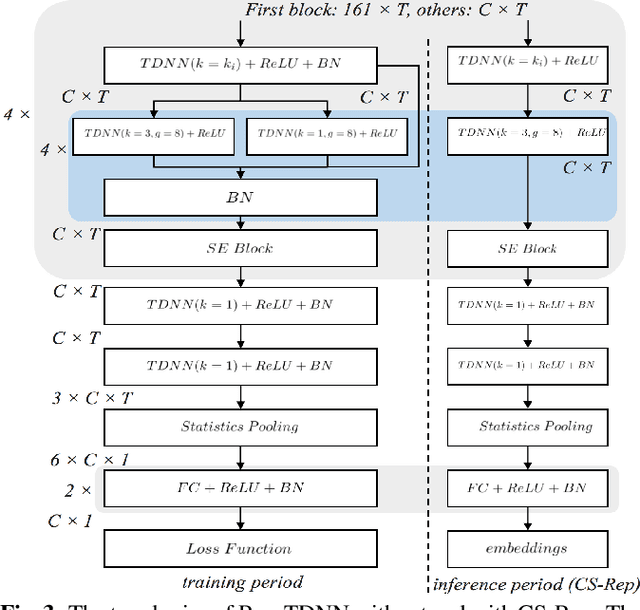
Automatic speaker verification (ASV) systems, which determine whether two speeches are from the same speaker, mainly focus on verification accuracy while ignoring inference speed. However, in real applications, both inference speed and verification accuracy are essential. This study proposes cross-sequential re-parameterization (CS-Rep), a novel topology re-parameterization strategy for multi-type networks, to increase the inference speed and verification accuracy of models. CS-Rep solves the problem that existing re-parameterization methods are unsuitable for typical ASV backbones. When a model applies CS-Rep, the training-period network utilizes a multi-branch topology to capture speaker information, whereas the inference-period model converts to a time-delay neural network (TDNN)-like plain backbone with stacked TDNN layers to achieve the fast inference speed. Based on CS-Rep, an improved TDNN with friendly test and deployment called Rep-TDNN is proposed. Compared with the state-of-the-art model ECAPA-TDNN, which is highly recognized in the industry, Rep-TDNN increases the actual inference speed by about 50% and reduces the EER by 10%. The code will be released.