 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBG-YOLO: A Bidirectional-Guided Method for Underwater Object Detection
Apr 13, 2024



Degraded underwater images decrease the accuracy of underwater object detection. However, existing methods for underwater image enhancement mainly focus on improving the indicators in visual aspects, which may not benefit the tasks of underwater image detection, and may lead to serious degradation in performance. To alleviate this problem, we proposed a bidirectional-guided method for underwater object detection, referred to as BG-YOLO. In the proposed method, network is organized by constructing an enhancement branch and a detection branch in a parallel way. The enhancement branch consists of a cascade of an image enhancement subnet and an object detection subnet. And the detection branch only consists of a detection subnet. A feature guided module connects the shallow convolution layer of the two branches. When training the enhancement branch, the object detection subnet in the enhancement branch guides the image enhancement subnet to be optimized towards the direction that is most conducive to the detection task. The shallow feature map of the trained enhancement branch will be output to the feature guided module, constraining the optimization of detection branch through consistency loss and prompting detection branch to learn more detailed information of the objects. And hence the detection performance will be refined. During the detection tasks, only detection branch will be reserved so that no additional cost of computation will be introduced. Extensive experiments demonstrate that the proposed method shows significant improvement in performance of the detector in severely degraded underwater scenes while maintaining a remarkable detection speed.
TMS: A Temporal Multi-scale Backbone Design for Speaker Embedding
Mar 17, 2022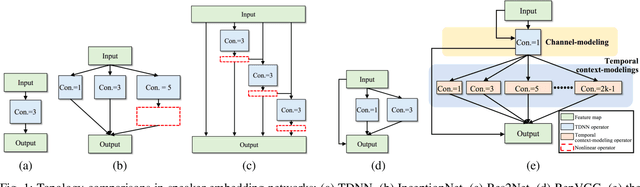
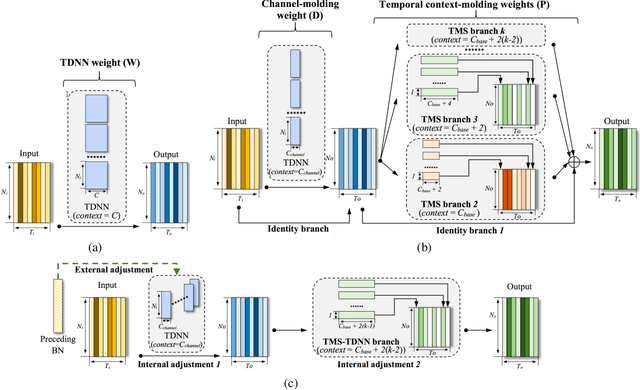
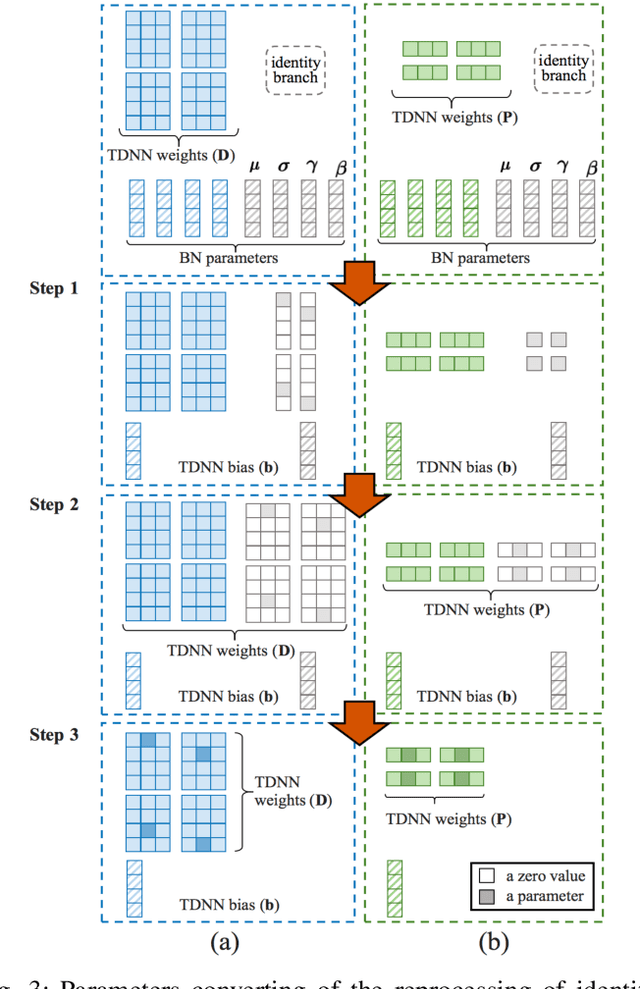
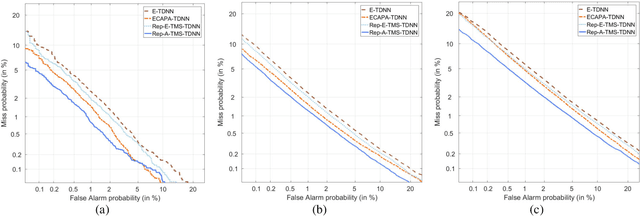
Speaker embedding is an important front-end module to explore discriminative speaker features for many speech applications where speaker information is needed. Current SOTA backbone networks for speaker embedding are designed to aggregate multi-scale features from an utterance with multi-branch network architectures for speaker representation. However, naively adding many branches of multi-scale features with the simple fully convolutional operation could not efficiently improve the performance due to the rapid increase of model parameters and computational complexity. Therefore, in the most current state-of-the-art network architectures, only a few branches corresponding to a limited number of temporal scales could be designed for speaker embeddings. To address this problem, in this paper, we propose an effective temporal multi-scale (TMS) model where multi-scale branches could be efficiently designed in a speaker embedding network almost without increasing computational costs. The new model is based on the conventional TDNN, where the network architecture is smartly separated into two modeling operators: a channel-modeling operator and a temporal multi-branch modeling operator. Adding temporal multi-scale in the temporal multi-branch operator needs only a little bit increase of the number of parameters, and thus save more computational budget for adding more branches with large temporal scales. Moreover, in the inference stage, we further developed a systemic re-parameterization method to convert the TMS-based model into a single-path-based topology in order to increase inference speed. We investigated the performance of the new TMS method for automatic speaker verification (ASV) on in-domain and out-of-domain conditions. Results show that the TMS-based model obtained a significant increase in the performance over the SOTA ASV models, meanwhile, had a faster inference speed.
CS-Rep: Making Speaker Verification Networks Embracing Re-parameterization
Oct 26, 2021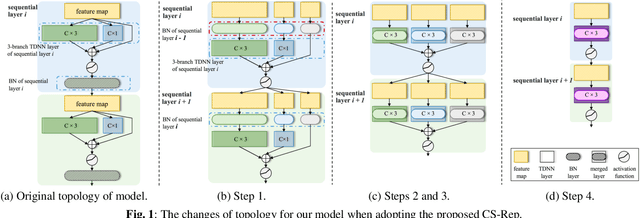
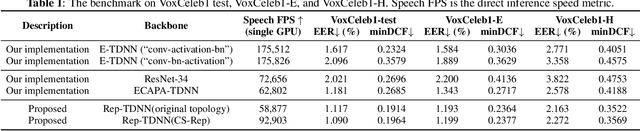
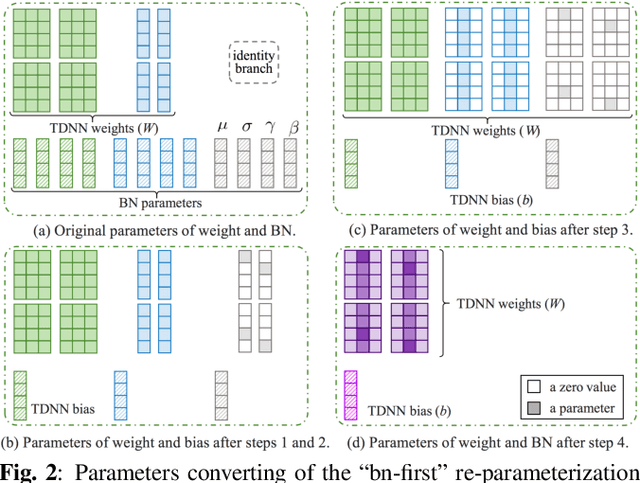
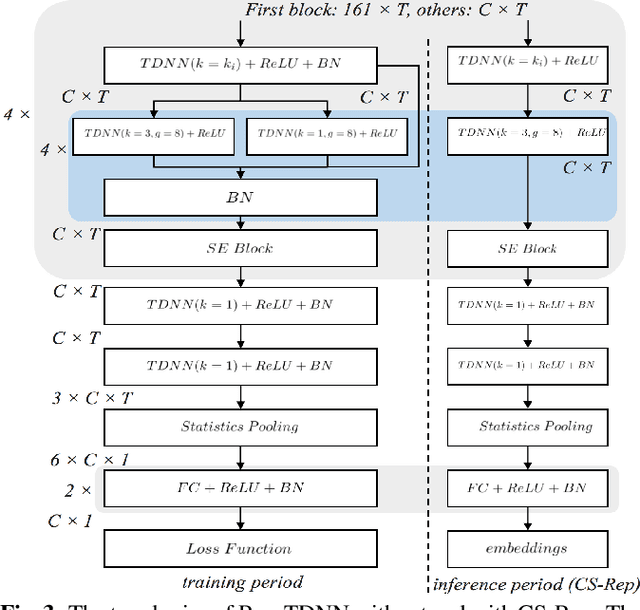
Automatic speaker verification (ASV) systems, which determine whether two speeches are from the same speaker, mainly focus on verification accuracy while ignoring inference speed. However, in real applications, both inference speed and verification accuracy are essential. This study proposes cross-sequential re-parameterization (CS-Rep), a novel topology re-parameterization strategy for multi-type networks, to increase the inference speed and verification accuracy of models. CS-Rep solves the problem that existing re-parameterization methods are unsuitable for typical ASV backbones. When a model applies CS-Rep, the training-period network utilizes a multi-branch topology to capture speaker information, whereas the inference-period model converts to a time-delay neural network (TDNN)-like plain backbone with stacked TDNN layers to achieve the fast inference speed. Based on CS-Rep, an improved TDNN with friendly test and deployment called Rep-TDNN is proposed. Compared with the state-of-the-art model ECAPA-TDNN, which is highly recognized in the industry, Rep-TDNN increases the actual inference speed by about 50% and reduces the EER by 10%. The code will be released.