 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTMS: A Temporal Multi-scale Backbone Design for Speaker Embedding
Paper and Code
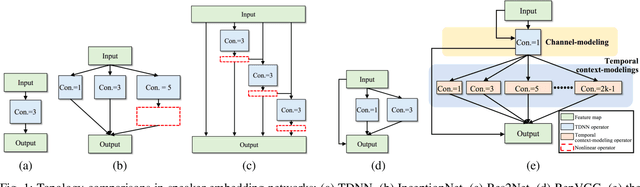
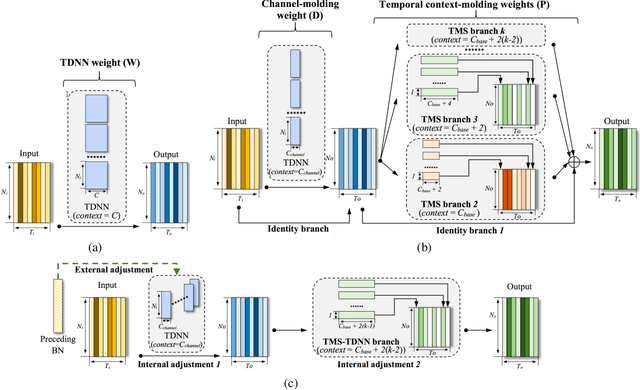
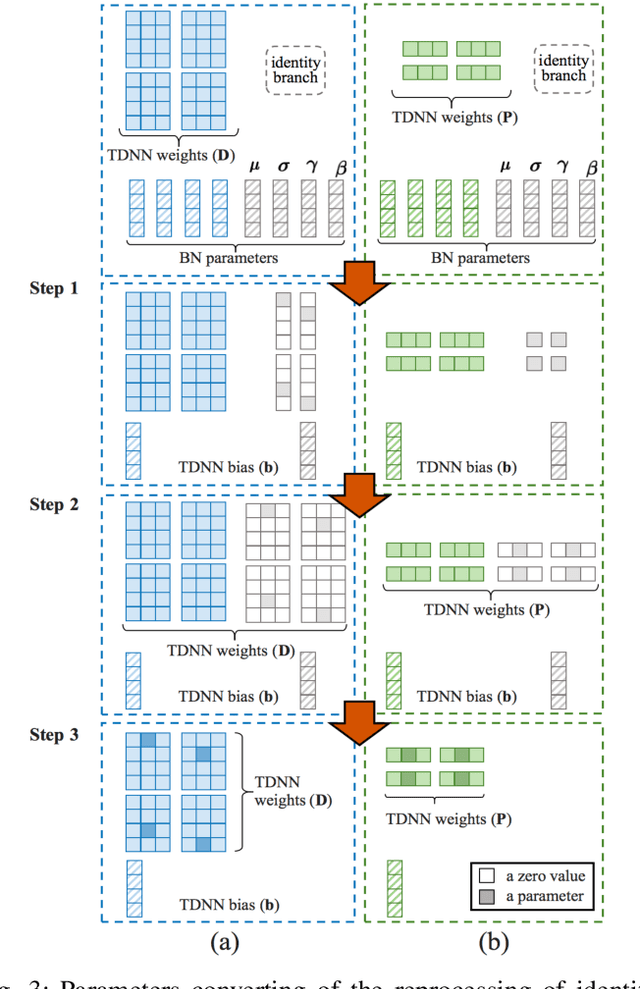
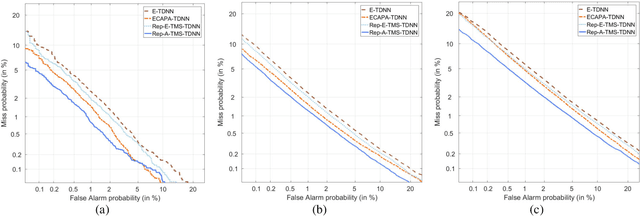
Speaker embedding is an important front-end module to explore discriminative speaker features for many speech applications where speaker information is needed. Current SOTA backbone networks for speaker embedding are designed to aggregate multi-scale features from an utterance with multi-branch network architectures for speaker representation. However, naively adding many branches of multi-scale features with the simple fully convolutional operation could not efficiently improve the performance due to the rapid increase of model parameters and computational complexity. Therefore, in the most current state-of-the-art network architectures, only a few branches corresponding to a limited number of temporal scales could be designed for speaker embeddings. To address this problem, in this paper, we propose an effective temporal multi-scale (TMS) model where multi-scale branches could be efficiently designed in a speaker embedding network almost without increasing computational costs. The new model is based on the conventional TDNN, where the network architecture is smartly separated into two modeling operators: a channel-modeling operator and a temporal multi-branch modeling operator. Adding temporal multi-scale in the temporal multi-branch operator needs only a little bit increase of the number of parameters, and thus save more computational budget for adding more branches with large temporal scales. Moreover, in the inference stage, we further developed a systemic re-parameterization method to convert the TMS-based model into a single-path-based topology in order to increase inference speed. We investigated the performance of the new TMS method for automatic speaker verification (ASV) on in-domain and out-of-domain conditions. Results show that the TMS-based model obtained a significant increase in the performance over the SOTA ASV models, meanwhile, had a faster inference speed.