 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Speak Once to See
Paper and Code
Sep 27, 2024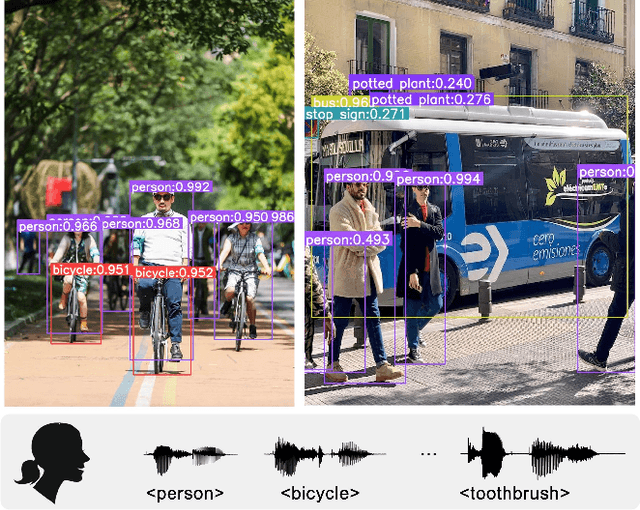
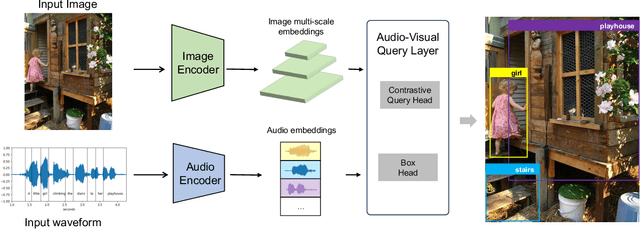
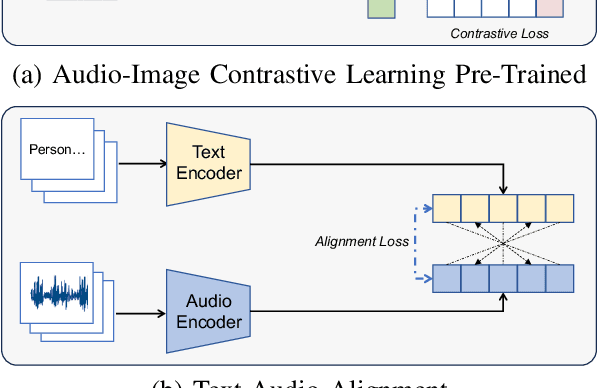
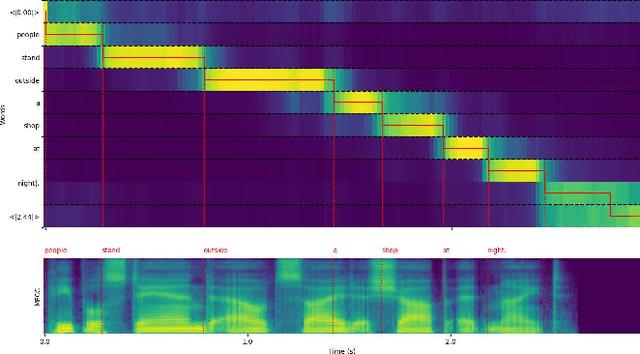
Grounding objects in images using visual cues is a well-established approach in computer vision, yet the potential of audio as a modality for object recognition and grounding remains underexplored. We introduce YOSS, "You Only Speak Once to See," to leverage audio for grounding objects in visual scenes, termed Audio Grounding. By integrating pre-trained audio models with visual models using contrastive learning and multi-modal alignment, our approach captures speech commands or descriptions and maps them directly to corresponding objects within images. Experimental results indicate that audio guidance can be effectively applied to object grounding, suggesting that incorporating audio guidance may enhance the precision and robustness of current object grounding methods and improve the performance of robotic systems and computer vision applications. This finding opens new possibilities for advanced object recognition, scene understanding, and the development of more intuitive and capable robotic systems.