 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMBO-NET: Multi-Causal Aware Modeling Backdoor-Intervention Optimization for Medical Image Segmentation Network
May 28, 2025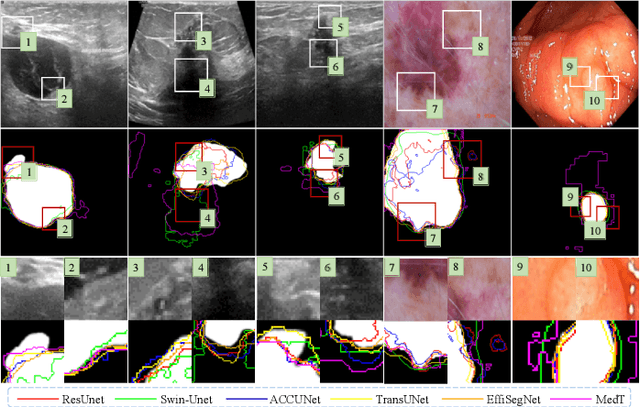
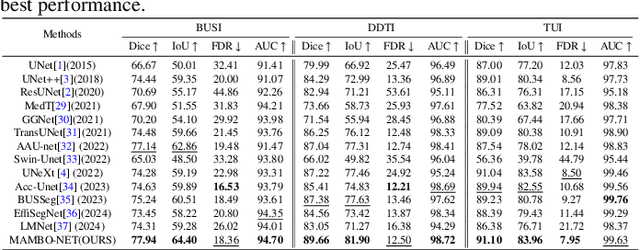
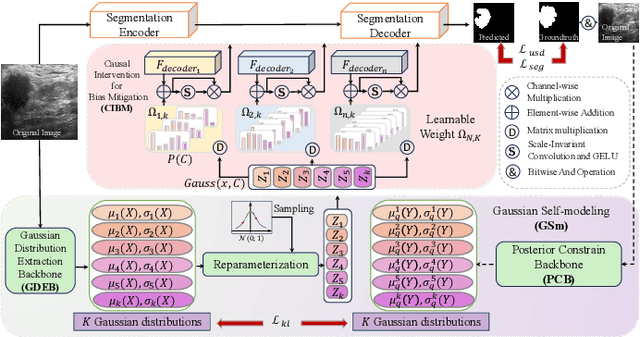
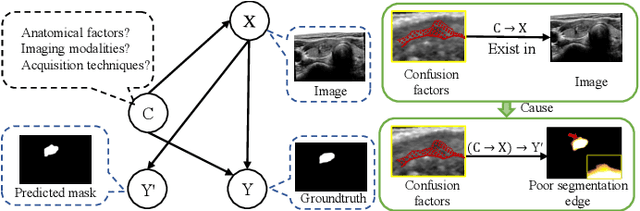
Medical image segmentation methods generally assume that the process from medical image to segmentation is unbiased, and use neural networks to establish conditional probability models to complete the segmentation task. This assumption does not consider confusion factors, which can affect medical images, such as complex anatomical variations and imaging modality limitations. Confusion factors obfuscate the relevance and causality of medical image segmentation, leading to unsatisfactory segmentation results. To address this issue, we propose a multi-causal aware modeling backdoor-intervention optimization (MAMBO-NET) network for medical image segmentation. Drawing insights from causal inference, MAMBO-NET utilizes self-modeling with multi-Gaussian distributions to fit the confusion factors and introduce causal intervention into the segmentation process. Moreover, we design appropriate posterior probability constraints to effectively train the distributions of confusion factors. For the distributions to effectively guide the segmentation and mitigate and eliminate the Impact of confusion factors on the segmentation, we introduce classical backdoor intervention techniques and analyze their feasibility in the segmentation task. To evaluate the effectiveness of our approach, we conducted extensive experiments on five medical image datasets. The results demonstrate that our method significantly reduces the influence of confusion factors, leading to enhanced segmentation accuracy.
CP-UNet: Contour-based Probabilistic Model for Medical Ultrasound Images Segmentation
Nov 21, 2024Deep learning-based segmentation methods are widely utilized for detecting lesions in ultrasound images. Throughout the imaging procedure, the attenuation and scattering of ultrasound waves cause contour blurring and the formation of artifacts, limiting the clarity of the acquired ultrasound images. To overcome this challenge, we propose a contour-based probabilistic segmentation model CP-UNet, which guides the segmentation network to enhance its focus on contour during decoding. We design a novel down-sampling module to enable the contour probability distribution modeling and encoding stages to acquire global-local features. Furthermore, the Gaussian Mixture Model utilizes optimized features to model the contour distribution, capturing the uncertainty of lesion boundaries. Extensive experiments with several state-of-the-art deep learning segmentation methods on three ultrasound image datasets show that our method performs better on breast and thyroid lesions segmentation.
Acoustic-to-articulatory Inversion based on Speech Decomposition and Auxiliary Feature
Apr 02, 2022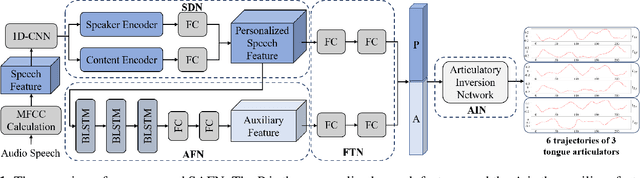
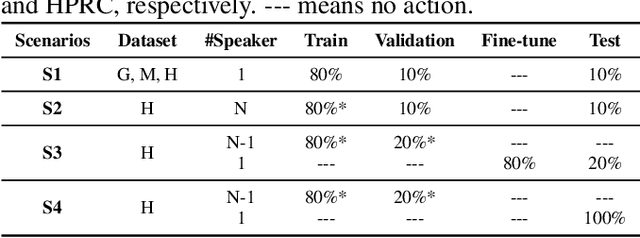
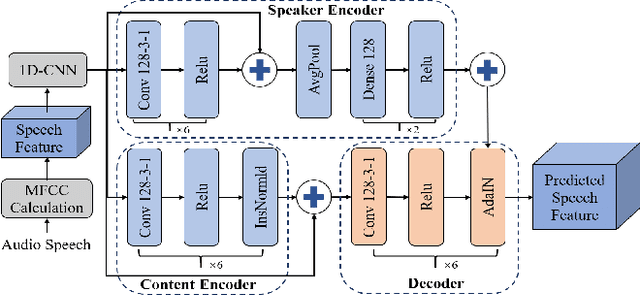
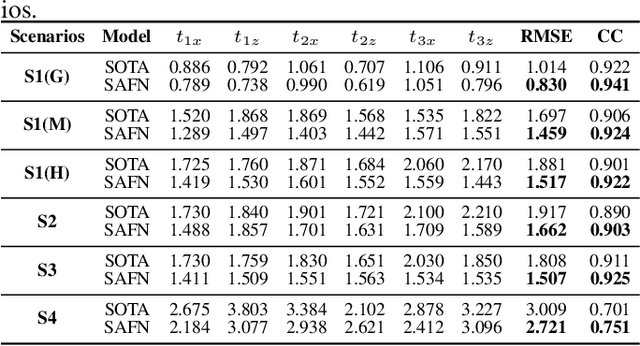
Acoustic-to-articulatory inversion (AAI) is to obtain the movement of articulators from speech signals. Until now, achieving a speaker-independent AAI remains a challenge given the limited data. Besides, most current works only use audio speech as input, causing an inevitable performance bottleneck. To solve these problems, firstly, we pre-train a speech decomposition network to decompose audio speech into speaker embedding and content embedding as the new personalized speech features to adapt to the speaker-independent case. Secondly, to further improve the AAI, we propose a novel auxiliary feature network to estimate the lip auxiliary features from the above personalized speech features. Experimental results on three public datasets show that, compared with the state-of-the-art only using the audio speech feature, the proposed method reduces the average RMSE by 0.25 and increases the average correlation coefficient by 2.0% in the speaker-dependent case. More importantly, the average RMSE decreases by 0.29 and the average correlation coefficient increases by 5.0% in the speaker-independent case.
Scene Learning: Deep Convolutional Networks For Wind Power Prediction by Embedding Turbines into Grid Space
Jul 18, 2018


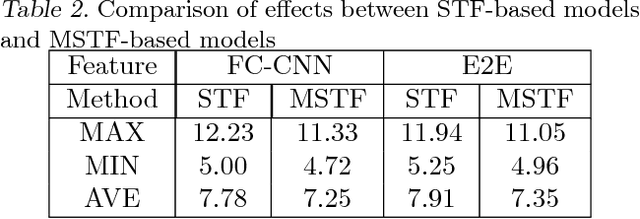
Wind power prediction is of vital importance in wind power utilization. There have been a lot of researches based on the time series of the wind power or speed, but In fact, these time series cannot express the temporal and spatial changes of wind, which fundamentally hinders the advance of wind power prediction. In this paper, a new kind of feature that can describe the process of temporal and spatial variation is proposed, namely, Spatio-Temporal Features. We first map the data collected at each moment from the wind turbine to the plane to form the state map, namely, the scene, according to the relative positions. The scene time series over a period of time is a multi-channel image, i.e. the Spatio-Temporal Features. Based on the Spatio-Temporal Features, the deep convolutional network is applied to predict the wind power, achieving a far better accuracy than the existing methods. Compared with the starge-of-the-art method, the mean-square error (MSE) in our method is reduced by 49.83%, and the average time cost for training models can be shortened by a factor of more than 150.
Speech Emotion Recognition Considering Local Dynamic Features
Mar 21, 2018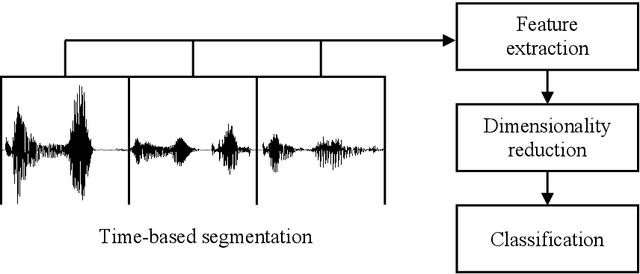

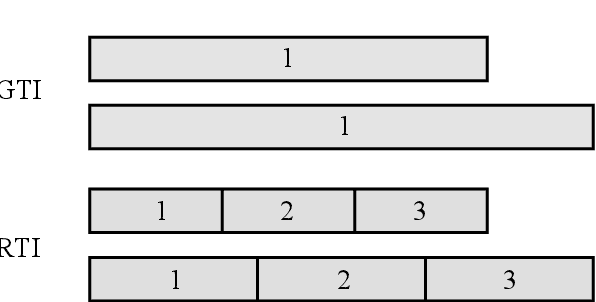

Recently, increasing attention has been directed to the study of the speech emotion recognition, in which global acoustic features of an utterance are mostly used to eliminate the content differences. However, the expression of speech emotion is a dynamic process, which is reflected through dynamic durations, energies, and some other prosodic information when one speaks. In this paper, a novel local dynamic pitch probability distribution feature, which is obtained by drawing the histogram, is proposed to improve the accuracy of speech emotion recognition. Compared with most of the previous works using global features, the proposed method takes advantage of the local dynamic information conveyed by the emotional speech. Several experiments on Berlin Database of Emotional Speech are conducted to verify the effectiveness of the proposed method. The experimental results demonstrate that the local dynamic information obtained with the proposed method is more effective for speech emotion recognition than the traditional global features.