 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Attention Guidance Mechanism for Handwritten Mathematical Expression Recognition
Mar 05, 2024Handwritten mathematical expression recognition (HMER) is challenging in image-to-text tasks due to the complex layouts of mathematical expressions and suffers from problems including over-parsing and under-parsing. To solve these, previous HMER methods improve the attention mechanism by utilizing historical alignment information. However, this approach has limitations in addressing under-parsing since it cannot correct the erroneous attention on image areas that should be parsed at subsequent decoding steps. This faulty attention causes the attention module to incorporate future context into the current decoding step, thereby confusing the alignment process. To address this issue, we propose an attention guidance mechanism to explicitly suppress attention weights in irrelevant areas and enhance the appropriate ones, thereby inhibiting access to information outside the intended context. Depending on the type of attention guidance, we devise two complementary approaches to refine attention weights: self-guidance that coordinates attention of multiple heads and neighbor-guidance that integrates attention from adjacent time steps. Experiments show that our method outperforms existing state-of-the-art methods, achieving expression recognition rates of 60.75% / 61.81% / 63.30% on the CROHME 2014/ 2016/ 2019 datasets.
Omni Aggregation Networks for Lightweight Image Super-Resolution
Apr 24, 2023



While lightweight ViT framework has made tremendous progress in image super-resolution, its uni-dimensional self-attention modeling, as well as homogeneous aggregation scheme, limit its effective receptive field (ERF) to include more comprehensive interactions from both spatial and channel dimensions. To tackle these drawbacks, this work proposes two enhanced components under a new Omni-SR architecture. First, an Omni Self-Attention (OSA) block is proposed based on dense interaction principle, which can simultaneously model pixel-interaction from both spatial and channel dimensions, mining the potential correlations across omni-axis (i.e., spatial and channel). Coupling with mainstream window partitioning strategies, OSA can achieve superior performance with compelling computational budgets. Second, a multi-scale interaction scheme is proposed to mitigate sub-optimal ERF (i.e., premature saturation) in shallow models, which facilitates local propagation and meso-/global-scale interactions, rendering an omni-scale aggregation building block. Extensive experiments demonstrate that Omni-SR achieves record-high performance on lightweight super-resolution benchmarks (e.g., 26.95 dB@Urban100 $\times 4$ with only 792K parameters). Our code is available at \url{https://github.com/Francis0625/Omni-SR}.
3DQD: Generalized Deep 3D Shape Prior via Part-Discretized Diffusion Process
Mar 18, 2023


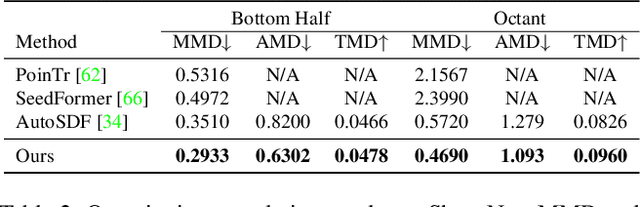
We develop a generalized 3D shape generation prior model, tailored for multiple 3D tasks including unconditional shape generation, point cloud completion, and cross-modality shape generation, etc. On one hand, to precisely capture local fine detailed shape information, a vector quantized variational autoencoder (VQ-VAE) is utilized to index local geometry from a compactly learned codebook based on a broad set of task training data. On the other hand, a discrete diffusion generator is introduced to model the inherent structural dependencies among different tokens. In the meantime, a multi-frequency fusion module (MFM) is developed to suppress high-frequency shape feature fluctuations, guided by multi-frequency contextual information. The above designs jointly equip our proposed 3D shape prior model with high-fidelity, diverse features as well as the capability of cross-modality alignment, and extensive experiments have demonstrated superior performances on various 3D shape generation tasks.