 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedRG: Unleashing the Representation Geometry for Federated Learning with Noisy Clients
Mar 20, 2026Federated learning (FL) suffers from performance degradation due to the inevitable presence of noisy annotations in distributed scenarios. Existing approaches have advanced in distinguishing noisy samples from the dataset for label correction by leveraging loss values. However, noisy samples recognition relying on scalar loss lacks reliability for FL under heterogeneous scenarios. In this paper, we rethink this paradigm from a representation perspective and propose \method~(\textbf{Fed}erated under \textbf{R}epresentation \textbf{G}emometry), which follows \textbf{the principle of ``representation geometry priority''} to recognize noisy labels. Firstly, \method~creates label-agnostic spherical representations by using self-supervision. It then iteratively fits a spherical von Mises-Fisher (vMF) mixture model to this geometry using previously identified clean samples to capture semantic clusters. This geometric evidence is integrated with a semantic-label soft mapping mechanism to derive a distribution divergence between the label-free and annotated label-conditioned feature space, which robustly identifies noisy samples and updates the vMF mixture model with the newly separated clean dataset. Lastly, we employ an additional personalized noise absorption matrix on noisy labels to achieve robust optimization. Extensive experimental results demonstrate that \method~significantly outperforms state-of-the-art methods for FL with data heterogeneity under diverse noisy clients scenarios.
MemFly: On-the-Fly Memory Optimization via Information Bottleneck
Feb 08, 2026Long-term memory enables large language model agents to tackle complex tasks through historical interactions. However, existing frameworks encounter a fundamental dilemma between compressing redundant information efficiently and maintaining precise retrieval for downstream tasks. To bridge this gap, we propose MemFly, a framework grounded in information bottleneck principles that facilitates on-the-fly memory evolution for LLMs. Our approach minimizes compression entropy while maximizing relevance entropy via a gradient-free optimizer, constructing a stratified memory structure for efficient storage. To fully leverage MemFly, we develop a hybrid retrieval mechanism that seamlessly integrates semantic, symbolic, and topological pathways, incorporating iterative refinement to handle complex multi-hop queries. Comprehensive experiments demonstrate that MemFly substantially outperforms state-of-the-art baselines in memory coherence, response fidelity, and accuracy.
MimicDreamer: Aligning Human and Robot Demonstrations for Scalable VLA Training
Sep 26, 2025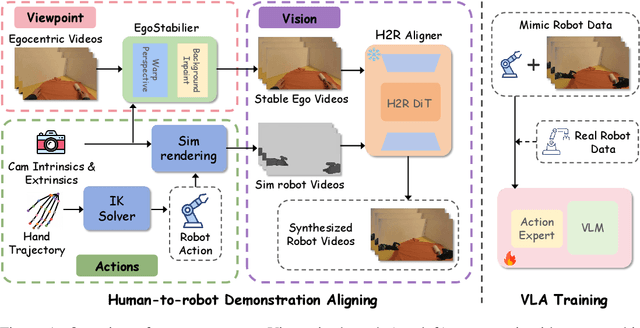

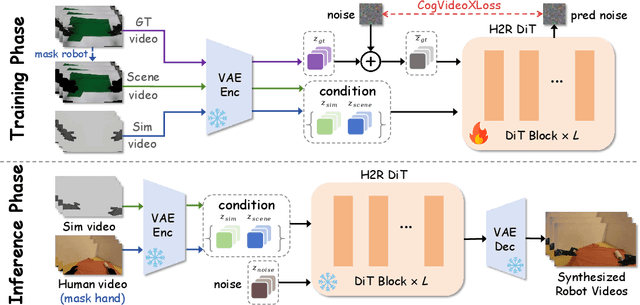
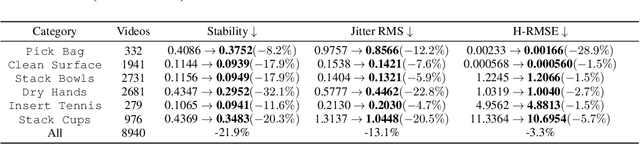
Vision Language Action (VLA) models derive their generalization capability from diverse training data, yet collecting embodied robot interaction data remains prohibitively expensive. In contrast, human demonstration videos are far more scalable and cost-efficient to collect, and recent studies confirm their effectiveness in training VLA models. However, a significant domain gap persists between human videos and robot-executed videos, including unstable camera viewpoints, visual discrepancies between human hands and robotic arms, and differences in motion dynamics. To bridge this gap, we propose MimicDreamer, a framework that turns fast, low-cost human demonstrations into robot-usable supervision by jointly aligning vision, viewpoint, and actions to directly support policy training. For visual alignment, we propose H2R Aligner, a video diffusion model that generates high-fidelity robot demonstration videos by transferring motion from human manipulation footage. For viewpoint stabilization, EgoStabilizer is proposed, which canonicalizes egocentric videos via homography and inpaints occlusions and distortions caused by warping. For action alignment, we map human hand trajectories to the robot frame and apply a constrained inverse kinematics solver to produce feasible, low-jitter joint commands with accurate pose tracking. Empirically, VLA models trained purely on our synthesized human-to-robot videos achieve few-shot execution on real robots. Moreover, scaling training with human data significantly boosts performance compared to models trained solely on real robot data; our approach improves the average success rate by 14.7\% across six representative manipulation tasks.
LearnAlign: Reasoning Data Selection for Reinforcement Learning in Large Language Models Based on Improved Gradient Alignment
Jun 13, 2025Reinforcement learning (RL) has become a key technique for enhancing LLMs' reasoning abilities, yet its data inefficiency remains a major bottleneck. To address this critical yet challenging issue, we present a novel gradient-alignment-based method, named LearnAlign, which intelligently selects the learnable and representative training reasoning data for RL post-training. To overcome the well-known issue of response-length bias in gradient norms, we introduce the data learnability based on the success rate, which can indicate the learning potential of each data point. Experiments across three mathematical reasoning benchmarks demonstrate that our method significantly reduces training data requirements while achieving minor performance degradation or even improving performance compared to full-data training. For example, it reduces data requirements by up to 1,000 data points with better performance (77.53%) than that on the full dataset on GSM8K benchmark (77.04%). Furthermore, we show its effectiveness in the staged RL setting. This work provides valuable insights into data-efficient RL post-training and establishes a foundation for future research in optimizing reasoning data selection.To facilitate future work, we will release code.
HumanDreamer: Generating Controllable Human-Motion Videos via Decoupled Generation
Apr 01, 2025Human-motion video generation has been a challenging task, primarily due to the difficulty inherent in learning human body movements. While some approaches have attempted to drive human-centric video generation explicitly through pose control, these methods typically rely on poses derived from existing videos, thereby lacking flexibility. To address this, we propose HumanDreamer, a decoupled human video generation framework that first generates diverse poses from text prompts and then leverages these poses to generate human-motion videos. Specifically, we propose MotionVid, the largest dataset for human-motion pose generation. Based on the dataset, we present MotionDiT, which is trained to generate structured human-motion poses from text prompts. Besides, a novel LAMA loss is introduced, which together contribute to a significant improvement in FID by 62.4%, along with respective enhancements in R-precision for top1, top2, and top3 by 41.8%, 26.3%, and 18.3%, thereby advancing both the Text-to-Pose control accuracy and FID metrics. Our experiments across various Pose-to-Video baselines demonstrate that the poses generated by our method can produce diverse and high-quality human-motion videos. Furthermore, our model can facilitate other downstream tasks, such as pose sequence prediction and 2D-3D motion lifting.
Beyond Traditional Threats: A Persistent Backdoor Attack on Federated Learning
Apr 26, 2024Backdoors on federated learning will be diluted by subsequent benign updates. This is reflected in the significant reduction of attack success rate as iterations increase, ultimately failing. We use a new metric to quantify the degree of this weakened backdoor effect, called attack persistence. Given that research to improve this performance has not been widely noted,we propose a Full Combination Backdoor Attack (FCBA) method. It aggregates more combined trigger information for a more complete backdoor pattern in the global model. Trained backdoored global model is more resilient to benign updates, leading to a higher attack success rate on the test set. We test on three datasets and evaluate with two models across various settings. FCBA's persistence outperforms SOTA federated learning backdoor attacks. On GTSRB, postattack 120 rounds, our attack success rate rose over 50% from baseline. The core code of our method is available at https://github.com/PhD-TaoLiu/FCBA.
Robust Training of Federated Models with Extremely Label Deficiency
Feb 22, 2024Federated semi-supervised learning (FSSL) has emerged as a powerful paradigm for collaboratively training machine learning models using distributed data with label deficiency. Advanced FSSL methods predominantly focus on training a single model on each client. However, this approach could lead to a discrepancy between the objective functions of labeled and unlabeled data, resulting in gradient conflicts. To alleviate gradient conflict, we propose a novel twin-model paradigm, called Twin-sight, designed to enhance mutual guidance by providing insights from different perspectives of labeled and unlabeled data. In particular, Twin-sight concurrently trains a supervised model with a supervised objective function while training an unsupervised model using an unsupervised objective function. To enhance the synergy between these two models, Twin-sight introduces a neighbourhood-preserving constraint, which encourages the preservation of the neighbourhood relationship among data features extracted by both models. Our comprehensive experiments on four benchmark datasets provide substantial evidence that Twin-sight can significantly outperform state-of-the-art methods across various experimental settings, demonstrating the efficacy of the proposed Twin-sight.
FedFed: Feature Distillation against Data Heterogeneity in Federated Learning
Oct 08, 2023



Federated learning (FL) typically faces data heterogeneity, i.e., distribution shifting among clients. Sharing clients' information has shown great potentiality in mitigating data heterogeneity, yet incurs a dilemma in preserving privacy and promoting model performance. To alleviate the dilemma, we raise a fundamental question: \textit{Is it possible to share partial features in the data to tackle data heterogeneity?} In this work, we give an affirmative answer to this question by proposing a novel approach called {\textbf{Fed}erated \textbf{Fe}ature \textbf{d}istillation} (FedFed). Specifically, FedFed partitions data into performance-sensitive features (i.e., greatly contributing to model performance) and performance-robust features (i.e., limitedly contributing to model performance). The performance-sensitive features are globally shared to mitigate data heterogeneity, while the performance-robust features are kept locally. FedFed enables clients to train models over local and shared data. Comprehensive experiments demonstrate the efficacy of FedFed in promoting model performance.
* 32 pages
RoSGAS: Adaptive Social Bot Detection with Reinforced Self-Supervised GNN Architecture Search
Jun 14, 2022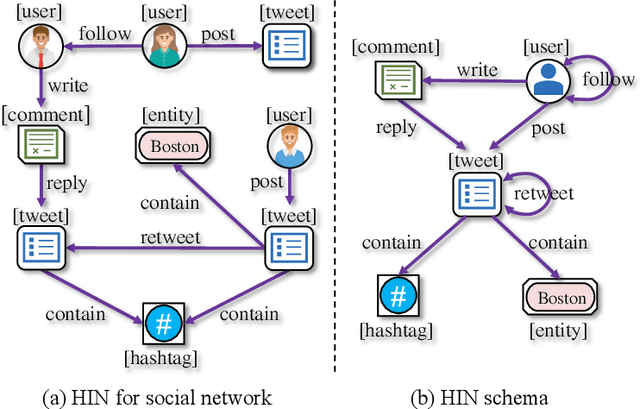
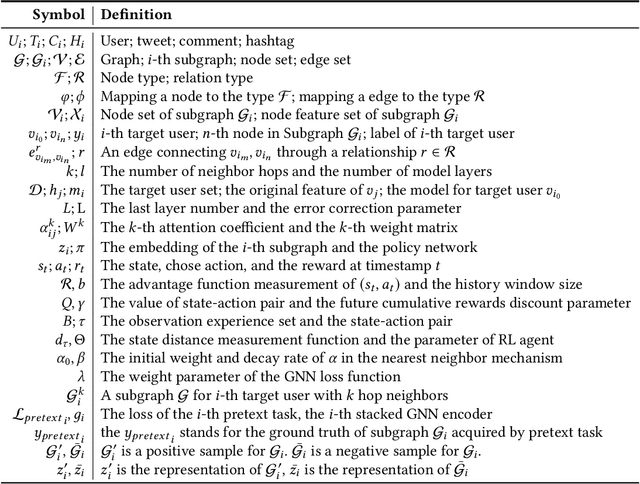
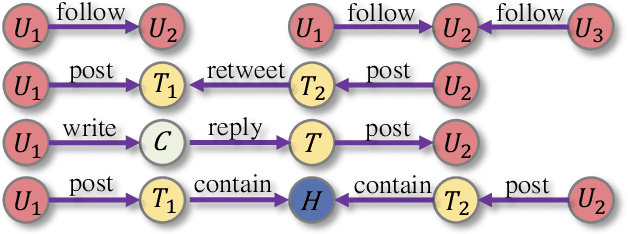
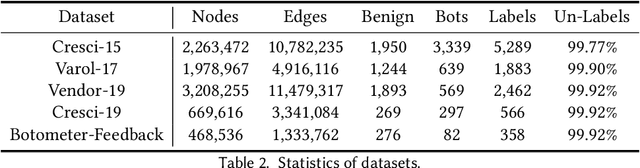
Social bots are referred to as the automated accounts on social networks that make attempts to behave like human. While Graph Neural Networks (GNNs) has been massively applied to the field of social bot detection, a huge amount of domain expertise and prior knowledge is heavily engaged in the state-of-the art approaches to design a dedicated neural network architecture for a specific classification task. Involving oversized nodes and network layers in the model design, however, usually causes the over-smoothing problem and the lack of embedding discrimination. In this paper, we propose RoSGAS, a novel Reinforced and Self-supervised GNN Architecture Search framework to adaptively pinpoint the most suitable multi-hop neighborhood and the number of layers in the GNN architecture. More specifically, we consider the social bot detection problem as a user-centric subgraph embedding and classification task. We exploit heterogeneous information network to present the user connectivity by leveraging account metadata, relationships, behavioral features and content features. RoSGAS uses a multi-agent deep reinforcement learning (RL) mechanism for navigating the search of optimal neighborhood and network layers to learn individually the subgraph embedding for each target user. A nearest neighbor mechanism is developed for accelerating the RL training process, and RoSGAS can learn more discriminative subgraph embedding with the aid of self-supervised learning. Experiments on 5 Twitter datasets show that RoSGAS outperforms the state-of-the-art approaches in terms of accuracy, training efficiency and stability, and has better generalization when handling unseen samples.