 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal and Semantic Zero-inflated Urban Anomaly Prediction
Apr 04, 2023



Urban anomaly predictions, such as traffic accident prediction and crime prediction, are of vital importance to smart city security and maintenance. Existing methods typically use deep learning to capture the intra-dependencies in spatial and temporal dimensions. However, numerous key challenges remain unsolved, for instance, sparse zero-inflated data due to urban anomalies occurring with low frequency (which can lead to poor performance on real-world datasets), and both intra- and inter-dependencies of abnormal patterns across spatial, temporal, and semantic dimensions. Moreover, a unified approach to predict multiple kinds of anomaly is left to explore. In this paper, we propose STS to jointly capture the intra- and inter-dependencies between the patterns and the influential factors in three dimensions. Further, we use a multi-task prediction module with a customized loss function to solve the zero-inflated issue. To verify the effectiveness of the model, we apply it to two urban anomaly prediction tasks, crime prediction and traffic accident risk prediction, respectively. Experiments on two application scenarios with four real-world datasets demonstrate the superiority of STS, which outperforms state-of-the-art methods in the mean absolute error and the root mean square error by 37.88% and 18.10% on zero-inflated datasets, and, 60.32% and 37.28% on non-zero datasets, respectively.
TKN: Transformer-based Keypoint Prediction Network For Real-time Video Prediction
Mar 20, 2023



Video prediction is a complex time-series forecasting task with great potential in many use cases. However, conventional methods overemphasize accuracy while ignoring the slow prediction speed caused by complicated model structures that learn too much redundant information with excessive GPU memory consumption. Furthermore, conventional methods mostly predict frames sequentially (frame-by-frame) and thus are hard to accelerate. Consequently, valuable use cases such as real-time danger prediction and warning cannot achieve fast enough inference speed to be applicable in reality. Therefore, we propose a transformer-based keypoint prediction neural network (TKN), an unsupervised learning method that boost the prediction process via constrained information extraction and parallel prediction scheme. TKN is the first real-time video prediction solution to our best knowledge, while significantly reducing computation costs and maintaining other performance. Extensive experiments on KTH and Human3.6 datasets demonstrate that TKN predicts 11 times faster than existing methods while reducing memory consumption by 17.4% and achieving state-of-the-art prediction performance on average.
UniRel: Unified Representation and Interaction for Joint Relational Triple Extraction
Nov 16, 2022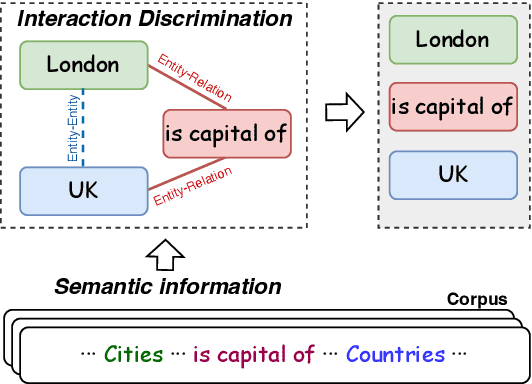
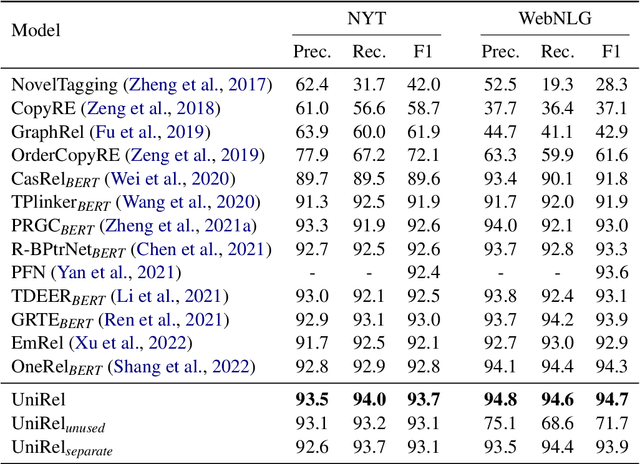
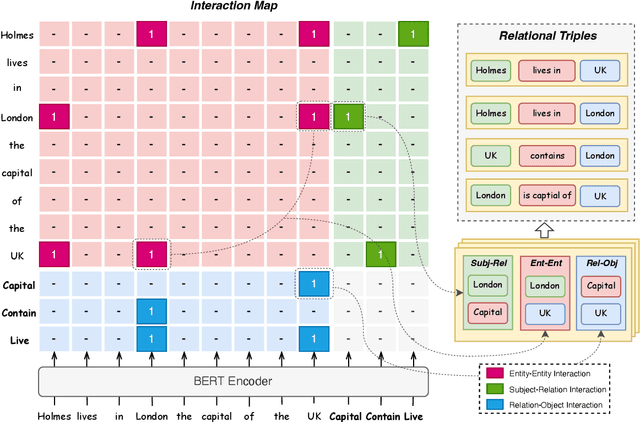
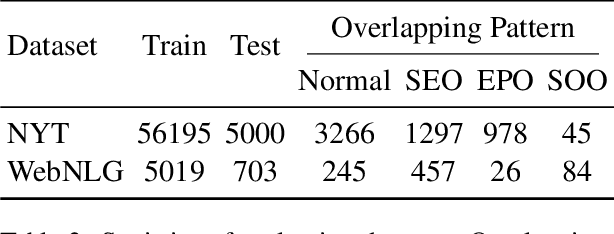
Relational triple extraction is challenging for its difficulty in capturing rich correlations between entities and relations. Existing works suffer from 1) heterogeneous representations of entities and relations, and 2) heterogeneous modeling of entity-entity interactions and entity-relation interactions. Therefore, the rich correlations are not fully exploited by existing works. In this paper, we propose UniRel to address these challenges. Specifically, we unify the representations of entities and relations by jointly encoding them within a concatenated natural language sequence, and unify the modeling of interactions with a proposed Interaction Map, which is built upon the off-the-shelf self-attention mechanism within any Transformer block. With comprehensive experiments on two popular relational triple extraction datasets, we demonstrate that UniRel is more effective and computationally efficient. The source code is available at https://github.com/wtangdev/UniRel.
Celeritas: Fast Optimizer for Large Dataflow Graphs
Jul 30, 2022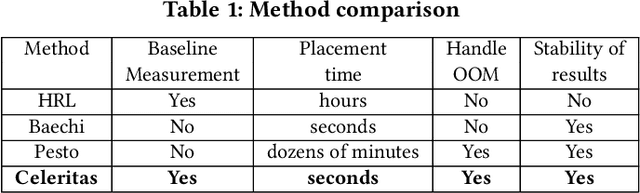
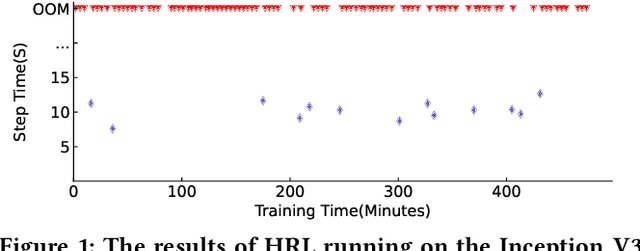
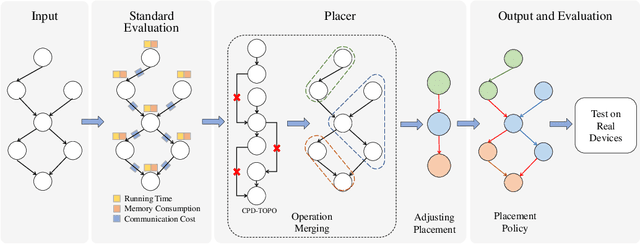
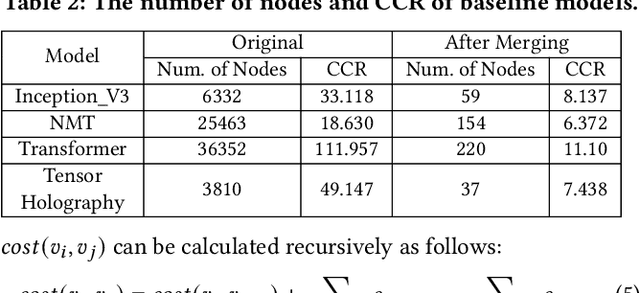
The rapidly enlarging neural network models are becoming increasingly challenging to run on a single device. Hence model parallelism over multiple devices is critical to guarantee the efficiency of training large models. Recent proposals fall short either in long processing time or poor performance. Therefore, we propose Celeritas, a fast framework for optimizing device placement for large models. Celeritas employs a simple but efficient model parallelization strategy in the Standard Evaluation, and generates placement policies through a series of scheduling algorithms. We conduct experiments to deploy and evaluate Celeritas on numerous large models. The results show that Celeritas not only reduces the placement policy generation time by 26.4\% but also improves the model running time by 34.2\% compared to most advanced methods.
RoSGAS: Adaptive Social Bot Detection with Reinforced Self-Supervised GNN Architecture Search
Jun 14, 2022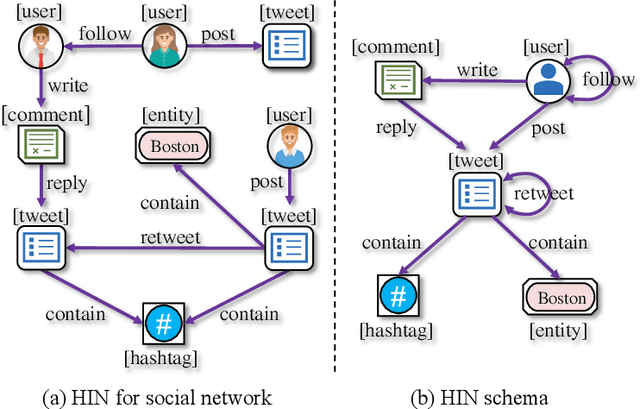
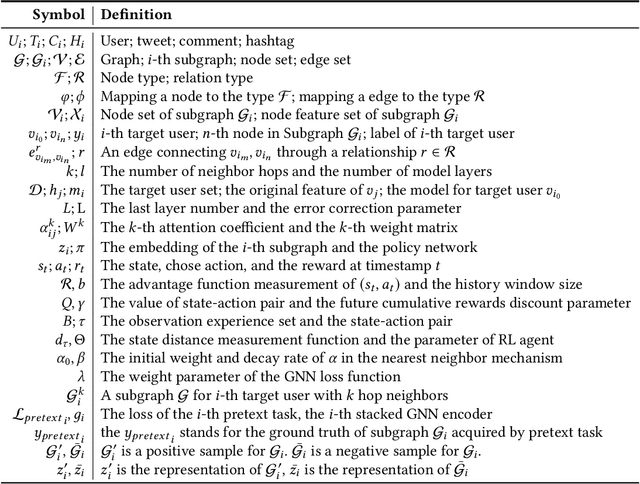
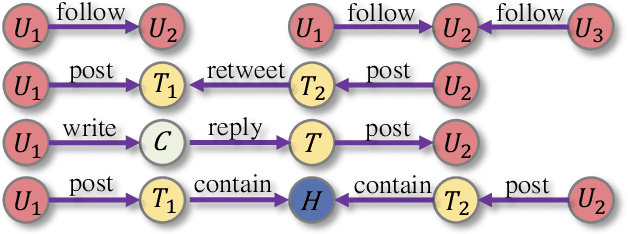
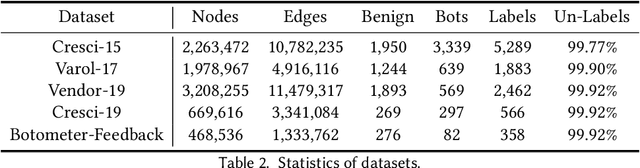
Social bots are referred to as the automated accounts on social networks that make attempts to behave like human. While Graph Neural Networks (GNNs) has been massively applied to the field of social bot detection, a huge amount of domain expertise and prior knowledge is heavily engaged in the state-of-the art approaches to design a dedicated neural network architecture for a specific classification task. Involving oversized nodes and network layers in the model design, however, usually causes the over-smoothing problem and the lack of embedding discrimination. In this paper, we propose RoSGAS, a novel Reinforced and Self-supervised GNN Architecture Search framework to adaptively pinpoint the most suitable multi-hop neighborhood and the number of layers in the GNN architecture. More specifically, we consider the social bot detection problem as a user-centric subgraph embedding and classification task. We exploit heterogeneous information network to present the user connectivity by leveraging account metadata, relationships, behavioral features and content features. RoSGAS uses a multi-agent deep reinforcement learning (RL) mechanism for navigating the search of optimal neighborhood and network layers to learn individually the subgraph embedding for each target user. A nearest neighbor mechanism is developed for accelerating the RL training process, and RoSGAS can learn more discriminative subgraph embedding with the aid of self-supervised learning. Experiments on 5 Twitter datasets show that RoSGAS outperforms the state-of-the-art approaches in terms of accuracy, training efficiency and stability, and has better generalization when handling unseen samples.
Towards User-Centered Metrics for Trustworthy AI in Immersive Cyberspace
Feb 22, 2022AI plays a key role in current cyberspace and future immersive ecosystems that pinpoint user experiences. Thus, the trustworthiness of such AI systems is vital as failures in these systems can cause serious user harm. Although there are related works on exploring trustworthy AI (TAI) metrics in the current cyberspace, ecosystems towards user-centered services, such as the metaverse, are much more complicated in terms of system performance and user experience assessment, thus posing challenges for the applicability of existing approaches. Thus, we give an overlook on fairness, privacy and robustness, across the historical path from existing approaches. Eventually, we propose a research agenda towards systematic yet user-centered TAI in immersive ecosystems.
Time-aware Path Reasoning on Knowledge Graph for Recommendation
Aug 05, 2021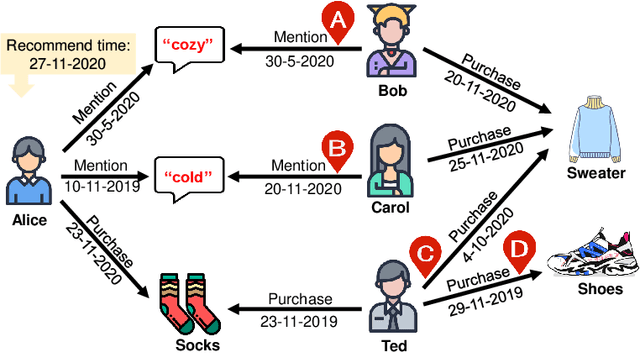
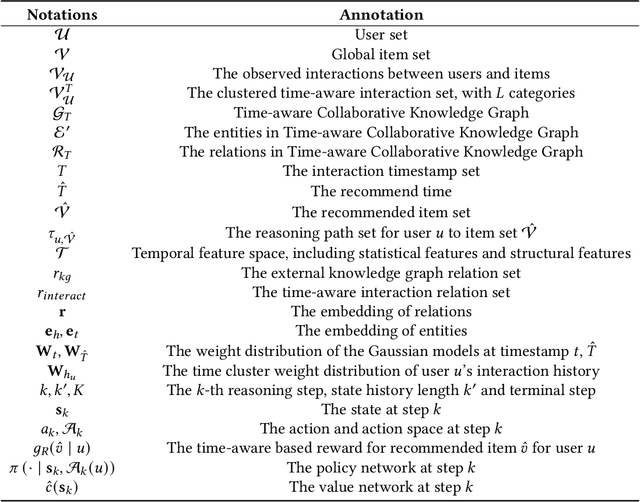
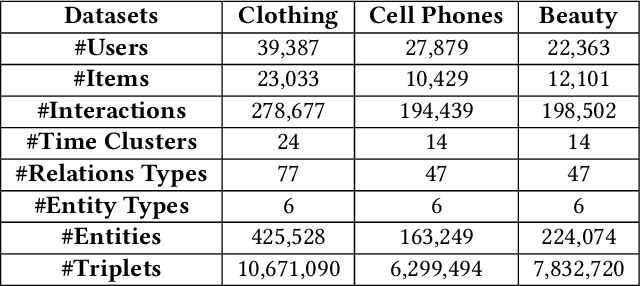
Reasoning on knowledge graph (KG) has been studied for explainable recommendation due to it's ability of providing explicit explanations. However, current KG-based explainable recommendation methods unfortunately ignore the temporal information (such as purchase time, recommend time, etc.), which may result in unsuitable explanations. In this work, we propose a novel Time-aware Path reasoning for Recommendation (TPRec for short) method, which leverages the potential of temporal information to offer better recommendation with plausible explanations. First, we present an efficient time-aware interaction relation extraction component to construct collaborative knowledge graph with time-aware interactions (TCKG for short), and then introduce a novel time-aware path reasoning method for recommendation. We conduct extensive experiments on three real-world datasets. The results demonstrate that the proposed TPRec could successfully employ TCKG to achieve substantial gains and improve the quality of explainable recommendation.
Dual Adversarial Semantics-Consistent Network for Generalized Zero-Shot Learning
Jul 12, 2019

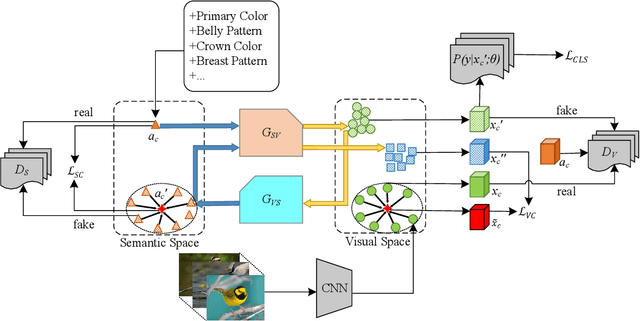
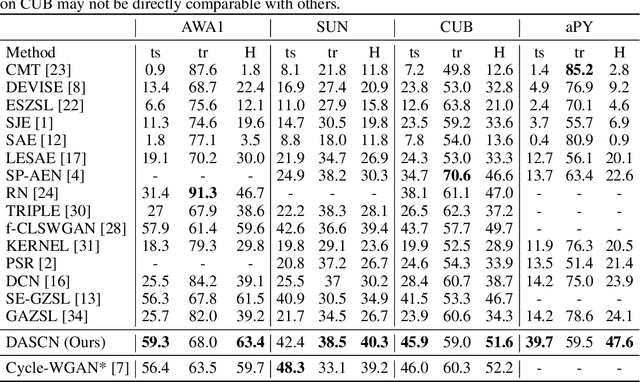
Generalized zero-shot learning (GZSL) is a challenging class of vision and knowledge transfer problems in which both seen and unseen classes appear during testing. Existing GZSL approaches either suffer from semantic loss and discard discriminative information at the embedding stage, or cannot guarantee the visual-semantic interactions. To address these limitations, we propose the Dual Adversarial Semantics-Consistent Network (DASCN), which learns primal and dual Generative Adversarial Networks (GANs) in a unified framework for GZSL. In particular, the primal GAN learns to synthesize inter-class discriminative and semantics-preserving visual features from both the semantic representations of seen/unseen classes and the ones reconstructed by the dual GAN. The dual GAN enforces the synthetic visual features to represent prior semantic knowledge well via semantics-consistent adversarial learning. To the best of our knowledge, this is the first work that employs a novel dual-GAN mechanism for GZSL. Extensive experiments show that our approach achieves significant improvements over the state-of-the-art approaches.
Joint Modeling of Dense and Incomplete Trajectories for Citywide Traffic Volume Inference
Feb 25, 2019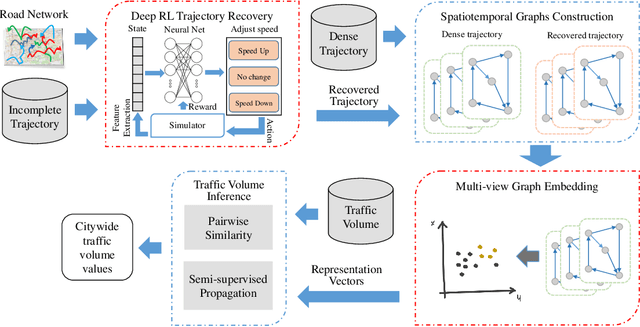

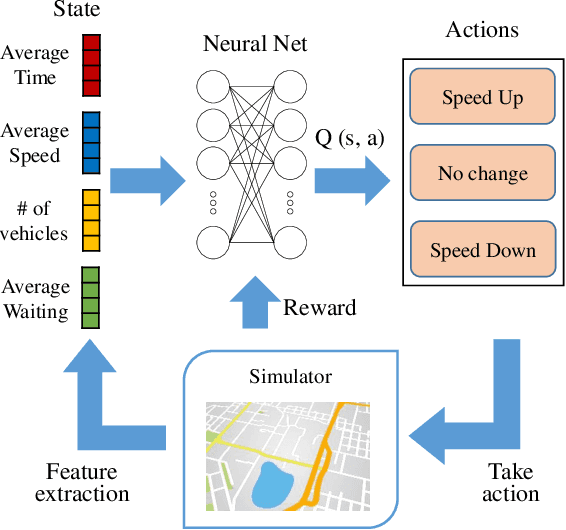
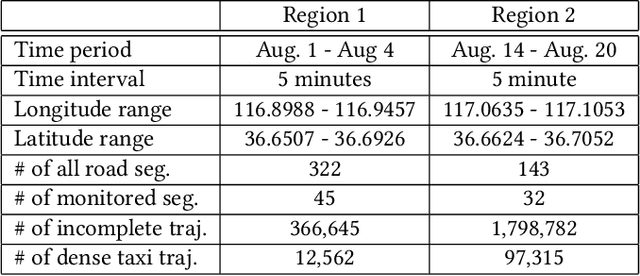
Real-time traffic volume inference is key to an intelligent city. It is a challenging task because accurate traffic volumes on the roads can only be measured at certain locations where sensors are installed. Moreover, the traffic evolves over time due to the influences of weather, events, holidays, etc. Existing solutions to the traffic volume inference problem often rely on dense GPS trajectories, which inevitably fail to account for the vehicles which carry no GPS devices or have them turned off. Consequently, the results are biased to taxicabs because they are almost always online for GPS tracking. In this paper, we propose a novel framework for the citywide traffic volume inference using both dense GPS trajectories and incomplete trajectories captured by camera surveillance systems. Our approach employs a high-fidelity traffic simulator and deep reinforcement learning to recover full vehicle movements from the incomplete trajectories. In order to jointly model the recovered trajectories and dense GPS trajectories, we construct spatiotemporal graphs and use multi-view graph embedding to encode the multi-hop correlations between road segments into real-valued vectors. Finally, we infer the citywide traffic volumes by propagating the traffic values of monitored road segments to the unmonitored ones through masked pairwise similarities. Extensive experiments with two big regions in a provincial capital city in China verify the effectiveness of our approach.