 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCeleritas: Fast Optimizer for Large Dataflow Graphs
Paper and Code
Jul 30, 2022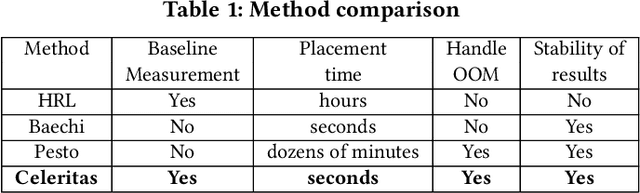
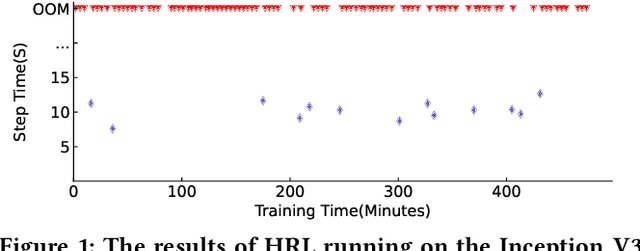
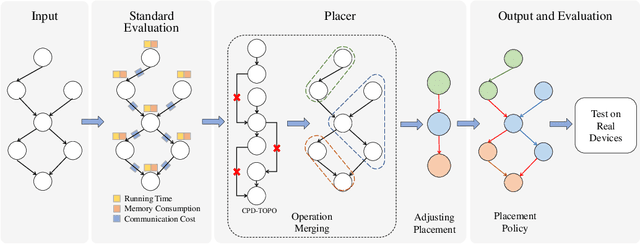
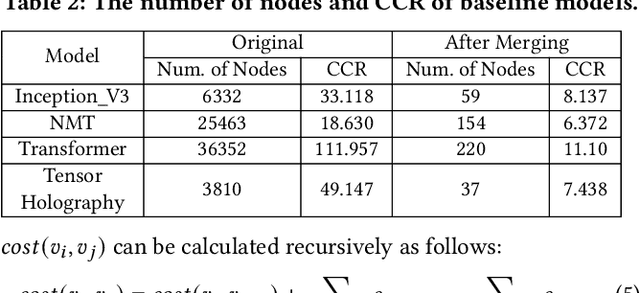
The rapidly enlarging neural network models are becoming increasingly challenging to run on a single device. Hence model parallelism over multiple devices is critical to guarantee the efficiency of training large models. Recent proposals fall short either in long processing time or poor performance. Therefore, we propose Celeritas, a fast framework for optimizing device placement for large models. Celeritas employs a simple but efficient model parallelization strategy in the Standard Evaluation, and generates placement policies through a series of scheduling algorithms. We conduct experiments to deploy and evaluate Celeritas on numerous large models. The results show that Celeritas not only reduces the placement policy generation time by 26.4\% but also improves the model running time by 34.2\% compared to most advanced methods.