 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnAlign: Reasoning Data Selection for Reinforcement Learning in Large Language Models Based on Improved Gradient Alignment
Jun 13, 2025Reinforcement learning (RL) has become a key technique for enhancing LLMs' reasoning abilities, yet its data inefficiency remains a major bottleneck. To address this critical yet challenging issue, we present a novel gradient-alignment-based method, named LearnAlign, which intelligently selects the learnable and representative training reasoning data for RL post-training. To overcome the well-known issue of response-length bias in gradient norms, we introduce the data learnability based on the success rate, which can indicate the learning potential of each data point. Experiments across three mathematical reasoning benchmarks demonstrate that our method significantly reduces training data requirements while achieving minor performance degradation or even improving performance compared to full-data training. For example, it reduces data requirements by up to 1,000 data points with better performance (77.53%) than that on the full dataset on GSM8K benchmark (77.04%). Furthermore, we show its effectiveness in the staged RL setting. This work provides valuable insights into data-efficient RL post-training and establishes a foundation for future research in optimizing reasoning data selection.To facilitate future work, we will release code.
Revisiting SLO and Goodput Metrics in LLM Serving
Oct 18, 2024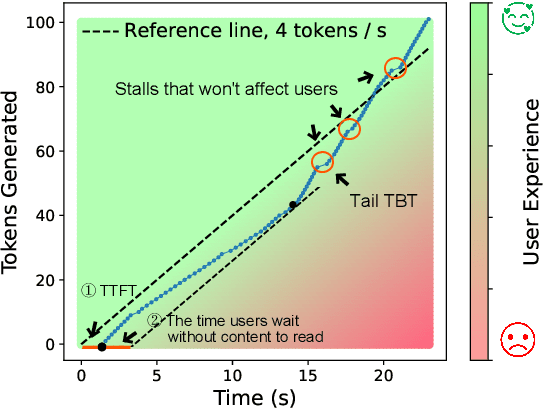

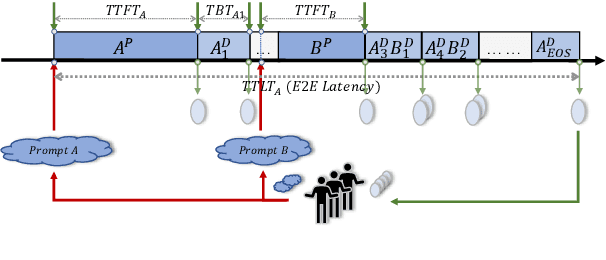
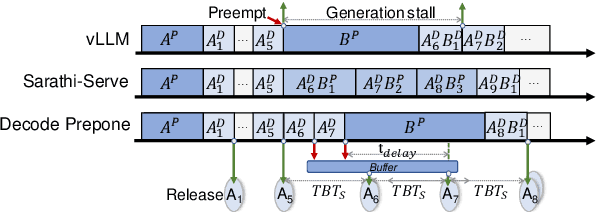
Large language models (LLMs) have achieved remarkable performance and are widely deployed in various applications, while the serving of LLM inference has raised concerns about user experience and serving throughput. Accordingly, service level objectives (SLOs) and goodput-the number of requests that meet SLOs per second-are introduced to evaluate the performance of LLM serving. However, existing metrics fail to capture the nature of user experience. We observe two ridiculous phenomena in existing metrics: 1) delaying token delivery can smooth the tail time between tokens (tail TBT) of a request and 2) dropping the request that fails to meet the SLOs midway can improve goodput. In this paper, we revisit SLO and goodput metrics in LLM serving and propose a unified metric framework smooth goodput including SLOs and goodput to reflect the nature of user experience in LLM serving. The framework can adapt to specific goals of different tasks by setting parameters. We re-evaluate the performance of different LLM serving systems under multiple workloads based on this unified framework and provide possible directions for future optimization of existing strategies. We hope that this framework can provide a unified standard for evaluating LLM serving and foster researches in the field of LLM serving optimization to move in a cohesive direction.
Content adaptive screen image scaling
Oct 21, 2015
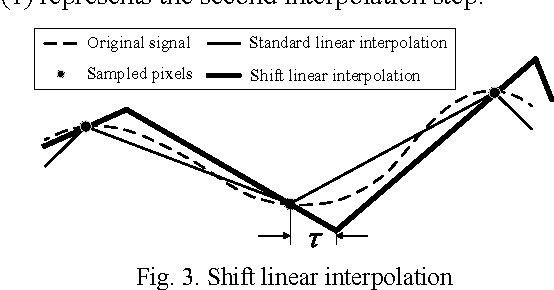
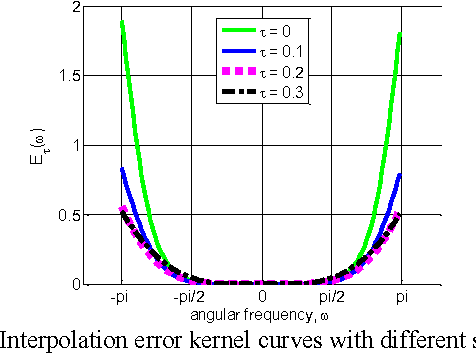
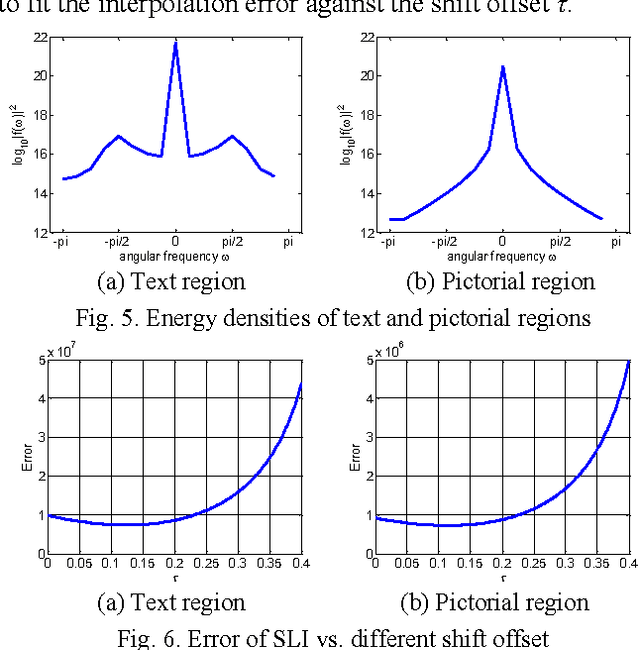
This paper proposes an efficient content adaptive screen image scaling scheme for the real-time screen applications like remote desktop and screen sharing. In the proposed screen scaling scheme, a screen content classification step is first introduced to classify the screen image into text and pictorial regions. Afterward, we propose an adaptive shift linear interpolation algorithm to predict the new pixel values with the shift offset adapted to the content type of each pixel. The shift offset for each screen content type is offline optimized by minimizing the theoretical interpolation error based on the training samples respectively. The proposed content adaptive screen image scaling scheme can achieve good visual quality and also keep the low complexity for real-time applications.
Group $K$-Means
Jan 05, 2015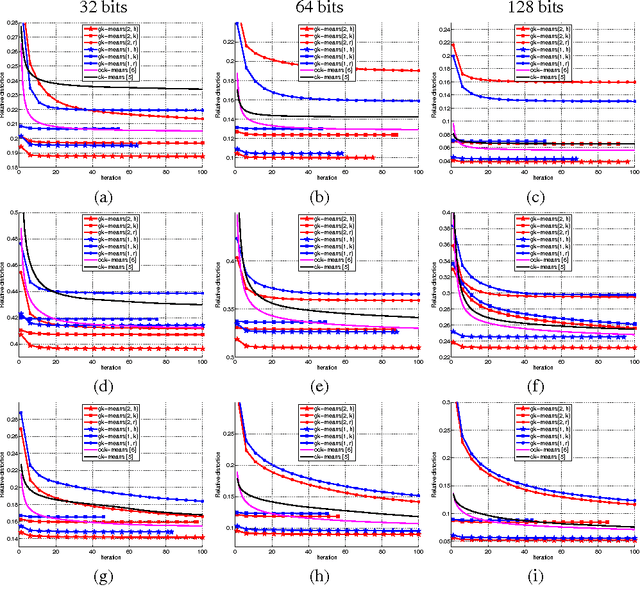
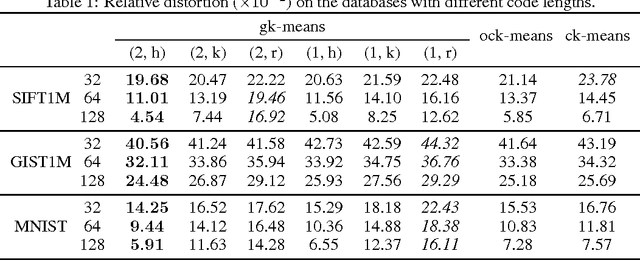
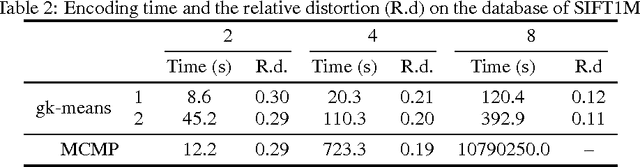
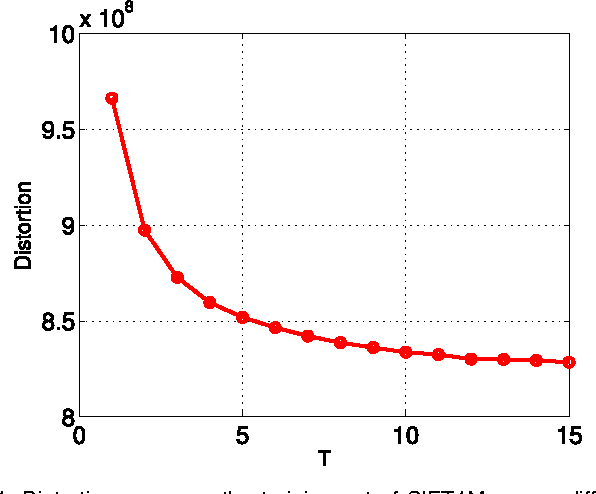
We study how to learn multiple dictionaries from a dataset, and approximate any data point by the sum of the codewords each chosen from the corresponding dictionary. Although theoretically low approximation errors can be achieved by the global solution, an effective solution has not been well studied in practice. To solve the problem, we propose a simple yet effective algorithm \textit{Group $K$-Means}. Specifically, we take each dictionary, or any two selected dictionaries, as a group of $K$-means cluster centers, and then deal with the approximation issue by minimizing the approximation errors. Besides, we propose a hierarchical initialization for such a non-convex problem. Experimental results well validate the effectiveness of the approach.
Optimized Cartesian $K$-Means
May 16, 2014
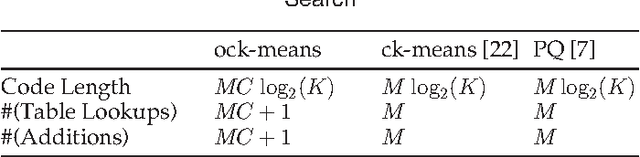
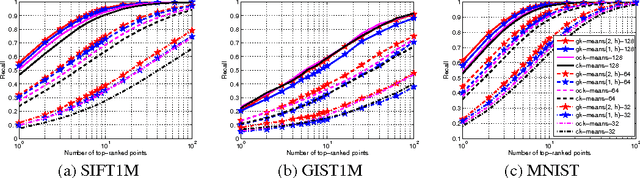
Product quantization-based approaches are effective to encode high-dimensional data points for approximate nearest neighbor search. The space is decomposed into a Cartesian product of low-dimensional subspaces, each of which generates a sub codebook. Data points are encoded as compact binary codes using these sub codebooks, and the distance between two data points can be approximated efficiently from their codes by the precomputed lookup tables. Traditionally, to encode a subvector of a data point in a subspace, only one sub codeword in the corresponding sub codebook is selected, which may impose strict restrictions on the search accuracy. In this paper, we propose a novel approach, named Optimized Cartesian $K$-Means (OCKM), to better encode the data points for more accurate approximate nearest neighbor search. In OCKM, multiple sub codewords are used to encode the subvector of a data point in a subspace. Each sub codeword stems from different sub codebooks in each subspace, which are optimally generated with regards to the minimization of the distortion errors. The high-dimensional data point is then encoded as the concatenation of the indices of multiple sub codewords from all the subspaces. This can provide more flexibility and lower distortion errors than traditional methods. Experimental results on the standard real-life datasets demonstrate the superiority over state-of-the-art approaches for approximate nearest neighbor search.
Fast Neighborhood Graph Search using Cartesian Concatenation
Dec 11, 2013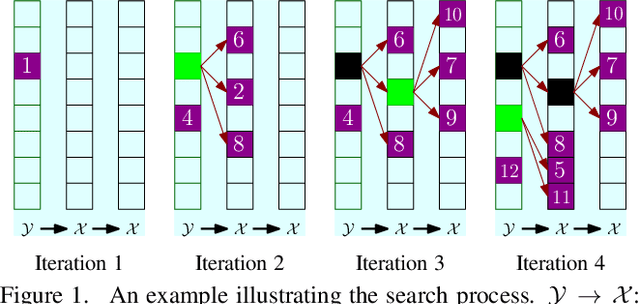
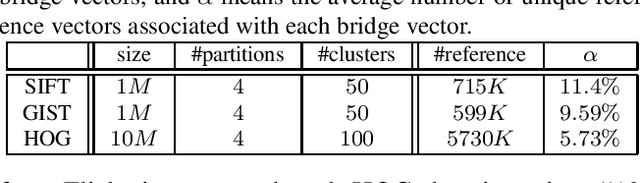
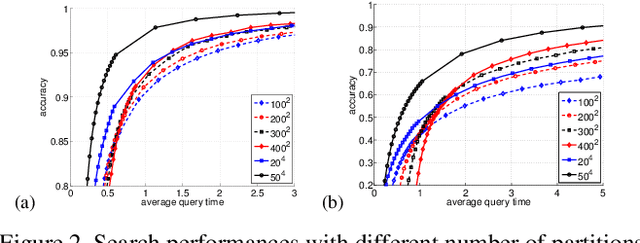
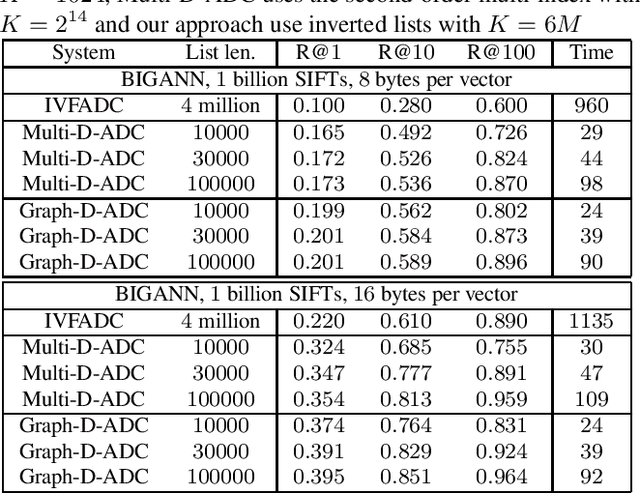
In this paper, we propose a new data structure for approximate nearest neighbor search. This structure augments the neighborhood graph with a bridge graph. We propose to exploit Cartesian concatenation to produce a large set of vectors, called bridge vectors, from several small sets of subvectors. Each bridge vector is connected with a few reference vectors near to it, forming a bridge graph. Our approach finds nearest neighbors by simultaneously traversing the neighborhood graph and the bridge graph in the best-first strategy. The success of our approach stems from two factors: the exact nearest neighbor search over a large number of bridge vectors can be done quickly, and the reference vectors connected to a bridge (reference) vector near the query are also likely to be near the query. Experimental results on searching over large scale datasets (SIFT, GIST and HOG) show that our approach outperforms state-of-the-art ANN search algorithms in terms of efficiency and accuracy. The combination of our approach with the IVFADC system also shows superior performance over the BIGANN dataset of $1$ billion SIFT features compared with the best previously published result.
Fast Approximate $K$-Means via Cluster Closures
Dec 11, 2013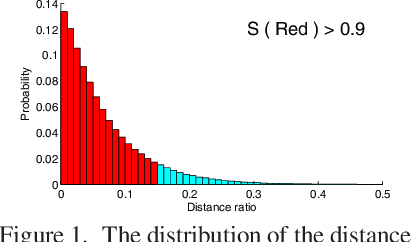
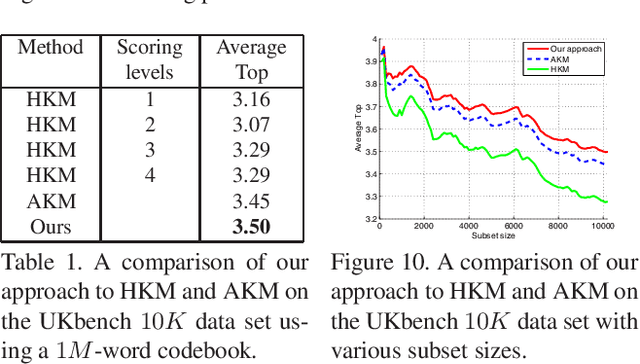
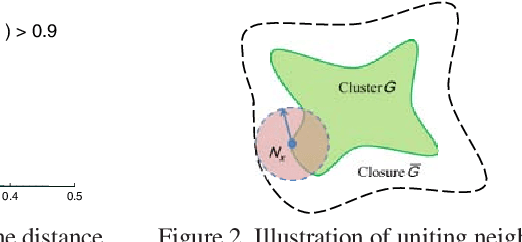
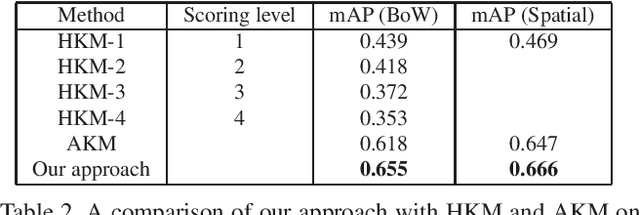
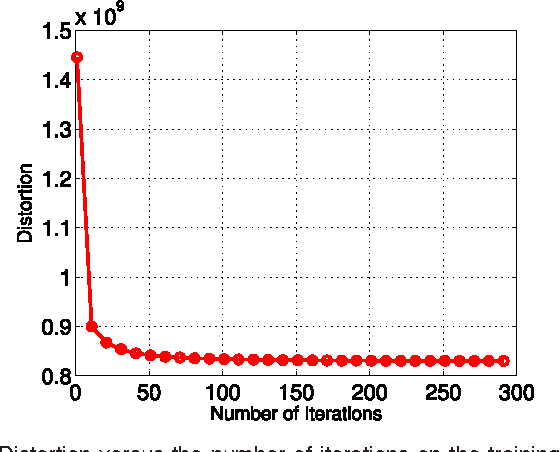
$K$-means, a simple and effective clustering algorithm, is one of the most widely used algorithms in multimedia and computer vision community. Traditional $k$-means is an iterative algorithm---in each iteration new cluster centers are computed and each data point is re-assigned to its nearest center. The cluster re-assignment step becomes prohibitively expensive when the number of data points and cluster centers are large. In this paper, we propose a novel approximate $k$-means algorithm to greatly reduce the computational complexity in the assignment step. Our approach is motivated by the observation that most active points changing their cluster assignments at each iteration are located on or near cluster boundaries. The idea is to efficiently identify those active points by pre-assembling the data into groups of neighboring points using multiple random spatial partition trees, and to use the neighborhood information to construct a closure for each cluster, in such a way only a small number of cluster candidates need to be considered when assigning a data point to its nearest cluster. Using complexity analysis, image data clustering, and applications to image retrieval, we show that our approach out-performs state-of-the-art approximate $k$-means algorithms in terms of clustering quality and efficiency.
Scalable $k$-NN graph construction
Jul 30, 2013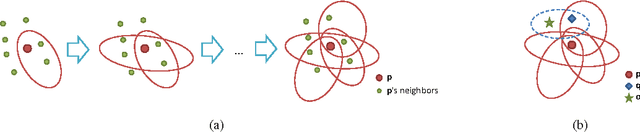

The $k$-NN graph has played a central role in increasingly popular data-driven techniques for various learning and vision tasks; yet, finding an efficient and effective way to construct $k$-NN graphs remains a challenge, especially for large-scale high-dimensional data. In this paper, we propose a new approach to construct approximate $k$-NN graphs with emphasis in: efficiency and accuracy. We hierarchically and randomly divide the data points into subsets and build an exact neighborhood graph over each subset, achieving a base approximate neighborhood graph; we then repeat this process for several times to generate multiple neighborhood graphs, which are combined to yield a more accurate approximate neighborhood graph. Furthermore, we propose a neighborhood propagation scheme to further enhance the accuracy. We show both theoretical and empirical accuracy and efficiency of our approach to $k$-NN graph construction and demonstrate significant speed-up in dealing with large scale visual data.
Hybrid Affinity Propagation
Jul 30, 2013
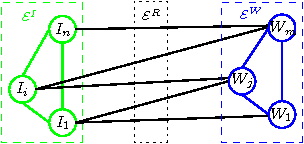

In this paper, we address a problem of managing tagged images with hybrid summarization. We formulate this problem as finding a few image exemplars to represent the image set semantically and visually, and solve it in a hybrid way by exploiting both visual and textual information associated with images. We propose a novel approach, called homogeneous and heterogeneous message propagation ($\text{H}^\text{2}\text{MP}$). Similar to the affinity propagation (AP) approach, $\text{H}^\text{2}\text{MP}$ reduce the conventional \emph{vector} message propagation to \emph{scalar} message propagation to make the algorithm more efficient. Beyond AP that can only handle homogeneous data, $\text{H}^\text{2}\text{MP}$ generalizes it to exploit extra heterogeneous relations and the generalization is non-trivial as the reduction to scalar messages from vector messages is more challenging. The main advantages of our approach lie in 1) that $\text{H}^\text{2}\text{MP}$ exploits visual similarity and in addition the useful information from the associated tags, including the associations relation between images and tags and the relations within tags, and 2) that the summary is both visually and semantically satisfactory. In addition, our approach can also present a textual summary to a tagged image collection, which can be used to automatically generate a textual description. The experimental results demonstrate the effectiveness and efficiency of the roposed approach.