 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising Implicit Feedback for Cold-start Recommendation
Jun 17, 2026Implicit feedback is widely used in recommender systems due to its accessibility and generality, yet it usually presents noisy samples (e.g., clickbait, position bias). Meanwhile, recommenders inevitably face the item cold-start problem due to the continuous influx of new items. We identify that cold items are more prone to noisy samples due to the aforementioned factors, and researchers often overlook the significance of denoising implicit feedback for cold items. Previous denoising studies usually identify noisy samples based on heuristic patterns, such as higher loss values, and mitigate noise through sample selection or re-weighting. However, these methods have limited adaptability and are ineffective in cold-start scenarios. To achieve denoising implicit feedback for cold-start recommendation, we propose a model-agnostic denoising method called DIF. First, user preferences for content remain stable, which allows us to infer pseudo-labels indicating whether a user is interested in a cold item through content-similar warm items. Furthermore, to improve pseudo-label accuracy, we model the confidence of pseudo-labels based on the content similarity between the cold item and warm items, and then aggregate multiple pseudo-labels for each sample. Finally, we explicitly estimate the uncertainty of the noisy sample label by considering its relative entropy and the cold-start status of the item, which adaptively guides the role of pseudo-labels to correct the noisy labels at the sample level. DIF's superiority is supported by both theoretical justification and extensive experiments on real-world datasets. The method has been deployed on a billion-user scale short video application Kuaishou and has significantly improved various commercial metrics within cold-start scenarios.
Towards Comprehensible Recommendation with Large Language Model Fine-tuning
Aug 11, 2025Recommender systems have become increasingly ubiquitous in daily life. While traditional recommendation approaches primarily rely on ID-based representations or item-side content features, they often fall short in capturing the underlying semantics aligned with user preferences (e.g., recommendation reasons for items), leading to a semantic-collaborative gap. Recently emerged LLM-based feature extraction approaches also face a key challenge: how to ensure that LLMs possess recommendation-aligned reasoning capabilities and can generate accurate, personalized reasons to mitigate the semantic-collaborative gap. To address these issues, we propose a novel Content Understanding from a Collaborative Perspective framework (CURec), which generates collaborative-aligned content features for more comprehensive recommendations. \method first aligns the LLM with recommendation objectives through pretraining, equipping it with instruction-following and chain-of-thought reasoning capabilities. Next, we design a reward model inspired by traditional recommendation architectures to evaluate the quality of the recommendation reasons generated by the LLM. Finally, using the reward signals, CURec fine-tunes the LLM through RL and corrects the generated reasons to ensure their accuracy. The corrected reasons are then integrated into a downstream recommender model to enhance comprehensibility and recommendation performance. Extensive experiments on public benchmarks demonstrate the superiority of CURec over existing methods.
LearnAlign: Reasoning Data Selection for Reinforcement Learning in Large Language Models Based on Improved Gradient Alignment
Jun 13, 2025Reinforcement learning (RL) has become a key technique for enhancing LLMs' reasoning abilities, yet its data inefficiency remains a major bottleneck. To address this critical yet challenging issue, we present a novel gradient-alignment-based method, named LearnAlign, which intelligently selects the learnable and representative training reasoning data for RL post-training. To overcome the well-known issue of response-length bias in gradient norms, we introduce the data learnability based on the success rate, which can indicate the learning potential of each data point. Experiments across three mathematical reasoning benchmarks demonstrate that our method significantly reduces training data requirements while achieving minor performance degradation or even improving performance compared to full-data training. For example, it reduces data requirements by up to 1,000 data points with better performance (77.53%) than that on the full dataset on GSM8K benchmark (77.04%). Furthermore, we show its effectiveness in the staged RL setting. This work provides valuable insights into data-efficient RL post-training and establishes a foundation for future research in optimizing reasoning data selection.To facilitate future work, we will release code.
Prompt Tuning for Item Cold-start Recommendation
Dec 24, 2024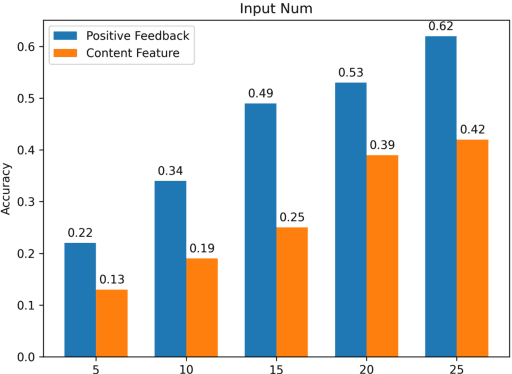
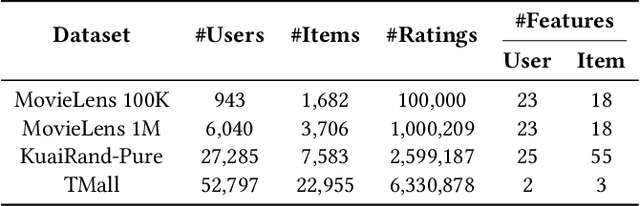
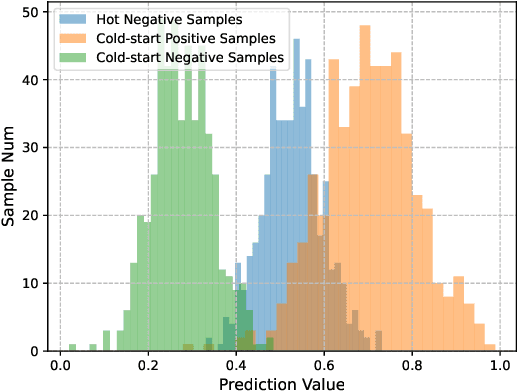
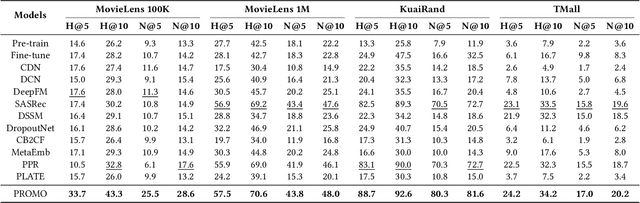
The item cold-start problem is crucial for online recommender systems, as the success of the cold-start phase determines whether items can transition into popular ones. Prompt learning, a powerful technique used in natural language processing (NLP) to address zero- or few-shot problems, has been adapted for recommender systems to tackle similar challenges. However, existing methods typically rely on content-based properties or text descriptions for prompting, which we argue may be suboptimal for cold-start recommendations due to 1) semantic gaps with recommender tasks, 2) model bias caused by warm-up items contribute most of the positive feedback to the model, which is the core of the cold-start problem that hinders the recommender quality on cold-start items. We propose to leverage high-value positive feedback, termed pinnacle feedback as prompt information, to simultaneously resolve the above two problems. We experimentally prove that compared to the content description proposed in existing works, the positive feedback is more suitable to serve as prompt information by bridging the semantic gaps. Besides, we propose item-wise personalized prompt networks to encode pinnaclce feedback to relieve the model bias by the positive feedback dominance problem. Extensive experiments on four real-world datasets demonstrate the superiority of our model over state-of-the-art methods. Moreover, PROMO has been successfully deployed on a popular short-video sharing platform, a billion-user scale commercial short-video application, achieving remarkable performance gains across various commercial metrics within cold-start scenarios
Online Item Cold-Start Recommendation with Popularity-Aware Meta-Learning
Nov 18, 2024



With the rise of e-commerce and short videos, online recommender systems that can capture users' interests and update new items in real-time play an increasingly important role. In both online and offline recommendation, the cold-start problem due to interaction sparsity has been affecting the recommendation effect of cold-start items, which is also known as the long-tail problem of item distribution. Many cold-start scheme based on fine-tuning or knowledge transferring shows excellent performance on offline recommendation. Yet, these schemes are infeasible for online recommendation on streaming data pipelines due to different training method, computational overhead and time constraints. Inspired by the above questions, we propose a model-agnostic recommendation algorithm called Popularity-Aware Meta-learning (PAM), to address the item cold-start problem under streaming data settings. PAM divides the incoming data into different meta-learning tasks by predefined item popularity thresholds. The model can distinguish and reweight behavior-related features and content-related features in each task based on their different roles in different popularity levels, thus adapting to recommendations for cold-start samples. These task-fixing design significantly reduces additional computation and storage costs compared to offline methods. Furthermore, PAM also introduced data augmentation and an additional self-supervised loss specifically designed for low-popularity tasks, leveraging insights from high-popularity samples. This approach effectively mitigates the issue of inadequate supervision due to the scarcity of cold-start samples. Experimental results across multiple public datasets demonstrate the superiority of our approach over other baseline methods in addressing cold-start challenges in online streaming data scenarios.
A Unified Framework for Cross-Domain Recommendation
Sep 06, 2024



In addressing the persistent challenges of data-sparsity and cold-start issues in domain-expert recommender systems, Cross-Domain Recommendation (CDR) emerges as a promising methodology. CDR aims at enhancing prediction performance in the target domain by leveraging interaction knowledge from related source domains, particularly through users or items that span across multiple domains (e.g., Short-Video and Living-Room). For academic research purposes, there are a number of distinct aspects to guide CDR method designing, including the auxiliary domain number, domain-overlapped element, user-item interaction types, and downstream tasks. With so many different CDR combination scenario settings, the proposed scenario-expert approaches are tailored to address a specific vertical CDR scenario, and often lack the capacity to adapt to multiple horizontal scenarios. In an effect to coherently adapt to various scenarios, and drawing inspiration from the concept of domain-invariant transfer learning, we extend the former SOTA model UniCDR in five different aspects, named as UniCDR+. Our work was successfully deployed on the Kuaishou Living-Room RecSys.
A Cross-City Federated Transfer Learning Framework: A Case Study on Urban Region Profiling
May 31, 2022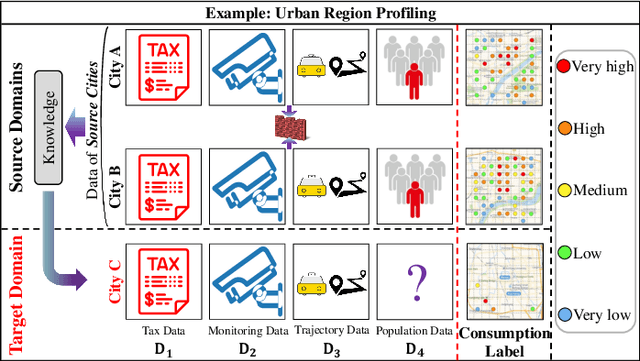
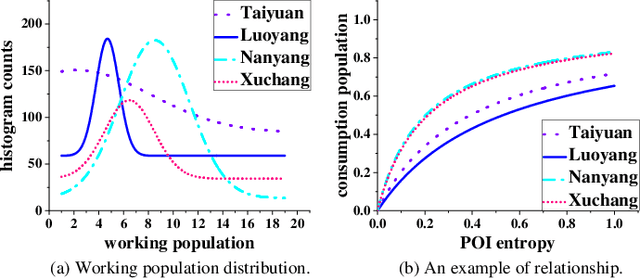
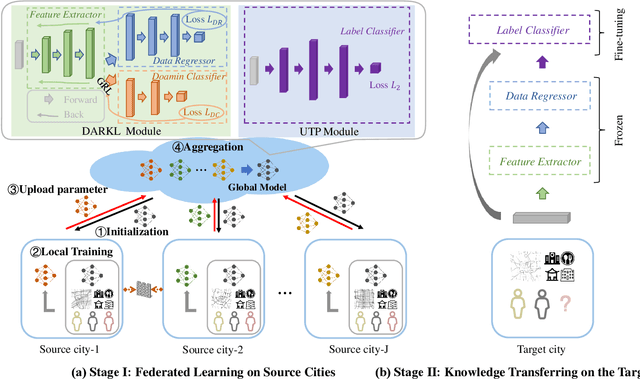
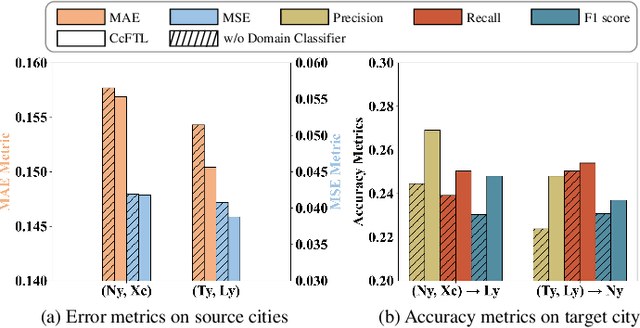
Data insufficiency problem (i.e., data missing and label scarcity issues) caused by inadequate services and infrastructures or unbalanced development levels of cities has seriously affected the urban computing tasks in real scenarios. Prior transfer learning methods inspire an elegant solution to the data insufficiency, but are only concerned with one kind of insufficiency issue and fail to fully explore these two issues existing in the real world. In addition, cross-city transfer in existing methods overlooks the inter-city data privacy which is a public concern in practical application. To address the above challenging problems, we propose a novel Cross-city Federated Transfer Learning framework (CcFTL) to cope with the data insufficiency and privacy problems. Concretely, CcFTL transfers the relational knowledge from multiple rich-data source cities to the target city. Besides, the model parameters specific to the target task are firstly trained on the source data and then fine-tuned to the target city by parameter transfer. With our adaptation of federated training and homomorphic encryption settings, CcFTL can effectively deal with the data privacy problem among cities. We take the urban region profiling as an application of smart cities and evaluate the proposed method with a real-world study. The experiments demonstrate the notable superiority of our framework over several competitive state-of-the-art models.
Exploring Periodicity and Interactivity in Multi-Interest Framework for Sequential Recommendation
Jun 07, 2021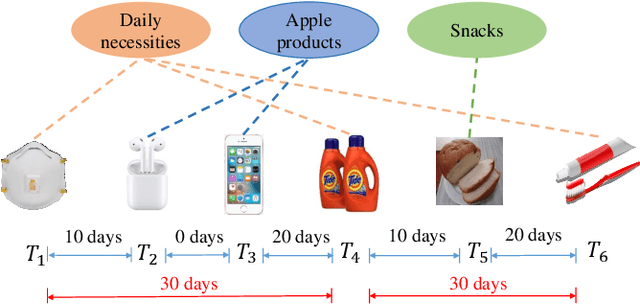

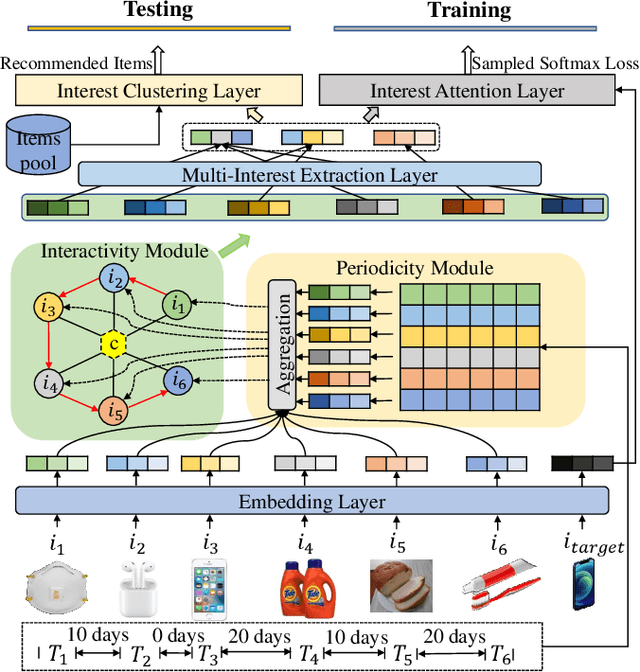

Sequential recommendation systems alleviate the problem of information overload, and have attracted increasing attention in the literature. Most prior works usually obtain an overall representation based on the user's behavior sequence, which can not sufficiently reflect the multiple interests of the user. To this end, we propose a novel method called PIMI to mitigate this issue. PIMI can model the user's multi-interest representation effectively by considering both the periodicity and interactivity in the item sequence. Specifically, we design a periodicity-aware module to utilize the time interval information between user's behaviors. Meanwhile, an ingenious graph is proposed to enhance the interactivity between items in user's behavior sequence, which can capture both global and local item features. Finally, a multi-interest extraction module is applied to describe user's multiple interests based on the obtained item representation. Extensive experiments on two real-world datasets Amazon and Taobao show that PIMI outperforms state-of-the-art methods consistently.