 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Causal Structure Learning via Modular Subgraph Integration
Jan 28, 2026Learning causal structures from observational data remains a fundamental yet computationally intensive task, particularly in high-dimensional settings where existing methods face challenges such as the super-exponential growth of the search space and increasing computational demands. To address this, we introduce VISTA (Voting-based Integration of Subgraph Topologies for Acyclicity), a modular framework that decomposes the global causal structure learning problem into local subgraphs based on Markov Blankets. The global integration is achieved through a weighted voting mechanism that penalizes low-support edges via exponential decay, filters unreliable ones with an adaptive threshold, and ensures acyclicity using a Feedback Arc Set (FAS) algorithm. The framework is model-agnostic, imposing no assumptions on the inductive biases of base learners, is compatible with arbitrary data settings without requiring specific structural forms, and fully supports parallelization. We also theoretically establish finite-sample error bounds for VISTA, and prove its asymptotic consistency under mild conditions. Extensive experiments on both synthetic and real datasets consistently demonstrate the effectiveness of VISTA, yielding notable improvements in both accuracy and efficiency over a wide range of base learners.
Improving VQA Reliability: A Dual-Assessment Approach with Self-Reflection and Cross-Model Verification
Dec 16, 2025Vision-language models (VLMs) have demonstrated significant potential in Visual Question Answering (VQA). However, the susceptibility of VLMs to hallucinations can lead to overconfident yet incorrect answers, severely undermining answer reliability. To address this, we propose Dual-Assessment for VLM Reliability (DAVR), a novel framework that integrates Self-Reflection and Cross-Model Verification for comprehensive uncertainty estimation. The DAVR framework features a dual-pathway architecture: one pathway leverages dual selector modules to assess response reliability by fusing VLM latent features with QA embeddings, while the other deploys external reference models for factual cross-checking to mitigate hallucinations. Evaluated in the Reliable VQA Challenge at ICCV-CLVL 2025, DAVR achieves a leading $Φ_{100}$ score of 39.64 and a 100-AUC of 97.22, securing first place and demonstrating its effectiveness in enhancing the trustworthiness of VLM responses.
Diving into Mitigating Hallucinations from a Vision Perspective for Large Vision-Language Models
Sep 17, 2025
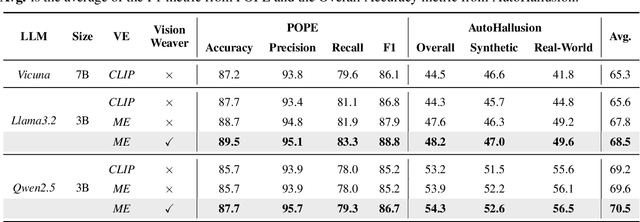
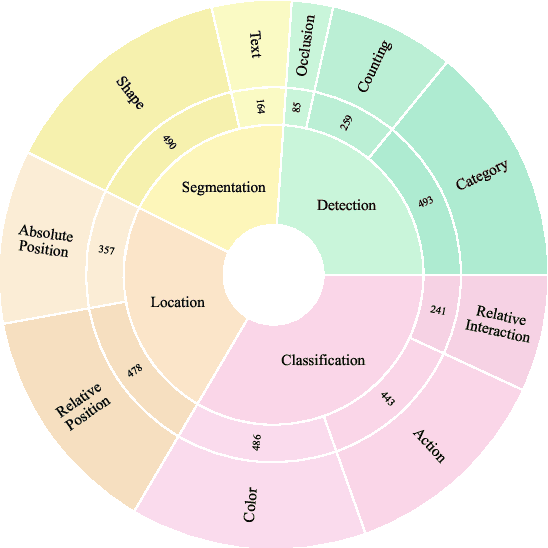
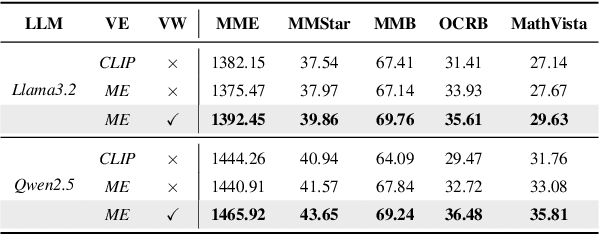
Object hallucination in Large Vision-Language Models (LVLMs) significantly impedes their real-world applicability. As the primary component for accurately interpreting visual information, the choice of visual encoder is pivotal. We hypothesize that the diverse training paradigms employed by different visual encoders instill them with distinct inductive biases, which leads to their diverse hallucination performances. Existing benchmarks typically focus on coarse-grained hallucination detection and fail to capture the diverse hallucinations elaborated in our hypothesis. To systematically analyze these effects, we introduce VHBench-10, a comprehensive benchmark with approximately 10,000 samples for evaluating LVLMs across ten fine-grained hallucination categories. Our evaluations confirm encoders exhibit unique hallucination characteristics. Building on these insights and the suboptimality of simple feature fusion, we propose VisionWeaver, a novel Context-Aware Routing Network. It employs global visual features to generate routing signals, dynamically aggregating visual features from multiple specialized experts. Comprehensive experiments confirm the effectiveness of VisionWeaver in significantly reducing hallucinations and improving overall model performance.
TextFlux: An OCR-Free DiT Model for High-Fidelity Multilingual Scene Text Synthesis
May 23, 2025


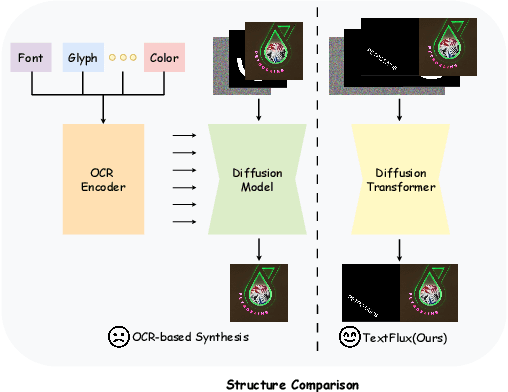
Diffusion-based scene text synthesis has progressed rapidly, yet existing methods commonly rely on additional visual conditioning modules and require large-scale annotated data to support multilingual generation. In this work, we revisit the necessity of complex auxiliary modules and further explore an approach that simultaneously ensures glyph accuracy and achieves high-fidelity scene integration, by leveraging diffusion models' inherent capabilities for contextual reasoning. To this end, we introduce TextFlux, a DiT-based framework that enables multilingual scene text synthesis. The advantages of TextFlux can be summarized as follows: (1) OCR-free model architecture. TextFlux eliminates the need for OCR encoders (additional visual conditioning modules) that are specifically used to extract visual text-related features. (2) Strong multilingual scalability. TextFlux is effective in low-resource multilingual settings, and achieves strong performance in newly added languages with fewer than 1,000 samples. (3) Streamlined training setup. TextFlux is trained with only 1% of the training data required by competing methods. (4) Controllable multi-line text generation. TextFlux offers flexible multi-line synthesis with precise line-level control, outperforming methods restricted to single-line or rigid layouts. Extensive experiments and visualizations demonstrate that TextFlux outperforms previous methods in both qualitative and quantitative evaluations.
USM: Unbiased Survey Modeling for Limiting Negative User Experiences in Recommendation Systems
Dec 14, 2024Negative feedback signals are crucial to guardrail content recommendations and improve user experience. When these signals are effectively integrated into recommendation systems, they play a vital role in preventing the promotion of harmful or undesirable content, thereby contributing to a healthier online environment. However, the challenges associated with negative signals are noteworthy. Due to the limited visibility of options for users to express negative feedback, these signals are often sparse compared to positive signals. This imbalance can lead to a skewed understanding of user preferences, resulting in recommendations that prioritize short-term engagement over long-term satisfaction. Moreover, an over-reliance on positive signals can create a filter bubble, where users are continuously exposed to content that aligns with their immediate preferences but may not be beneficial in the long run. This scenario can ultimately lead to user attrition as audiences become disillusioned with the quality of the content provided. Additionally, existing user signals frequently fail to meet specific customized requirements, such as understanding the underlying reasons for a user's likes or dislikes regarding a video. This lack of granularity hinders our ability to tailor content recommendations effectively, as we cannot identify the particular attributes of content that resonate with individual users.
Online Item Cold-Start Recommendation with Popularity-Aware Meta-Learning
Nov 18, 2024



With the rise of e-commerce and short videos, online recommender systems that can capture users' interests and update new items in real-time play an increasingly important role. In both online and offline recommendation, the cold-start problem due to interaction sparsity has been affecting the recommendation effect of cold-start items, which is also known as the long-tail problem of item distribution. Many cold-start scheme based on fine-tuning or knowledge transferring shows excellent performance on offline recommendation. Yet, these schemes are infeasible for online recommendation on streaming data pipelines due to different training method, computational overhead and time constraints. Inspired by the above questions, we propose a model-agnostic recommendation algorithm called Popularity-Aware Meta-learning (PAM), to address the item cold-start problem under streaming data settings. PAM divides the incoming data into different meta-learning tasks by predefined item popularity thresholds. The model can distinguish and reweight behavior-related features and content-related features in each task based on their different roles in different popularity levels, thus adapting to recommendations for cold-start samples. These task-fixing design significantly reduces additional computation and storage costs compared to offline methods. Furthermore, PAM also introduced data augmentation and an additional self-supervised loss specifically designed for low-popularity tasks, leveraging insights from high-popularity samples. This approach effectively mitigates the issue of inadequate supervision due to the scarcity of cold-start samples. Experimental results across multiple public datasets demonstrate the superiority of our approach over other baseline methods in addressing cold-start challenges in online streaming data scenarios.