 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Comprehensible Recommendation with Large Language Model Fine-tuning
Aug 11, 2025Recommender systems have become increasingly ubiquitous in daily life. While traditional recommendation approaches primarily rely on ID-based representations or item-side content features, they often fall short in capturing the underlying semantics aligned with user preferences (e.g., recommendation reasons for items), leading to a semantic-collaborative gap. Recently emerged LLM-based feature extraction approaches also face a key challenge: how to ensure that LLMs possess recommendation-aligned reasoning capabilities and can generate accurate, personalized reasons to mitigate the semantic-collaborative gap. To address these issues, we propose a novel Content Understanding from a Collaborative Perspective framework (CURec), which generates collaborative-aligned content features for more comprehensive recommendations. \method first aligns the LLM with recommendation objectives through pretraining, equipping it with instruction-following and chain-of-thought reasoning capabilities. Next, we design a reward model inspired by traditional recommendation architectures to evaluate the quality of the recommendation reasons generated by the LLM. Finally, using the reward signals, CURec fine-tunes the LLM through RL and corrects the generated reasons to ensure their accuracy. The corrected reasons are then integrated into a downstream recommender model to enhance comprehensibility and recommendation performance. Extensive experiments on public benchmarks demonstrate the superiority of CURec over existing methods.
Prompt Tuning for Item Cold-start Recommendation
Dec 24, 2024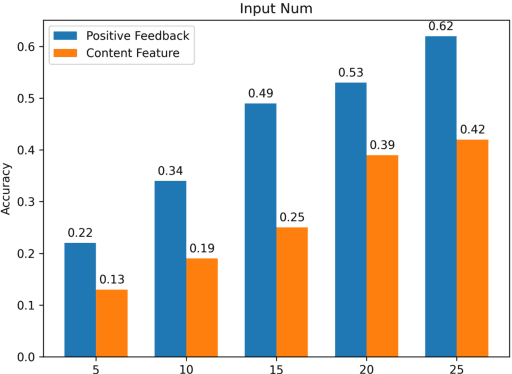
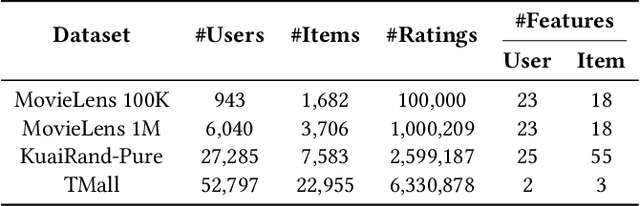
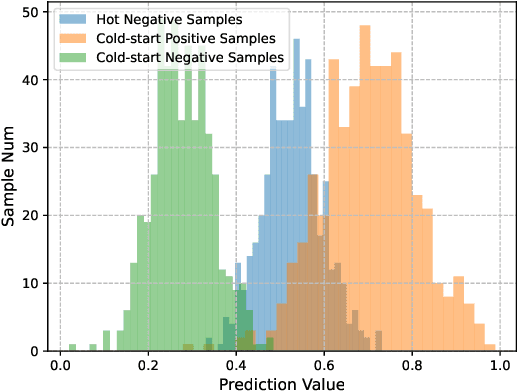
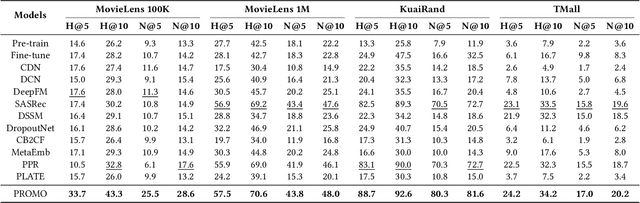
The item cold-start problem is crucial for online recommender systems, as the success of the cold-start phase determines whether items can transition into popular ones. Prompt learning, a powerful technique used in natural language processing (NLP) to address zero- or few-shot problems, has been adapted for recommender systems to tackle similar challenges. However, existing methods typically rely on content-based properties or text descriptions for prompting, which we argue may be suboptimal for cold-start recommendations due to 1) semantic gaps with recommender tasks, 2) model bias caused by warm-up items contribute most of the positive feedback to the model, which is the core of the cold-start problem that hinders the recommender quality on cold-start items. We propose to leverage high-value positive feedback, termed pinnacle feedback as prompt information, to simultaneously resolve the above two problems. We experimentally prove that compared to the content description proposed in existing works, the positive feedback is more suitable to serve as prompt information by bridging the semantic gaps. Besides, we propose item-wise personalized prompt networks to encode pinnaclce feedback to relieve the model bias by the positive feedback dominance problem. Extensive experiments on four real-world datasets demonstrate the superiority of our model over state-of-the-art methods. Moreover, PROMO has been successfully deployed on a popular short-video sharing platform, a billion-user scale commercial short-video application, achieving remarkable performance gains across various commercial metrics within cold-start scenarios
Online Item Cold-Start Recommendation with Popularity-Aware Meta-Learning
Nov 18, 2024



With the rise of e-commerce and short videos, online recommender systems that can capture users' interests and update new items in real-time play an increasingly important role. In both online and offline recommendation, the cold-start problem due to interaction sparsity has been affecting the recommendation effect of cold-start items, which is also known as the long-tail problem of item distribution. Many cold-start scheme based on fine-tuning or knowledge transferring shows excellent performance on offline recommendation. Yet, these schemes are infeasible for online recommendation on streaming data pipelines due to different training method, computational overhead and time constraints. Inspired by the above questions, we propose a model-agnostic recommendation algorithm called Popularity-Aware Meta-learning (PAM), to address the item cold-start problem under streaming data settings. PAM divides the incoming data into different meta-learning tasks by predefined item popularity thresholds. The model can distinguish and reweight behavior-related features and content-related features in each task based on their different roles in different popularity levels, thus adapting to recommendations for cold-start samples. These task-fixing design significantly reduces additional computation and storage costs compared to offline methods. Furthermore, PAM also introduced data augmentation and an additional self-supervised loss specifically designed for low-popularity tasks, leveraging insights from high-popularity samples. This approach effectively mitigates the issue of inadequate supervision due to the scarcity of cold-start samples. Experimental results across multiple public datasets demonstrate the superiority of our approach over other baseline methods in addressing cold-start challenges in online streaming data scenarios.