 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling and Eliminating the Shortcut Learning for Locate-Then-Edit Knowledge Editing via Both Subject and Relation Awareness
Jun 04, 2025Knowledge editing aims to alternate the target knowledge predicted by large language models while ensuring the least side effects on unrelated knowledge. An effective way to achieve knowledge editing is to identify pivotal parameters for predicting factual associations and modify them with an optimization process to update the predictions. However, these locate-then-edit methods are uncontrollable since they tend to modify most unrelated relations connected to the subject of target editing. We unveil that this failure of controllable editing is due to a shortcut learning issue during the optimization process. Specifically, we discover two crucial features that are the subject feature and the relation feature for models to learn during optimization, but the current optimization process tends to over-learning the subject feature while neglecting the relation feature. To eliminate this shortcut learning of the subject feature, we propose a novel two-stage optimization process that balances the learning of the subject feature and the relation feature. Experimental results demonstrate that our approach successfully prevents knowledge editing from shortcut learning and achieves the optimal overall performance, contributing to controllable knowledge editing.
Simulation-Aided Policy Tuning for Black-Box Robot Learning
Nov 21, 2024



How can robots learn and adapt to new tasks and situations with little data? Systematic exploration and simulation are crucial tools for efficient robot learning. We present a novel black-box policy search algorithm focused on data-efficient policy improvements. The algorithm learns directly on the robot and treats simulation as an additional information source to speed up the learning process. At the core of the algorithm, a probabilistic model learns the dependence of the policy parameters and the robot learning objective not only by performing experiments on the robot, but also by leveraging data from a simulator. This substantially reduces interaction time with the robot. Using this model, we can guarantee improvements with high probability for each policy update, thereby facilitating fast, goal-oriented learning. We evaluate our algorithm on simulated fine-tuning tasks and demonstrate the data-efficiency of the proposed dual-information source optimization algorithm. In a real robot learning experiment, we show fast and successful task learning on a robot manipulator with the aid of an imperfect simulator.
Relation Also Knows: Rethinking the Recall and Editing of Factual Associations in Auto-Regressive Transformer Language Models
Aug 27, 2024



The storage and recall of factual associations in auto-regressive transformer language models (LMs) have drawn a great deal of attention, inspiring knowledge editing by directly modifying the located model weights. Most editing works achieve knowledge editing under the guidance of existing interpretations of knowledge recall that mainly focus on subject knowledge. However, these interpretations are seriously flawed, neglecting relation information and leading to the over-generalizing problem for editing. In this work, we discover a novel relation-focused perspective to interpret the knowledge recall of transformer LMs during inference and apply it on knowledge editing to avoid over-generalizing. Experimental results on the dataset supplemented with a new R-Specificity criterion demonstrate that our editing approach significantly alleviates over-generalizing while remaining competitive on other criteria, breaking the domination of subject-focused editing for future research.
GGViT:Multistream Vision Transformer Network in Face2Face Facial Reenactment Detection
Oct 12, 2022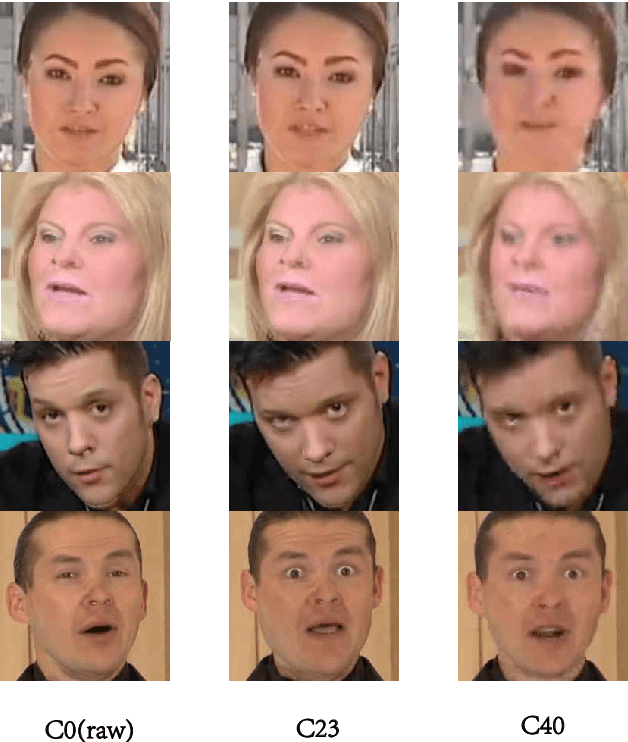

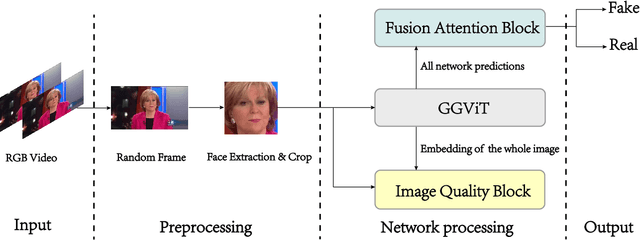
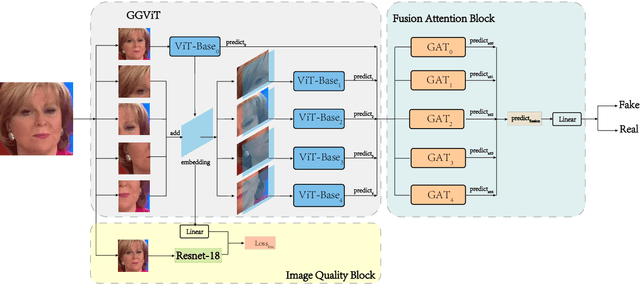
Detecting manipulated facial images and videos on social networks has been an urgent problem to be solved. The compression of videos on social media has destroyed some pixel details that could be used to detect forgeries. Hence, it is crucial to detect manipulated faces in videos of different quality. We propose a new multi-stream network architecture named GGViT, which utilizes global information to improve the generalization of the model. The embedding of the whole face extracted by ViT will guide each stream network. Through a large number of experiments, we have proved that our proposed model achieves state-of-the-art classification accuracy on FF++ dataset, and has been greatly improved on scenarios of different compression rates. The accuracy of Raw/C23, Raw/C40 and C23/C40 was increased by 24.34%, 15.08% and 10.14% respectively.
A Cross-City Federated Transfer Learning Framework: A Case Study on Urban Region Profiling
May 31, 2022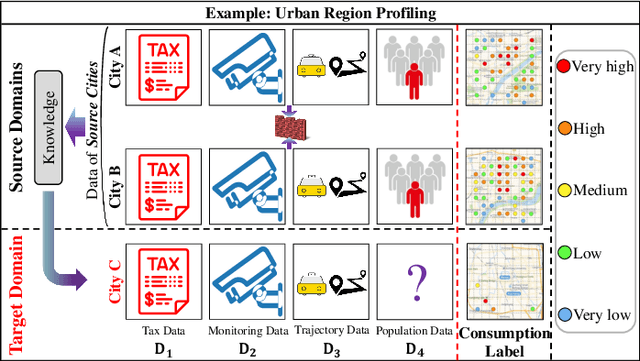
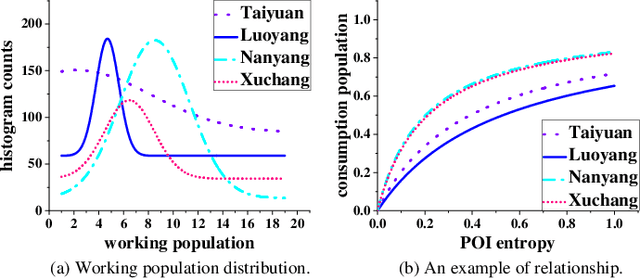
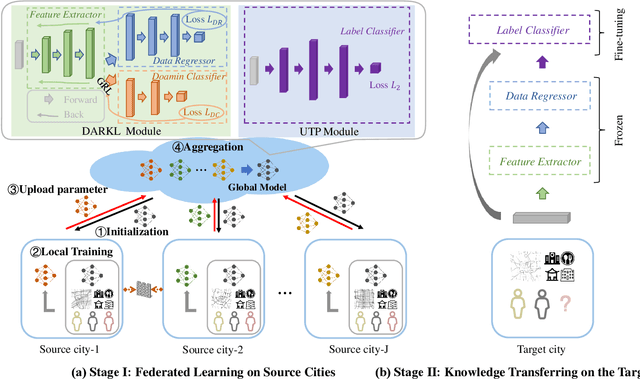
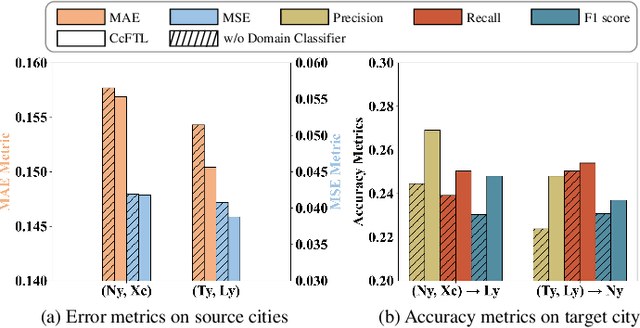
Data insufficiency problem (i.e., data missing and label scarcity issues) caused by inadequate services and infrastructures or unbalanced development levels of cities has seriously affected the urban computing tasks in real scenarios. Prior transfer learning methods inspire an elegant solution to the data insufficiency, but are only concerned with one kind of insufficiency issue and fail to fully explore these two issues existing in the real world. In addition, cross-city transfer in existing methods overlooks the inter-city data privacy which is a public concern in practical application. To address the above challenging problems, we propose a novel Cross-city Federated Transfer Learning framework (CcFTL) to cope with the data insufficiency and privacy problems. Concretely, CcFTL transfers the relational knowledge from multiple rich-data source cities to the target city. Besides, the model parameters specific to the target task are firstly trained on the source data and then fine-tuned to the target city by parameter transfer. With our adaptation of federated training and homomorphic encryption settings, CcFTL can effectively deal with the data privacy problem among cities. We take the urban region profiling as an application of smart cities and evaluate the proposed method with a real-world study. The experiments demonstrate the notable superiority of our framework over several competitive state-of-the-art models.
Exploring Periodicity and Interactivity in Multi-Interest Framework for Sequential Recommendation
Jun 07, 2021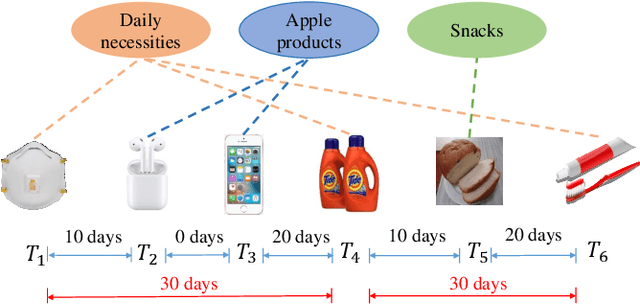

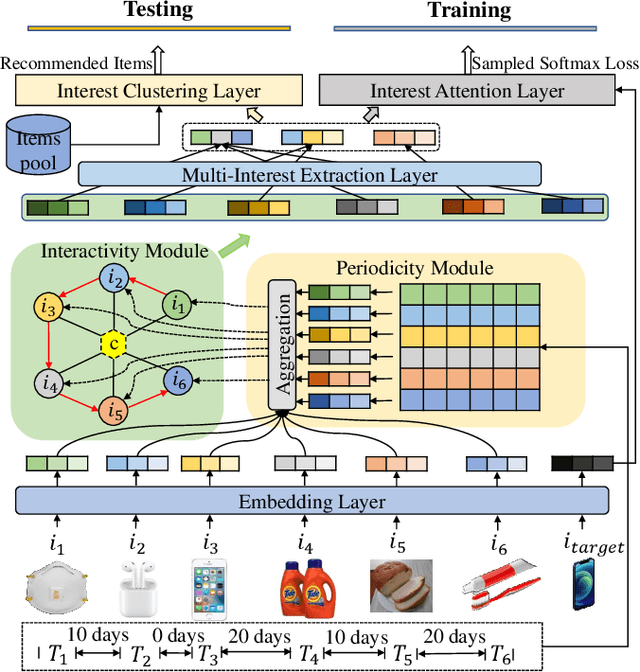

Sequential recommendation systems alleviate the problem of information overload, and have attracted increasing attention in the literature. Most prior works usually obtain an overall representation based on the user's behavior sequence, which can not sufficiently reflect the multiple interests of the user. To this end, we propose a novel method called PIMI to mitigate this issue. PIMI can model the user's multi-interest representation effectively by considering both the periodicity and interactivity in the item sequence. Specifically, we design a periodicity-aware module to utilize the time interval information between user's behaviors. Meanwhile, an ingenious graph is proposed to enhance the interactivity between items in user's behavior sequence, which can capture both global and local item features. Finally, a multi-interest extraction module is applied to describe user's multiple interests based on the obtained item representation. Extensive experiments on two real-world datasets Amazon and Taobao show that PIMI outperforms state-of-the-art methods consistently.