 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGGViT:Multistream Vision Transformer Network in Face2Face Facial Reenactment Detection
Paper and Code
Oct 12, 2022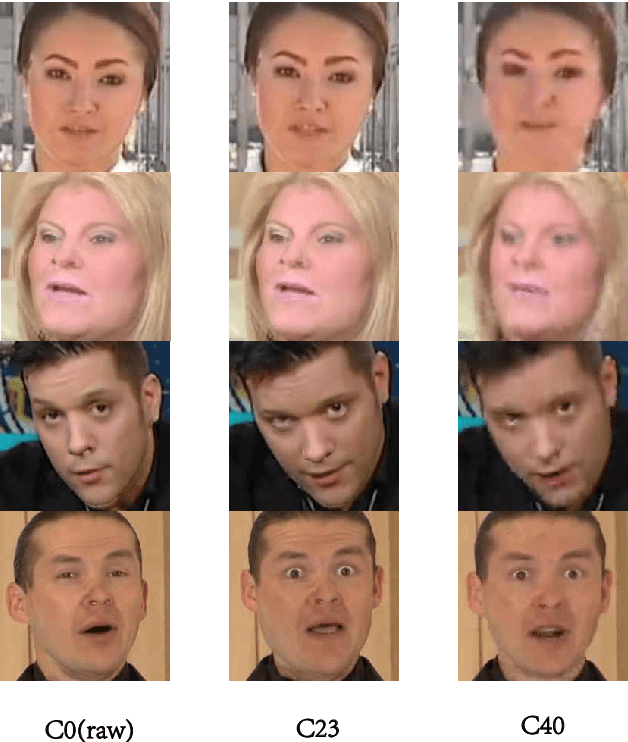

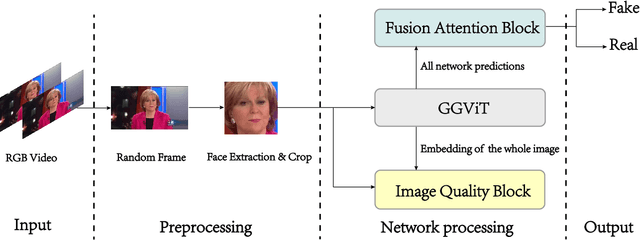
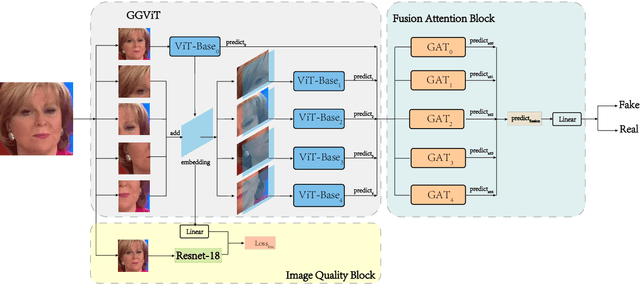
Detecting manipulated facial images and videos on social networks has been an urgent problem to be solved. The compression of videos on social media has destroyed some pixel details that could be used to detect forgeries. Hence, it is crucial to detect manipulated faces in videos of different quality. We propose a new multi-stream network architecture named GGViT, which utilizes global information to improve the generalization of the model. The embedding of the whole face extracted by ViT will guide each stream network. Through a large number of experiments, we have proved that our proposed model achieves state-of-the-art classification accuracy on FF++ dataset, and has been greatly improved on scenarios of different compression rates. The accuracy of Raw/C23, Raw/C40 and C23/C40 was increased by 24.34%, 15.08% and 10.14% respectively.