 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Human Speech to Ocean Signals: Transferring Speech Large Models for Underwater Acoustic Target Recognition
Jan 26, 2026Underwater acoustic target recognition (UATR) plays a vital role in marine applications but remains challenging due to limited labeled data and the complexity of ocean environments. This paper explores a central question: can speech large models (SLMs), trained on massive human speech corpora, be effectively transferred to underwater acoustics? To investigate this, we propose UATR-SLM, a simple framework that reuses the speech feature pipeline, adapts the SLM as an acoustic encoder, and adds a lightweight classifier.Experiments on the DeepShip and ShipsEar benchmarks show that UATR-SLM achieves over 99% in-domain accuracy, maintains strong robustness across variable signal lengths, and reaches up to 96.67% accuracy in cross-domain evaluation. These results highlight the strong transferability of SLMs to UATR, establishing a promising paradigm for leveraging speech foundation models in underwater acoustics.
Collapsing Sequence-Level Data-Policy Coverage via Poisoning Attack in Offline Reinforcement Learning
Jun 12, 2025Offline reinforcement learning (RL) heavily relies on the coverage of pre-collected data over the target policy's distribution. Existing studies aim to improve data-policy coverage to mitigate distributional shifts, but overlook security risks from insufficient coverage, and the single-step analysis is not consistent with the multi-step decision-making nature of offline RL. To address this, we introduce the sequence-level concentrability coefficient to quantify coverage, and reveal its exponential amplification on the upper bound of estimation errors through theoretical analysis. Building on this, we propose the Collapsing Sequence-Level Data-Policy Coverage (CSDPC) poisoning attack. Considering the continuous nature of offline RL data, we convert state-action pairs into decision units, and extract representative decision patterns that capture multi-step behavior. We identify rare patterns likely to cause insufficient coverage, and poison them to reduce coverage and exacerbate distributional shifts. Experiments show that poisoning just 1% of the dataset can degrade agent performance by 90%. This finding provides new perspectives for analyzing and safeguarding the security of offline RL.
Act in Collusion: A Persistent Distributed Multi-Target Backdoor in Federated Learning
Nov 06, 2024Federated learning, a novel paradigm designed to protect data privacy, is vulnerable to backdoor attacks due to its distributed nature. Current research often designs attacks based on a single attacker with a single backdoor, overlooking more realistic and complex threats in federated learning. We propose a more practical threat model for federated learning: the distributed multi-target backdoor. In this model, multiple attackers control different clients, embedding various triggers and targeting different classes, collaboratively implanting backdoors into the global model via central aggregation. Empirical validation shows that existing methods struggle to maintain the effectiveness of multiple backdoors in the global model. Our key insight is that similar backdoor triggers cause parameter conflicts and injecting new backdoors disrupts gradient directions, significantly weakening some backdoors performance. To solve this, we propose a Distributed Multi-Target Backdoor Attack (DMBA), ensuring efficiency and persistence of backdoors from different malicious clients. To avoid parameter conflicts, we design a multi-channel dispersed frequency trigger strategy to maximize trigger differences. To mitigate gradient interference, we introduce backdoor replay in local training to neutralize conflicting gradients. Extensive validation shows that 30 rounds after the attack, Attack Success Rates of three different backdoors from various clients remain above 93%. The code will be made publicly available after the review period.
Revisiting Interpolation Augmentation for Speech-to-Text Generation
Jun 22, 2024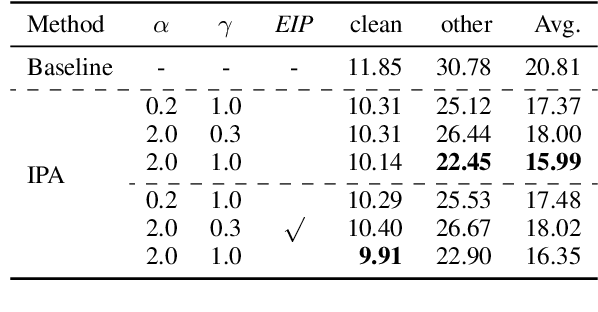


Speech-to-text (S2T) generation systems frequently face challenges in low-resource scenarios, primarily due to the lack of extensive labeled datasets. One emerging solution is constructing virtual training samples by interpolating inputs and labels, which has notably enhanced system generalization in other domains. Despite its potential, this technique's application in S2T tasks has remained under-explored. In this paper, we delve into the utility of interpolation augmentation, guided by several pivotal questions. Our findings reveal that employing an appropriate strategy in interpolation augmentation significantly enhances performance across diverse tasks, architectures, and data scales, offering a promising avenue for more robust S2T systems in resource-constrained settings.
Beyond Traditional Threats: A Persistent Backdoor Attack on Federated Learning
Apr 26, 2024Backdoors on federated learning will be diluted by subsequent benign updates. This is reflected in the significant reduction of attack success rate as iterations increase, ultimately failing. We use a new metric to quantify the degree of this weakened backdoor effect, called attack persistence. Given that research to improve this performance has not been widely noted,we propose a Full Combination Backdoor Attack (FCBA) method. It aggregates more combined trigger information for a more complete backdoor pattern in the global model. Trained backdoored global model is more resilient to benign updates, leading to a higher attack success rate on the test set. We test on three datasets and evaluate with two models across various settings. FCBA's persistence outperforms SOTA federated learning backdoor attacks. On GTSRB, postattack 120 rounds, our attack success rate rose over 50% from baseline. The core code of our method is available at https://github.com/PhD-TaoLiu/FCBA.
Bridging the Gaps of Both Modality and Language: Synchronous Bilingual CTC for Speech Translation and Speech Recognition
Sep 21, 2023



In this study, we present synchronous bilingual Connectionist Temporal Classification (CTC), an innovative framework that leverages dual CTC to bridge the gaps of both modality and language in the speech translation (ST) task. Utilizing transcript and translation as concurrent objectives for CTC, our model bridges the gap between audio and text as well as between source and target languages. Building upon the recent advances in CTC application, we develop an enhanced variant, BiL-CTC+, that establishes new state-of-the-art performances on the MuST-C ST benchmarks under resource-constrained scenarios. Intriguingly, our method also yields significant improvements in speech recognition performance, revealing the effect of cross-lingual learning on transcription and demonstrating its broad applicability. The source code is available at https://github.com/xuchennlp/S2T.