 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Interpolation Augmentation for Speech-to-Text Generation
Paper and Code
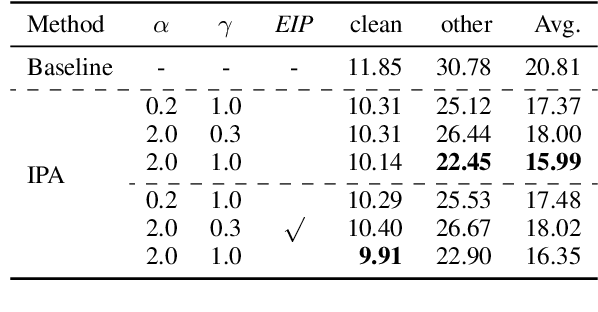


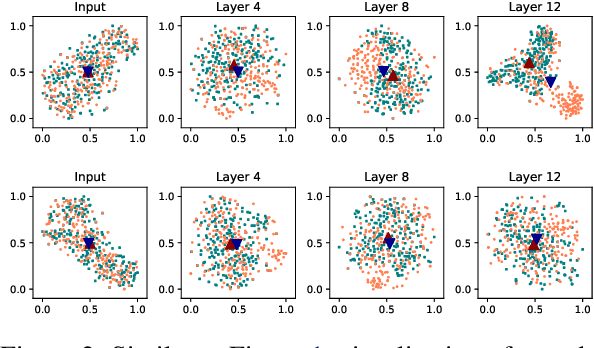
Speech-to-text (S2T) generation systems frequently face challenges in low-resource scenarios, primarily due to the lack of extensive labeled datasets. One emerging solution is constructing virtual training samples by interpolating inputs and labels, which has notably enhanced system generalization in other domains. Despite its potential, this technique's application in S2T tasks has remained under-explored. In this paper, we delve into the utility of interpolation augmentation, guided by several pivotal questions. Our findings reveal that employing an appropriate strategy in interpolation augmentation significantly enhances performance across diverse tasks, architectures, and data scales, offering a promising avenue for more robust S2T systems in resource-constrained settings.