 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSVLM-QA: A Benchmark Dataset for Remote Sensing Vision Language Model-based Question Answering
Aug 11, 2025Visual Question Answering (VQA) in remote sensing (RS) is pivotal for interpreting Earth observation data. However, existing RS VQA datasets are constrained by limitations in annotation richness, question diversity, and the assessment of specific reasoning capabilities. This paper introduces RSVLM-QA dataset, a new large-scale, content-rich VQA dataset for the RS domain. RSVLM-QA is constructed by integrating data from several prominent RS segmentation and detection datasets: WHU, LoveDA, INRIA, and iSAID. We employ an innovative dual-track annotation generation pipeline. Firstly, we leverage Large Language Models (LLMs), specifically GPT-4.1, with meticulously designed prompts to automatically generate a suite of detailed annotations including image captions, spatial relations, and semantic tags, alongside complex caption-based VQA pairs. Secondly, to address the challenging task of object counting in RS imagery, we have developed a specialized automated process that extracts object counts directly from the original segmentation data; GPT-4.1 then formulates natural language answers from these counts, which are paired with preset question templates to create counting QA pairs. RSVLM-QA comprises 13,820 images and 162,373 VQA pairs, featuring extensive annotations and diverse question types. We provide a detailed statistical analysis of the dataset and a comparison with existing RS VQA benchmarks, highlighting the superior depth and breadth of RSVLM-QA's annotations. Furthermore, we conduct benchmark experiments on Six mainstream Vision Language Models (VLMs), demonstrating that RSVLM-QA effectively evaluates and challenges the understanding and reasoning abilities of current VLMs in the RS domain. We believe RSVLM-QA will serve as a pivotal resource for the RS VQA and VLM research communities, poised to catalyze advancements in the field.
AeroLite: Tag-Guided Lightweight Generation of Aerial Image Captions
Apr 13, 2025Accurate and automated captioning of aerial imagery is crucial for applications like environmental monitoring, urban planning, and disaster management. However, this task remains challenging due to complex spatial semantics and domain variability. To address these issues, we introduce \textbf{AeroLite}, a lightweight, tag-guided captioning framework designed to equip small-scale language models (1--3B parameters) with robust and interpretable captioning capabilities specifically for remote sensing images. \textbf{AeroLite} leverages GPT-4o to generate a large-scale, semantically rich pseudo-caption dataset by integrating multiple remote sensing benchmarks, including DLRSD, iSAID, LoveDA, WHU, and RSSCN7. To explicitly capture key semantic elements such as orientation and land-use types, AeroLite employs natural language processing techniques to extract relevant semantic tags. These tags are then learned by a dedicated multi-label CLIP encoder, ensuring precise semantic predictions. To effectively fuse visual and semantic information, we propose a novel bridging multilayer perceptron (MLP) architecture, aligning semantic tags with visual embeddings while maintaining minimal computational overhead. AeroLite's flexible design also enables seamless integration with various pretrained large language models. We adopt a two-stage LoRA-based training approach: the initial stage leverages our pseudo-caption dataset to capture broad remote sensing semantics, followed by fine-tuning on smaller, curated datasets like UCM and Sydney Captions to refine domain-specific alignment. Experimental evaluations demonstrate that AeroLite surpasses significantly larger models (e.g., 13B parameters) in standard captioning metrics, including BLEU and METEOR, while maintaining substantially lower computational costs.
Bayesian Prompt Flow Learning for Zero-Shot Anomaly Detection
Mar 13, 2025Recently, vision-language models (e.g. CLIP) have demonstrated remarkable performance in zero-shot anomaly detection (ZSAD). By leveraging auxiliary data during training, these models can directly perform cross-category anomaly detection on target datasets, such as detecting defects on industrial product surfaces or identifying tumors in organ tissues. Existing approaches typically construct text prompts through either manual design or the optimization of learnable prompt vectors. However, these methods face several challenges: 1) handcrafted prompts require extensive expert knowledge and trial-and-error; 2) single-form learnable prompts struggle to capture complex anomaly semantics; and 3) an unconstrained prompt space limit generalization to unseen categories. To address these issues, we propose Bayesian Prompt Flow Learning (Bayes-PFL), which models the prompt space as a learnable probability distribution from a Bayesian perspective. Specifically, a prompt flow module is designed to learn both image-specific and image-agnostic distributions, which are jointly utilized to regularize the text prompt space and enhance the model's generalization on unseen categories. These learned distributions are then sampled to generate diverse text prompts, effectively covering the prompt space. Additionally, a residual cross-attention (RCA) module is introduced to better align dynamic text embeddings with fine-grained image features. Extensive experiments on 15 industrial and medical datasets demonstrate our method's superior performance.
Visual and Text Prompt Segmentation: A Novel Multi-Model Framework for Remote Sensing
Mar 10, 2025Pixel-level segmentation is essential in remote sensing, where foundational vision models like CLIP and Segment Anything Model(SAM) have demonstrated significant capabilities in zero-shot segmentation tasks. Despite their advances, challenges specific to remote sensing remain substantial. Firstly, The SAM without clear prompt constraints, often generates redundant masks, and making post-processing more complex. Secondly, the CLIP model, mainly designed for global feature alignment in foundational models, often overlooks local objects crucial to remote sensing. This oversight leads to inaccurate recognition or misplaced focus in multi-target remote sensing imagery. Thirdly, both models have not been pre-trained on multi-scale aerial views, increasing the likelihood of detection failures. To tackle these challenges, we introduce the innovative VTPSeg pipeline, utilizing the strengths of Grounding DINO, CLIP, and SAM for enhanced open-vocabulary image segmentation. The Grounding DINO+(GD+) module generates initial candidate bounding boxes, while the CLIP Filter++(CLIP++) module uses a combination of visual and textual prompts to refine and filter out irrelevant object bounding boxes, ensuring that only pertinent objects are considered. Subsequently, these refined bounding boxes serve as specific prompts for the FastSAM model, which executes precise segmentation. Our VTPSeg is validated by experimental and ablation study results on five popular remote sensing image segmentation datasets.
ALMRR: Anomaly Localization Mamba on Industrial Textured Surface with Feature Reconstruction and Refinement
Jul 25, 2024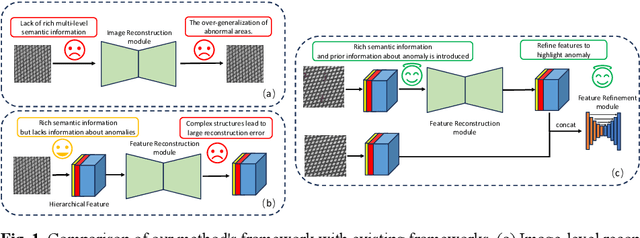

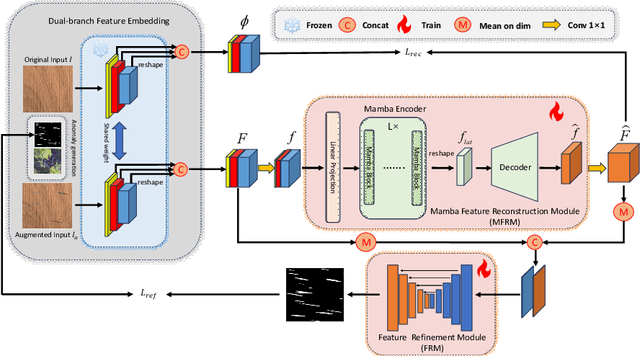

Unsupervised anomaly localization on industrial textured images has achieved remarkable results through reconstruction-based methods, yet existing approaches based on image reconstruction and feature reconstruc-tion each have their own shortcomings. Firstly, image-based methods tend to reconstruct both normal and anomalous regions well, which lead to over-generalization. Feature-based methods contain a large amount of distin-guishable semantic information, however, its feature structure is redundant and lacks anomalous information, which leads to significant reconstruction errors. In this paper, we propose an Anomaly Localization method based on Mamba with Feature Reconstruction and Refinement(ALMRR) which re-constructs semantic features based on Mamba and then refines them through a feature refinement module. To equip the model with prior knowledge of anomalies, we enhance it by adding artificially simulated anomalies to the original images. Unlike image reconstruction or repair, the features of synthesized defects are repaired along with those of normal areas. Finally, the aligned features containing rich semantic information are fed in-to the refinement module to obtain the anomaly map. Extensive experiments have been conducted on the MVTec-AD-Textured dataset and other real-world industrial dataset, which has demonstrated superior performance com-pared to state-of-the-art (SOTA) methods.
VCP-CLIP: A visual context prompting model for zero-shot anomaly segmentation
Jul 17, 2024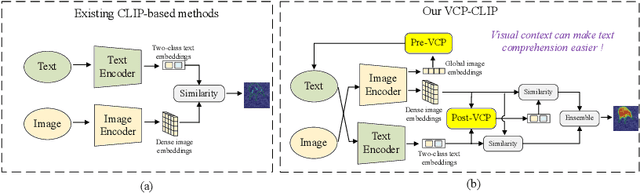
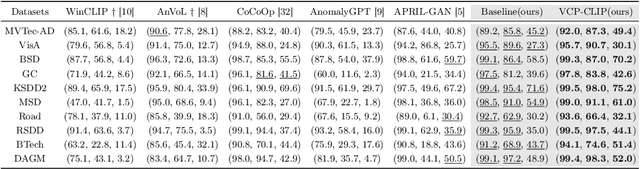
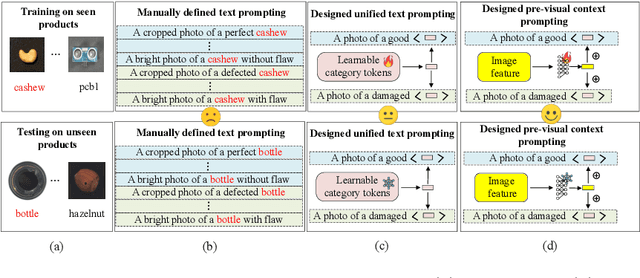

Recently, large-scale vision-language models such as CLIP have demonstrated immense potential in zero-shot anomaly segmentation (ZSAS) task, utilizing a unified model to directly detect anomalies on any unseen product with painstakingly crafted text prompts. However, existing methods often assume that the product category to be inspected is known, thus setting product-specific text prompts, which is difficult to achieve in the data privacy scenarios. Moreover, even the same type of product exhibits significant differences due to specific components and variations in the production process, posing significant challenges to the design of text prompts. In this end, we propose a visual context prompting model (VCP-CLIP) for ZSAS task based on CLIP. The insight behind VCP-CLIP is to employ visual context prompting to activate CLIP's anomalous semantic perception ability. In specific, we first design a Pre-VCP module to embed global visual information into the text prompt, thus eliminating the necessity for product-specific prompts. Then, we propose a novel Post-VCP module, that adjusts the text embeddings utilizing the fine-grained features of the images. In extensive experiments conducted on 10 real-world industrial anomaly segmentation datasets, VCP-CLIP achieved state-of-the-art performance in ZSAS task. The code is available at https://github.com/xiaozhen228/VCP-CLIP.
Investigating Shift Equivalence of Convolutional Neural Networks in Industrial Defect Segmentation
Sep 29, 2023



In industrial defect segmentation tasks, while pixel accuracy and Intersection over Union (IoU) are commonly employed metrics to assess segmentation performance, the output consistency (also referred to equivalence) of the model is often overlooked. Even a small shift in the input image can yield significant fluctuations in the segmentation results. Existing methodologies primarily focus on data augmentation or anti-aliasing to enhance the network's robustness against translational transformations, but their shift equivalence performs poorly on the test set or is susceptible to nonlinear activation functions. Additionally, the variations in boundaries resulting from the translation of input images are consistently disregarded, thus imposing further limitations on the shift equivalence. In response to this particular challenge, a novel pair of down/upsampling layers called component attention polyphase sampling (CAPS) is proposed as a replacement for the conventional sampling layers in CNNs. To mitigate the effect of image boundary variations on the equivalence, an adaptive windowing module is designed in CAPS to adaptively filter out the border pixels of the image. Furthermore, a component attention module is proposed to fuse all downsampled features to improve the segmentation performance. The experimental results on the micro surface defect (MSD) dataset and four real-world industrial defect datasets demonstrate that the proposed method exhibits higher equivalence and segmentation performance compared to other state-of-the-art methods.Our code will be available at https://github.com/xiaozhen228/CAPS.
The Second-place Solution for CVPR VISION 23 Challenge Track 1 -- Data Effificient Defect Detection
Jun 25, 2023



The Vision Challenge Track 1 for Data-Effificient Defect Detection requires competitors to instance segment 14 industrial inspection datasets in a data-defificient setting. This report introduces the technical details of the team Aoi-overfifitting-Team for this challenge. Our method focuses on the key problem of segmentation quality of defect masks in scenarios with limited training samples. Based on the Hybrid Task Cascade (HTC) instance segmentation algorithm, we connect the transformer backbone (Swin-B) through composite connections inspired by CBNetv2 to enhance the baseline results. Additionally, we propose two model ensemble methods to further enhance the segmentation effect: one incorporates semantic segmentation into instance segmentation, while the other employs multi-instance segmentation fusion algorithms. Finally, using multi-scale training and test-time augmentation (TTA), we achieve an average mAP@0.50:0.95 of more than 48.49% and an average mAR@0.50:0.95 of 66.71% on the test set of the Data Effificient Defect Detection Challenge. The code is available at https://github.com/love6tao/Aoi-overfitting-team
Deep Learning for Unsupervised Anomaly Localization in Industrial Images: A Survey
Jul 21, 2022



Currently, deep learning-based visual inspection has been highly successful with the help of supervised learning methods. However, in real industrial scenarios, the scarcity of defect samples, the cost of annotation, and the lack of a priori knowledge of defects may render supervised-based methods ineffective. In recent years, unsupervised anomaly localization algorithms have become more widely used in industrial inspection tasks. This paper aims to help researchers in this field by comprehensively surveying recent achievements in unsupervised anomaly localization in industrial images using deep learning. The survey reviews more than 120 significant publications covering different aspects of anomaly localization, mainly covering various concepts, challenges, taxonomies, benchmark datasets, and quantitative performance comparisons of the methods reviewed. In reviewing the achievements to date, this paper provides detailed predictions and analysis of several future research directions. This review provides detailed technical information for researchers interested in industrial anomaly localization and who wish to apply it to the localization of anomalies in other fields.