 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Prompt Flow Learning for Zero-Shot Anomaly Detection
Mar 13, 2025Recently, vision-language models (e.g. CLIP) have demonstrated remarkable performance in zero-shot anomaly detection (ZSAD). By leveraging auxiliary data during training, these models can directly perform cross-category anomaly detection on target datasets, such as detecting defects on industrial product surfaces or identifying tumors in organ tissues. Existing approaches typically construct text prompts through either manual design or the optimization of learnable prompt vectors. However, these methods face several challenges: 1) handcrafted prompts require extensive expert knowledge and trial-and-error; 2) single-form learnable prompts struggle to capture complex anomaly semantics; and 3) an unconstrained prompt space limit generalization to unseen categories. To address these issues, we propose Bayesian Prompt Flow Learning (Bayes-PFL), which models the prompt space as a learnable probability distribution from a Bayesian perspective. Specifically, a prompt flow module is designed to learn both image-specific and image-agnostic distributions, which are jointly utilized to regularize the text prompt space and enhance the model's generalization on unseen categories. These learned distributions are then sampled to generate diverse text prompts, effectively covering the prompt space. Additionally, a residual cross-attention (RCA) module is introduced to better align dynamic text embeddings with fine-grained image features. Extensive experiments on 15 industrial and medical datasets demonstrate our method's superior performance.
ALMRR: Anomaly Localization Mamba on Industrial Textured Surface with Feature Reconstruction and Refinement
Jul 25, 2024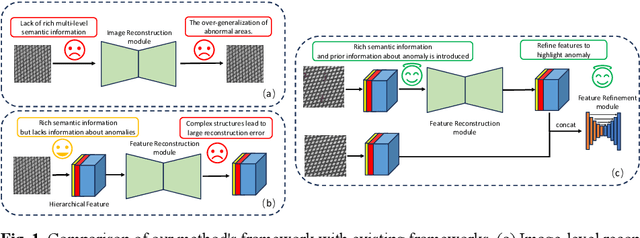

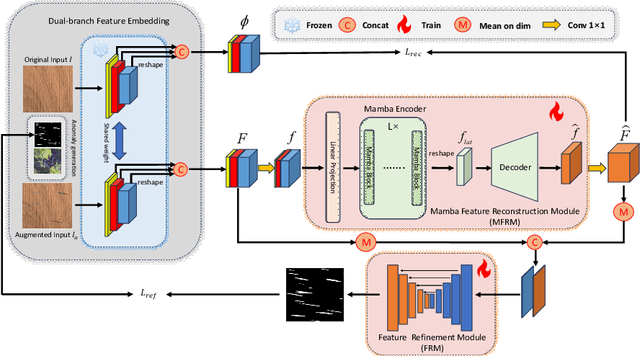

Unsupervised anomaly localization on industrial textured images has achieved remarkable results through reconstruction-based methods, yet existing approaches based on image reconstruction and feature reconstruc-tion each have their own shortcomings. Firstly, image-based methods tend to reconstruct both normal and anomalous regions well, which lead to over-generalization. Feature-based methods contain a large amount of distin-guishable semantic information, however, its feature structure is redundant and lacks anomalous information, which leads to significant reconstruction errors. In this paper, we propose an Anomaly Localization method based on Mamba with Feature Reconstruction and Refinement(ALMRR) which re-constructs semantic features based on Mamba and then refines them through a feature refinement module. To equip the model with prior knowledge of anomalies, we enhance it by adding artificially simulated anomalies to the original images. Unlike image reconstruction or repair, the features of synthesized defects are repaired along with those of normal areas. Finally, the aligned features containing rich semantic information are fed in-to the refinement module to obtain the anomaly map. Extensive experiments have been conducted on the MVTec-AD-Textured dataset and other real-world industrial dataset, which has demonstrated superior performance com-pared to state-of-the-art (SOTA) methods.
VCP-CLIP: A visual context prompting model for zero-shot anomaly segmentation
Jul 17, 2024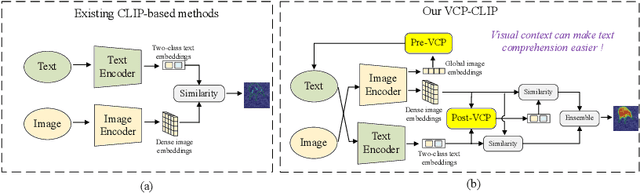
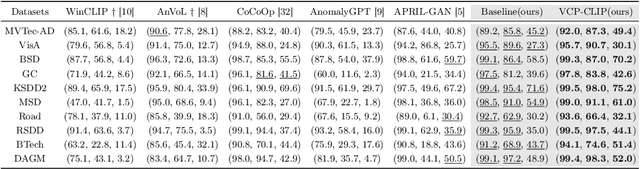
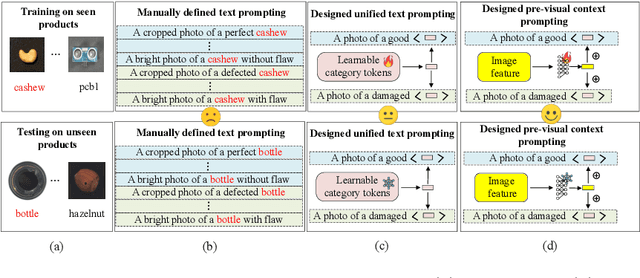

Recently, large-scale vision-language models such as CLIP have demonstrated immense potential in zero-shot anomaly segmentation (ZSAS) task, utilizing a unified model to directly detect anomalies on any unseen product with painstakingly crafted text prompts. However, existing methods often assume that the product category to be inspected is known, thus setting product-specific text prompts, which is difficult to achieve in the data privacy scenarios. Moreover, even the same type of product exhibits significant differences due to specific components and variations in the production process, posing significant challenges to the design of text prompts. In this end, we propose a visual context prompting model (VCP-CLIP) for ZSAS task based on CLIP. The insight behind VCP-CLIP is to employ visual context prompting to activate CLIP's anomalous semantic perception ability. In specific, we first design a Pre-VCP module to embed global visual information into the text prompt, thus eliminating the necessity for product-specific prompts. Then, we propose a novel Post-VCP module, that adjusts the text embeddings utilizing the fine-grained features of the images. In extensive experiments conducted on 10 real-world industrial anomaly segmentation datasets, VCP-CLIP achieved state-of-the-art performance in ZSAS task. The code is available at https://github.com/xiaozhen228/VCP-CLIP.
Deep Learning for Unsupervised Anomaly Localization in Industrial Images: A Survey
Jul 21, 2022



Currently, deep learning-based visual inspection has been highly successful with the help of supervised learning methods. However, in real industrial scenarios, the scarcity of defect samples, the cost of annotation, and the lack of a priori knowledge of defects may render supervised-based methods ineffective. In recent years, unsupervised anomaly localization algorithms have become more widely used in industrial inspection tasks. This paper aims to help researchers in this field by comprehensively surveying recent achievements in unsupervised anomaly localization in industrial images using deep learning. The survey reviews more than 120 significant publications covering different aspects of anomaly localization, mainly covering various concepts, challenges, taxonomies, benchmark datasets, and quantitative performance comparisons of the methods reviewed. In reviewing the achievements to date, this paper provides detailed predictions and analysis of several future research directions. This review provides detailed technical information for researchers interested in industrial anomaly localization and who wish to apply it to the localization of anomalies in other fields.
Cheap or Robust? The Practical Realization of Self-Driving Wheelchair Technology
Jul 13, 2018
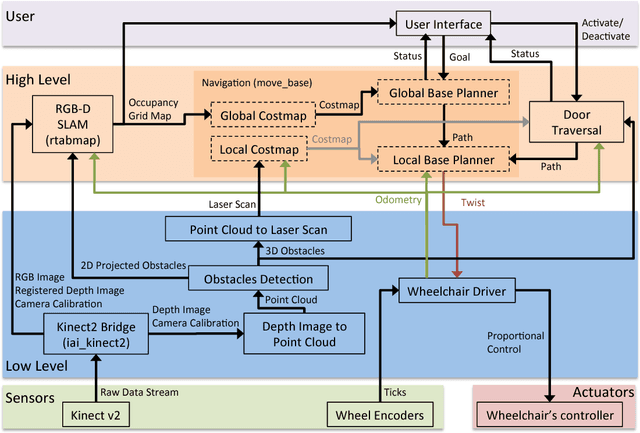

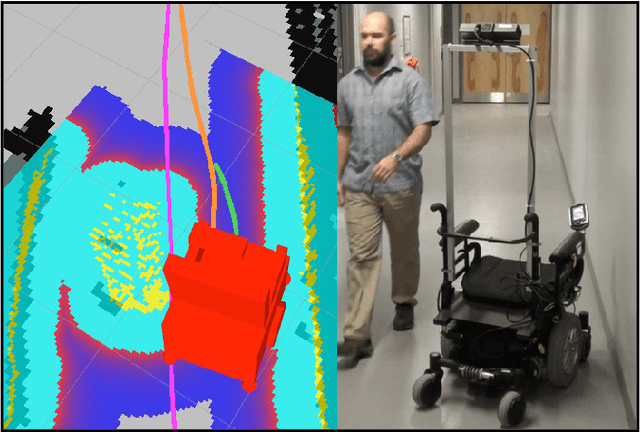
To date, self-driving experimental wheelchair technologies have been either inexpensive or robust, but not both. Yet, in order to achieve real-world acceptance, both qualities are fundamentally essential. We present a unique approach to achieve inexpensive and robust autonomous and semi-autonomous assistive navigation for existing fielded wheelchairs, of which there are approximately 5 million units in Canada and United States alone. Our prototype wheelchair platform is capable of localization and mapping, as well as robust obstacle avoidance, using only a commodity RGB-D sensor and wheel odometry. As a specific example of the navigation capabilities, we focus on the single most common navigation problem: the traversal of narrow doorways in arbitrary environments. The software we have developed is generalizable to corridor following, desk docking, and other navigation tasks that are either extremely difficult or impossible for people with upper-body mobility impairments.