 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShattering the Shortcut: A Topology-Regularized Benchmark for Multi-hop Medical Reasoning in LLMs
Mar 12, 2026While Large Language Models (LLMs) achieve expert-level performance on standard medical benchmarks through single-hop factual recall, they severely struggle with the complex, multi-hop diagnostic reasoning required in real-world clinical settings. A primary obstacle is "shortcut learning", where models exploit highly connected, generic hub nodes (e.g., "inflammation") in knowledge graphs to bypass authentic micro-pathological cascades. To address this, we introduce ShatterMed-QA, a bilingual benchmark of 10,558 multi-hop clinical questions designed to rigorously evaluate deep diagnostic reasoning. Our framework constructs a topology-regularized medical Knowledge Graph using a novel $k$-Shattering algorithm, which physically prunes generic hubs to explicitly sever logical shortcuts. We synthesize the evaluation vignettes by applying implicit bridge entity masking and topology-driven hard negative sampling, forcing models to navigate biologically plausible distractors without relying on superficial elimination. Comprehensive evaluations of 21 LLMs reveal massive performance degradation on our multi-hop tasks, particularly among domain-specific models. Crucially, restoring the masked evidence via Retrieval-Augmented Generation (RAG) triggers near-universal performance recovery, validating ShatterMed-QA's structural fidelity and proving its efficacy in diagnosing the fundamental reasoning deficits of current medical AI. Explore the dataset, interactive examples, and full leaderboards at our project website: https://shattermed-qa-web.vercel.app/
Cross-Domain Few-Shot Learning for Hyperspectral Image Classification Based on Mixup Foundation Model
Jan 30, 2026Although cross-domain few-shot learning (CDFSL) for hyper-spectral image (HSI) classification has attracted significant research interest, existing works often rely on an unrealistic data augmentation procedure in the form of external noise to enlarge the sample size, thus greatly simplifying the issue of data scarcity. They involve a large number of parameters for model updates, being prone to the overfitting problem. To the best of our knowledge, none has explored the strength of the foundation model, having strong generalization power to be quickly adapted to downstream tasks. This paper proposes the MIxup FOundation MOdel (MIFOMO) for CDFSL of HSI classifications. MIFOMO is built upon the concept of a remote sensing (RS) foundation model, pre-trained across a large scale of RS problems, thus featuring generalizable features. The notion of coalescent projection (CP) is introduced to quickly adapt the foundation model to downstream tasks while freezing the backbone network. The concept of mixup domain adaptation (MDM) is proposed to address the extreme domain discrepancy problem. Last but not least, the label smoothing concept is implemented to cope with noisy pseudo-label problems. Our rigorous experiments demonstrate the advantage of MIFOMO, where it beats prior arts with up to 14% margin. The source code of MIFOMO is open-sourced in https://github.com/Naeem- Paeedeh/MIFOMO for reproducibility and convenient further study.
RSVLM-QA: A Benchmark Dataset for Remote Sensing Vision Language Model-based Question Answering
Aug 11, 2025Visual Question Answering (VQA) in remote sensing (RS) is pivotal for interpreting Earth observation data. However, existing RS VQA datasets are constrained by limitations in annotation richness, question diversity, and the assessment of specific reasoning capabilities. This paper introduces RSVLM-QA dataset, a new large-scale, content-rich VQA dataset for the RS domain. RSVLM-QA is constructed by integrating data from several prominent RS segmentation and detection datasets: WHU, LoveDA, INRIA, and iSAID. We employ an innovative dual-track annotation generation pipeline. Firstly, we leverage Large Language Models (LLMs), specifically GPT-4.1, with meticulously designed prompts to automatically generate a suite of detailed annotations including image captions, spatial relations, and semantic tags, alongside complex caption-based VQA pairs. Secondly, to address the challenging task of object counting in RS imagery, we have developed a specialized automated process that extracts object counts directly from the original segmentation data; GPT-4.1 then formulates natural language answers from these counts, which are paired with preset question templates to create counting QA pairs. RSVLM-QA comprises 13,820 images and 162,373 VQA pairs, featuring extensive annotations and diverse question types. We provide a detailed statistical analysis of the dataset and a comparison with existing RS VQA benchmarks, highlighting the superior depth and breadth of RSVLM-QA's annotations. Furthermore, we conduct benchmark experiments on Six mainstream Vision Language Models (VLMs), demonstrating that RSVLM-QA effectively evaluates and challenges the understanding and reasoning abilities of current VLMs in the RS domain. We believe RSVLM-QA will serve as a pivotal resource for the RS VQA and VLM research communities, poised to catalyze advancements in the field.
DualPrompt-MedCap: A Dual-Prompt Enhanced Approach for Medical Image Captioning
Apr 13, 2025



Medical image captioning via vision-language models has shown promising potential for clinical diagnosis assistance. However, generating contextually relevant descriptions with accurate modality recognition remains challenging. We present DualPrompt-MedCap, a novel dual-prompt enhancement framework that augments Large Vision-Language Models (LVLMs) through two specialized components: (1) a modality-aware prompt derived from a semi-supervised classification model pretrained on medical question-answer pairs, and (2) a question-guided prompt leveraging biomedical language model embeddings. To address the lack of captioning ground truth, we also propose an evaluation framework that jointly considers spatial-semantic relevance and medical narrative quality. Experiments on multiple medical datasets demonstrate that DualPrompt-MedCap outperforms the baseline BLIP-3 by achieving a 22% improvement in modality recognition accuracy while generating more comprehensive and question-aligned descriptions. Our method enables the generation of clinically accurate reports that can serve as medical experts' prior knowledge and automatic annotations for downstream vision-language tasks.
AeroLite: Tag-Guided Lightweight Generation of Aerial Image Captions
Apr 13, 2025Accurate and automated captioning of aerial imagery is crucial for applications like environmental monitoring, urban planning, and disaster management. However, this task remains challenging due to complex spatial semantics and domain variability. To address these issues, we introduce \textbf{AeroLite}, a lightweight, tag-guided captioning framework designed to equip small-scale language models (1--3B parameters) with robust and interpretable captioning capabilities specifically for remote sensing images. \textbf{AeroLite} leverages GPT-4o to generate a large-scale, semantically rich pseudo-caption dataset by integrating multiple remote sensing benchmarks, including DLRSD, iSAID, LoveDA, WHU, and RSSCN7. To explicitly capture key semantic elements such as orientation and land-use types, AeroLite employs natural language processing techniques to extract relevant semantic tags. These tags are then learned by a dedicated multi-label CLIP encoder, ensuring precise semantic predictions. To effectively fuse visual and semantic information, we propose a novel bridging multilayer perceptron (MLP) architecture, aligning semantic tags with visual embeddings while maintaining minimal computational overhead. AeroLite's flexible design also enables seamless integration with various pretrained large language models. We adopt a two-stage LoRA-based training approach: the initial stage leverages our pseudo-caption dataset to capture broad remote sensing semantics, followed by fine-tuning on smaller, curated datasets like UCM and Sydney Captions to refine domain-specific alignment. Experimental evaluations demonstrate that AeroLite surpasses significantly larger models (e.g., 13B parameters) in standard captioning metrics, including BLEU and METEOR, while maintaining substantially lower computational costs.
Vision Transformers with Autoencoders and Explainable AI for Cancer Patient Risk Stratification Using Whole Slide Imaging
Apr 08, 2025



Cancer remains one of the leading causes of mortality worldwide, necessitating accurate diagnosis and prognosis. Whole Slide Imaging (WSI) has become an integral part of clinical workflows with advancements in digital pathology. While various studies have utilized WSIs, their extracted features may not fully capture the most relevant pathological information, and their lack of interpretability limits clinical adoption. In this paper, we propose PATH-X, a framework that integrates Vision Transformers (ViT) and Autoencoders with SHAP (Shapley Additive Explanations) to enhance model explainability for patient stratification and risk prediction using WSIs from The Cancer Genome Atlas (TCGA). A representative image slice is selected from each WSI, and numerical feature embeddings are extracted using Google's pre-trained ViT. These features are then compressed via an autoencoder and used for unsupervised clustering and classification tasks. Kaplan-Meier survival analysis is applied to evaluate stratification into two and three risk groups. SHAP is used to identify key contributing features, which are mapped onto histopathological slices to provide spatial context. PATH-X demonstrates strong performance in breast and glioma cancers, where a sufficient number of WSIs enabled robust stratification. However, performance in lung cancer was limited due to data availability, emphasizing the need for larger datasets to enhance model reliability and clinical applicability.
Enhancing Sentiment Analysis through Multimodal Fusion: A BERT-DINOv2 Approach
Mar 11, 2025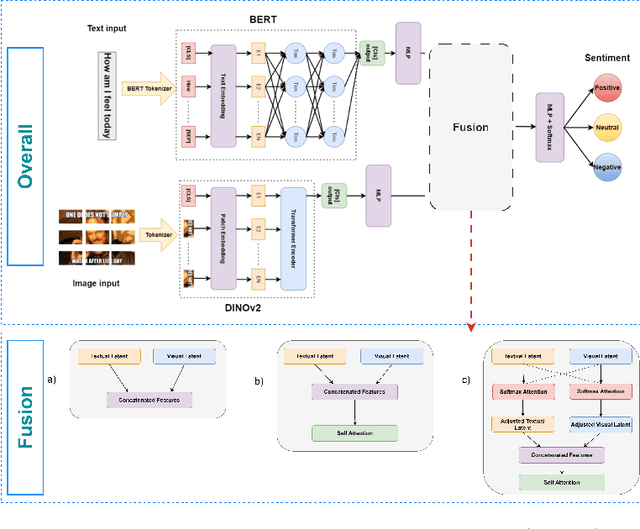
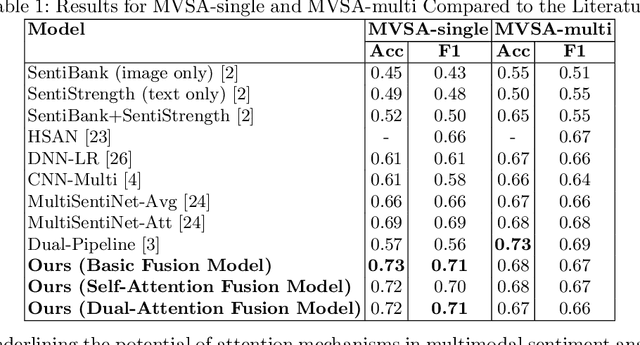
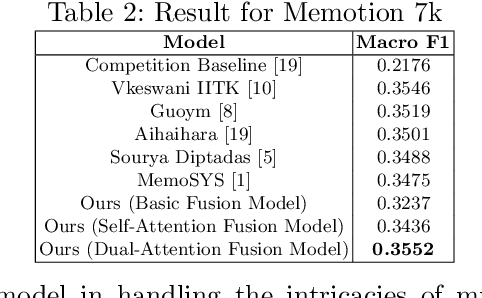
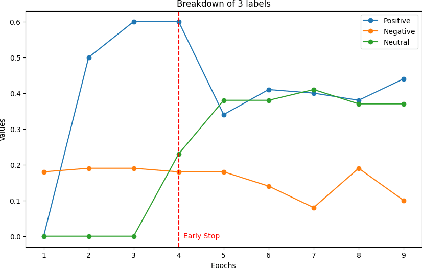
Multimodal sentiment analysis enhances conventional sentiment analysis, which traditionally relies solely on text, by incorporating information from different modalities such as images, text, and audio. This paper proposes a novel multimodal sentiment analysis architecture that integrates text and image data to provide a more comprehensive understanding of sentiments. For text feature extraction, we utilize BERT, a natural language processing model. For image feature extraction, we employ DINOv2, a vision-transformer-based model. The textual and visual latent features are integrated using proposed fusion techniques, namely the Basic Fusion Model, Self Attention Fusion Model, and Dual Attention Fusion Model. Experiments on three datasets, Memotion 7k dataset, MVSA single dataset, and MVSA multi dataset, demonstrate the viability and practicality of the proposed multimodal architecture.
Visual and Text Prompt Segmentation: A Novel Multi-Model Framework for Remote Sensing
Mar 10, 2025Pixel-level segmentation is essential in remote sensing, where foundational vision models like CLIP and Segment Anything Model(SAM) have demonstrated significant capabilities in zero-shot segmentation tasks. Despite their advances, challenges specific to remote sensing remain substantial. Firstly, The SAM without clear prompt constraints, often generates redundant masks, and making post-processing more complex. Secondly, the CLIP model, mainly designed for global feature alignment in foundational models, often overlooks local objects crucial to remote sensing. This oversight leads to inaccurate recognition or misplaced focus in multi-target remote sensing imagery. Thirdly, both models have not been pre-trained on multi-scale aerial views, increasing the likelihood of detection failures. To tackle these challenges, we introduce the innovative VTPSeg pipeline, utilizing the strengths of Grounding DINO, CLIP, and SAM for enhanced open-vocabulary image segmentation. The Grounding DINO+(GD+) module generates initial candidate bounding boxes, while the CLIP Filter++(CLIP++) module uses a combination of visual and textual prompts to refine and filter out irrelevant object bounding boxes, ensuring that only pertinent objects are considered. Subsequently, these refined bounding boxes serve as specific prompts for the FastSAM model, which executes precise segmentation. Our VTPSeg is validated by experimental and ablation study results on five popular remote sensing image segmentation datasets.
Explainable AI Methods for Multi-Omics Analysis: A Survey
Oct 15, 2024

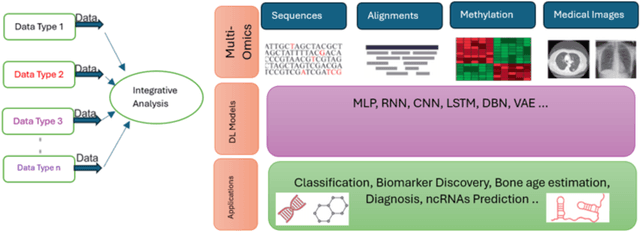
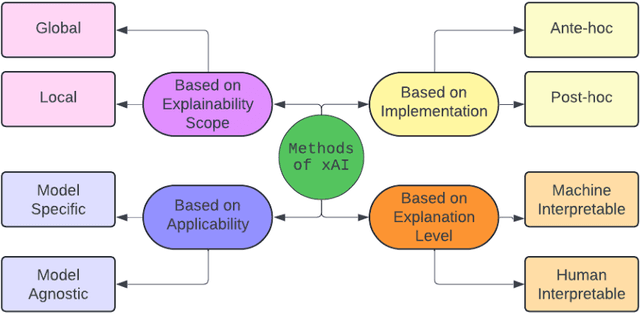
Advancements in high-throughput technologies have led to a shift from traditional hypothesis-driven methodologies to data-driven approaches. Multi-omics refers to the integrative analysis of data derived from multiple 'omes', such as genomics, proteomics, transcriptomics, metabolomics, and microbiomics. This approach enables a comprehensive understanding of biological systems by capturing different layers of biological information. Deep learning methods are increasingly utilized to integrate multi-omics data, offering insights into molecular interactions and enhancing research into complex diseases. However, these models, with their numerous interconnected layers and nonlinear relationships, often function as black boxes, lacking transparency in decision-making processes. To overcome this challenge, explainable artificial intelligence (xAI) methods are crucial for creating transparent models that allow clinicians to interpret and work with complex data more effectively. This review explores how xAI can improve the interpretability of deep learning models in multi-omics research, highlighting its potential to provide clinicians with clear insights, thereby facilitating the effective application of such models in clinical settings.
ALMRR: Anomaly Localization Mamba on Industrial Textured Surface with Feature Reconstruction and Refinement
Jul 25, 2024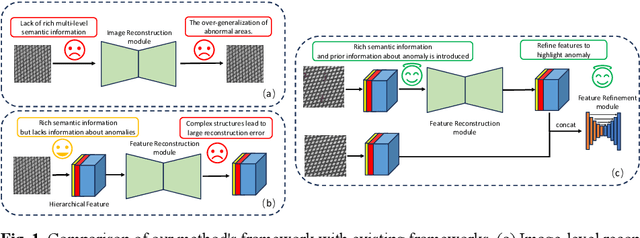

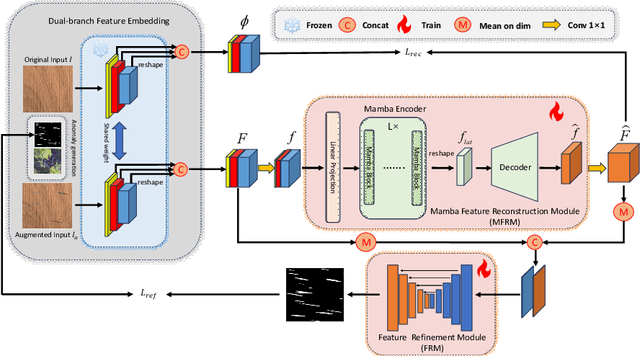

Unsupervised anomaly localization on industrial textured images has achieved remarkable results through reconstruction-based methods, yet existing approaches based on image reconstruction and feature reconstruc-tion each have their own shortcomings. Firstly, image-based methods tend to reconstruct both normal and anomalous regions well, which lead to over-generalization. Feature-based methods contain a large amount of distin-guishable semantic information, however, its feature structure is redundant and lacks anomalous information, which leads to significant reconstruction errors. In this paper, we propose an Anomaly Localization method based on Mamba with Feature Reconstruction and Refinement(ALMRR) which re-constructs semantic features based on Mamba and then refines them through a feature refinement module. To equip the model with prior knowledge of anomalies, we enhance it by adding artificially simulated anomalies to the original images. Unlike image reconstruction or repair, the features of synthesized defects are repaired along with those of normal areas. Finally, the aligned features containing rich semantic information are fed in-to the refinement module to obtain the anomaly map. Extensive experiments have been conducted on the MVTec-AD-Textured dataset and other real-world industrial dataset, which has demonstrated superior performance com-pared to state-of-the-art (SOTA) methods.