 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Understanding Hateful Contents in Memes Through Captioning and Visual Question-Answering
Apr 23, 2025Memes are widely used for humor and cultural commentary, but they are increasingly exploited to spread hateful content. Due to their multimodal nature, hateful memes often evade traditional text-only or image-only detection systems, particularly when they employ subtle or coded references. To address these challenges, we propose a multimodal hate detection framework that integrates key components: OCR to extract embedded text, captioning to describe visual content neutrally, sub-label classification for granular categorization of hateful content, RAG for contextually relevant retrieval, and VQA for iterative analysis of symbolic and contextual cues. This enables the framework to uncover latent signals that simpler pipelines fail to detect. Experimental results on the Facebook Hateful Memes dataset reveal that the proposed framework exceeds the performance of unimodal and conventional multimodal models in both accuracy and AUC-ROC.
Enhancing Sentiment Analysis through Multimodal Fusion: A BERT-DINOv2 Approach
Mar 11, 2025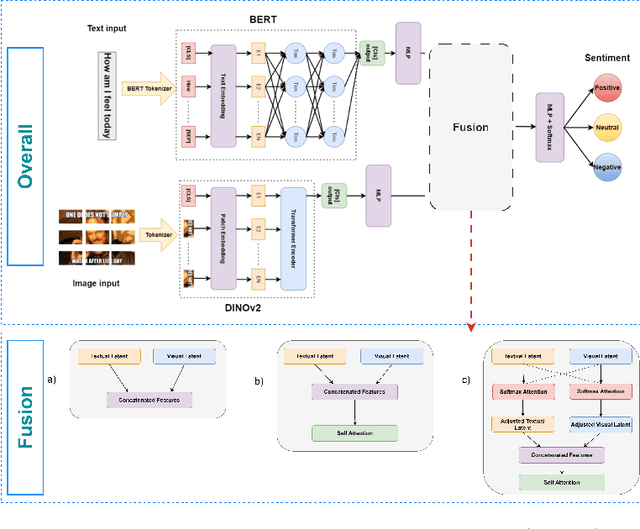
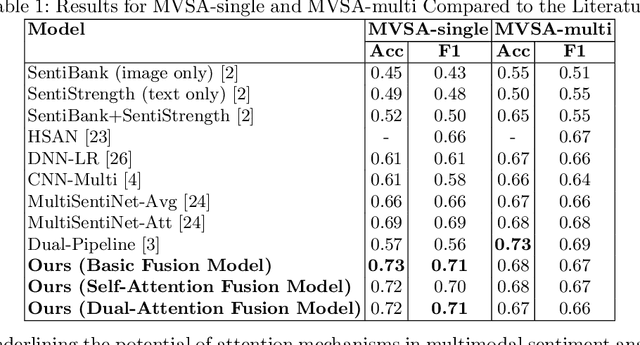
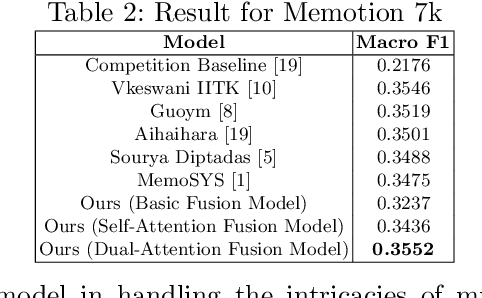
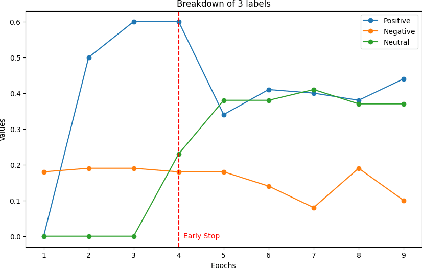
Multimodal sentiment analysis enhances conventional sentiment analysis, which traditionally relies solely on text, by incorporating information from different modalities such as images, text, and audio. This paper proposes a novel multimodal sentiment analysis architecture that integrates text and image data to provide a more comprehensive understanding of sentiments. For text feature extraction, we utilize BERT, a natural language processing model. For image feature extraction, we employ DINOv2, a vision-transformer-based model. The textual and visual latent features are integrated using proposed fusion techniques, namely the Basic Fusion Model, Self Attention Fusion Model, and Dual Attention Fusion Model. Experiments on three datasets, Memotion 7k dataset, MVSA single dataset, and MVSA multi dataset, demonstrate the viability and practicality of the proposed multimodal architecture.
Self-Supervised Object Segmentation with a Cut-and-Pasting GAN
Jan 01, 2023

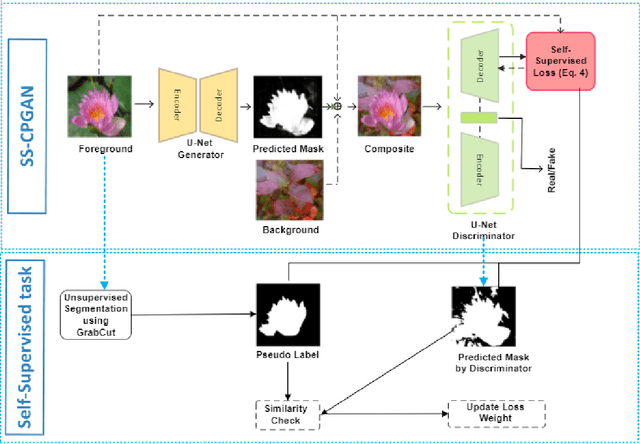

This paper proposes a novel self-supervised based Cut-and-Paste GAN to perform foreground object segmentation and generate realistic composite images without manual annotations. We accomplish this goal by a simple yet effective self-supervised approach coupled with the U-Net based discriminator. The proposed method extends the ability of the standard discriminators to learn not only the global data representations via classification (real/fake) but also learn semantic and structural information through pseudo labels created using the self-supervised task. The proposed method empowers the generator to create meaningful masks by forcing it to learn informative per-pixel as well as global image feedback from the discriminator. Our experiments demonstrate that our proposed method significantly outperforms the state-of-the-art methods on the standard benchmark datasets.