 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Sentiment Analysis through Multimodal Fusion: A BERT-DINOv2 Approach
Paper and Code
Mar 11, 2025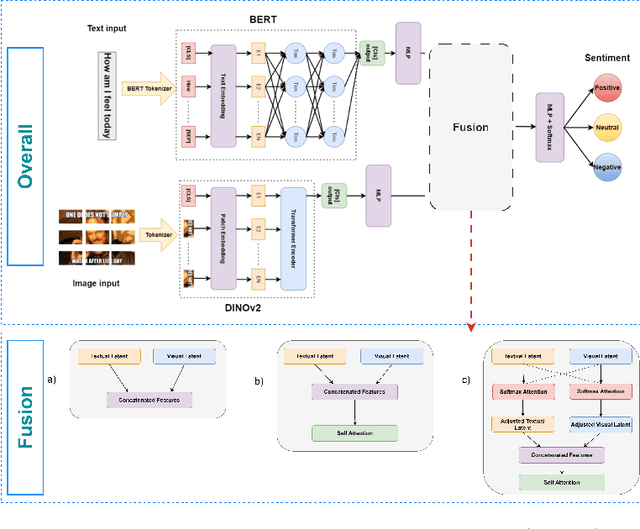
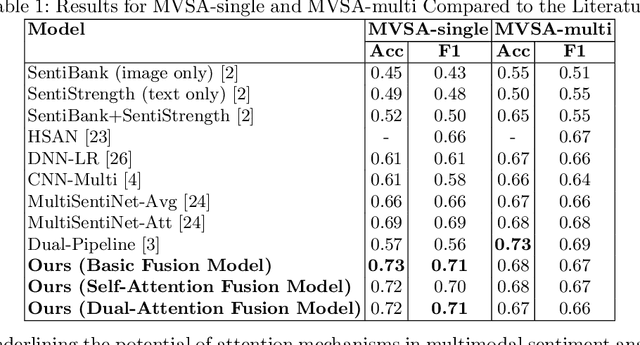
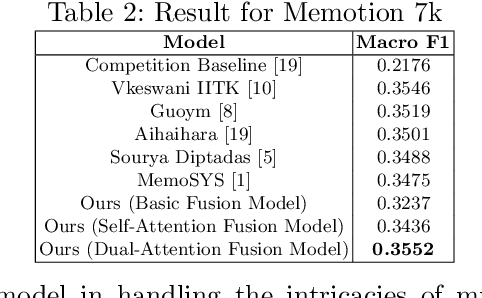
Multimodal sentiment analysis enhances conventional sentiment analysis, which traditionally relies solely on text, by incorporating information from different modalities such as images, text, and audio. This paper proposes a novel multimodal sentiment analysis architecture that integrates text and image data to provide a more comprehensive understanding of sentiments. For text feature extraction, we utilize BERT, a natural language processing model. For image feature extraction, we employ DINOv2, a vision-transformer-based model. The textual and visual latent features are integrated using proposed fusion techniques, namely the Basic Fusion Model, Self Attention Fusion Model, and Dual Attention Fusion Model. Experiments on three datasets, Memotion 7k dataset, MVSA single dataset, and MVSA multi dataset, demonstrate the viability and practicality of the proposed multimodal architecture.