 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Object Segmentation with a Cut-and-Pasting GAN
Paper and Code
Jan 01, 2023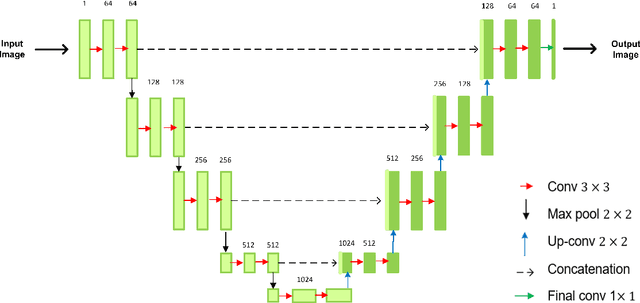

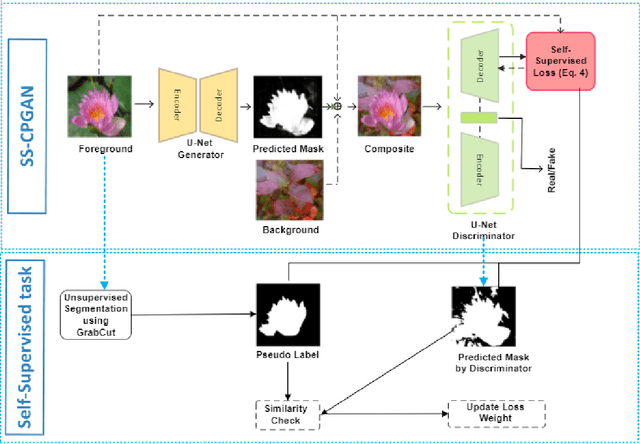

This paper proposes a novel self-supervised based Cut-and-Paste GAN to perform foreground object segmentation and generate realistic composite images without manual annotations. We accomplish this goal by a simple yet effective self-supervised approach coupled with the U-Net based discriminator. The proposed method extends the ability of the standard discriminators to learn not only the global data representations via classification (real/fake) but also learn semantic and structural information through pseudo labels created using the self-supervised task. The proposed method empowers the generator to create meaningful masks by forcing it to learn informative per-pixel as well as global image feedback from the discriminator. Our experiments demonstrate that our proposed method significantly outperforms the state-of-the-art methods on the standard benchmark datasets.