 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegration of Self-Supervised BYOL in Semi-Supervised Medical Image Recognition
Apr 16, 2024



Image recognition techniques heavily rely on abundant labeled data, particularly in medical contexts. Addressing the challenges associated with obtaining labeled data has led to the prominence of self-supervised learning and semi-supervised learning, especially in scenarios with limited annotated data. In this paper, we proposed an innovative approach by integrating self-supervised learning into semi-supervised models to enhance medical image recognition. Our methodology commences with pre-training on unlabeled data utilizing the BYOL method. Subsequently, we merge pseudo-labeled and labeled datasets to construct a neural network classifier, refining it through iterative fine-tuning. Experimental results on three different datasets demonstrate that our approach optimally leverages unlabeled data, outperforming existing methods in terms of accuracy for medical image recognition.
Mixture-of-Domain-Adapters: Decoupling and Injecting Domain Knowledge to Pre-trained Language Models Memories
Jun 08, 2023



Pre-trained language models (PLMs) demonstrate excellent abilities to understand texts in the generic domain while struggling in a specific domain. Although continued pre-training on a large domain-specific corpus is effective, it is costly to tune all the parameters on the domain. In this paper, we investigate whether we can adapt PLMs both effectively and efficiently by only tuning a few parameters. Specifically, we decouple the feed-forward networks (FFNs) of the Transformer architecture into two parts: the original pre-trained FFNs to maintain the old-domain knowledge and our novel domain-specific adapters to inject domain-specific knowledge in parallel. Then we adopt a mixture-of-adapters gate to fuse the knowledge from different domain adapters dynamically. Our proposed Mixture-of-Domain-Adapters (MixDA) employs a two-stage adapter-tuning strategy that leverages both unlabeled data and labeled data to help the domain adaptation: i) domain-specific adapter on unlabeled data; followed by ii) the task-specific adapter on labeled data. MixDA can be seamlessly plugged into the pretraining-finetuning paradigm and our experiments demonstrate that MixDA achieves superior performance on in-domain tasks (GLUE), out-of-domain tasks (ChemProt, RCT, IMDB, Amazon), and knowledge-intensive tasks (KILT). Further analyses demonstrate the reliability, scalability, and efficiency of our method. The code is available at https://github.com/Amano-Aki/Mixture-of-Domain-Adapters.
Geometry-aware data augmentation for monocular 3D object detection
Apr 12, 2021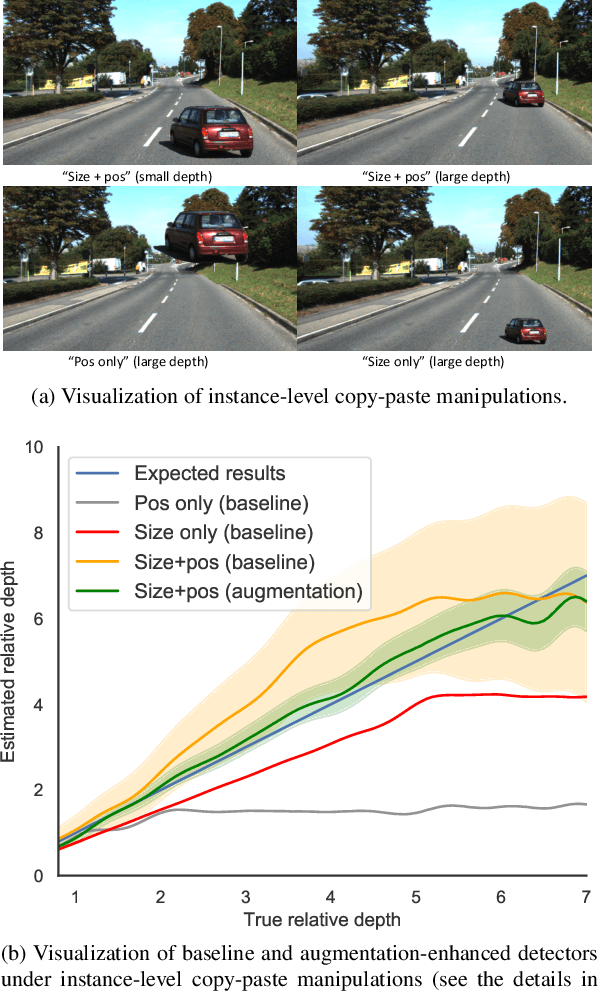
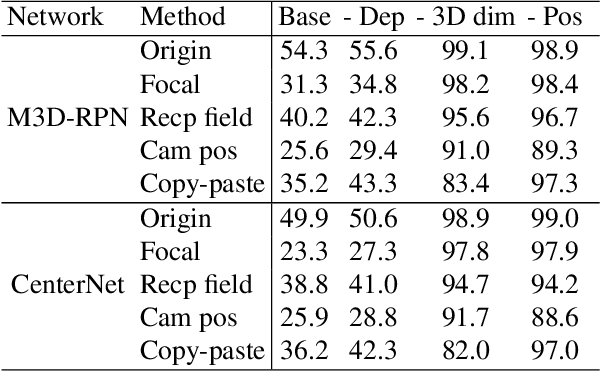

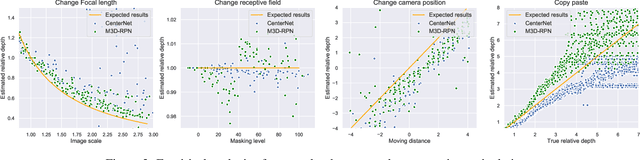
This paper focuses on monocular 3D object detection, one of the essential modules in autonomous driving systems. A key challenge is that the depth recovery problem is ill-posed in monocular data. In this work, we first conduct a thorough analysis to reveal how existing methods fail to robustly estimate depth when different geometry shifts occur. In particular, through a series of image-based and instance-based manipulations for current detectors, we illustrate existing detectors are vulnerable in capturing the consistent relationships between depth and both object apparent sizes and positions. To alleviate this issue and improve the robustness of detectors, we convert the aforementioned manipulations into four corresponding 3D-aware data augmentation techniques. At the image-level, we randomly manipulate the camera system, including its focal length, receptive field and location, to generate new training images with geometric shifts. At the instance level, we crop the foreground objects and randomly paste them to other scenes to generate new training instances. All the proposed augmentation techniques share the virtue that geometry relationships in objects are preserved while their geometry is manipulated. In light of the proposed data augmentation methods, not only the instability of depth recovery is effectively alleviated, but also the final 3D detection performance is significantly improved. This leads to superior improvements on the KITTI and nuScenes monocular 3D detection benchmarks with state-of-the-art results.
Collaborative Training between Region Proposal Localization and Classification for Domain Adaptive Object Detection
Sep 18, 2020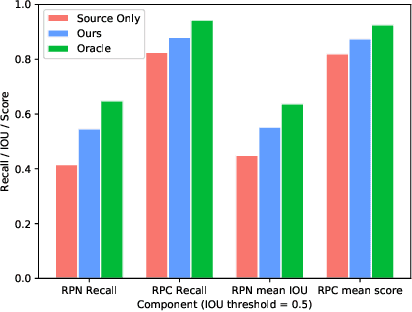


Object detectors are usually trained with large amount of labeled data, which is expensive and labor-intensive. Pre-trained detectors applied to unlabeled dataset always suffer from the difference of dataset distribution, also called domain shift. Domain adaptation for object detection tries to adapt the detector from labeled datasets to unlabeled ones for better performance. In this paper, we are the first to reveal that the region proposal network (RPN) and region proposal classifier~(RPC) in the endemic two-stage detectors (e.g., Faster RCNN) demonstrate significantly different transferability when facing large domain gap. The region classifier shows preferable performance but is limited without RPN's high-quality proposals while simple alignment in the backbone network is not effective enough for RPN adaptation. We delve into the consistency and the difference of RPN and RPC, treat them individually and leverage high-confidence output of one as mutual guidance to train the other. Moreover, the samples with low-confidence are used for discrepancy calculation between RPN and RPC and minimax optimization. Extensive experimental results on various scenarios have demonstrated the effectiveness of our proposed method in both domain-adaptive region proposal generation and object detection. Code is available at https://github.com/GanlongZhao/CST_DA_detection.
An Adversarial Perturbation Oriented Domain Adaptation Approach for Semantic Segmentation
Dec 18, 2019
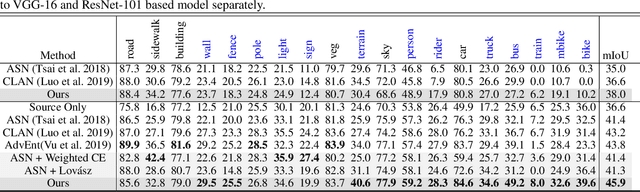
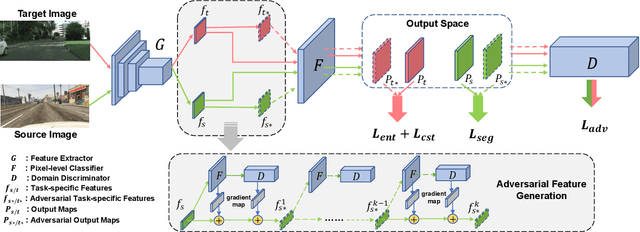
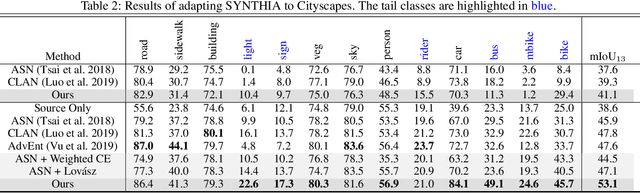
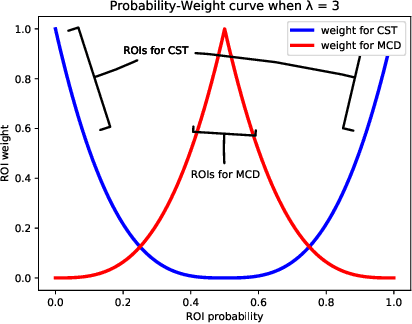
We focus on Unsupervised Domain Adaptation (UDA) for the task of semantic segmentation. Recently, adversarial alignment has been widely adopted to match the marginal distribution of feature representations across two domains globally. However, this strategy fails in adapting the representations of the tail classes or small objects for semantic segmentation since the alignment objective is dominated by head categories or large objects. In contrast to adversarial alignment, we propose to explicitly train a domain-invariant classifier by generating and defensing against pointwise feature space adversarial perturbations. Specifically, we firstly perturb the intermediate feature maps with several attack objectives (i.e., discriminator and classifier) on each individual position for both domains, and then the classifier is trained to be invariant to the perturbations. By perturbing each position individually, our model treats each location evenly regardless of the category or object size and thus circumvents the aforementioned issue. Moreover, the domain gap in feature space is reduced by extrapolating source and target perturbed features towards each other with attack on the domain discriminator. Our approach achieves the state-of-the-art performance on two challenging domain adaptation tasks for semantic segmentation: GTA5 -> Cityscapes and SYNTHIA -> Cityscapes.
Unsupervised Domain Adaptation: An Adaptive Feature Norm Approach
Nov 19, 2018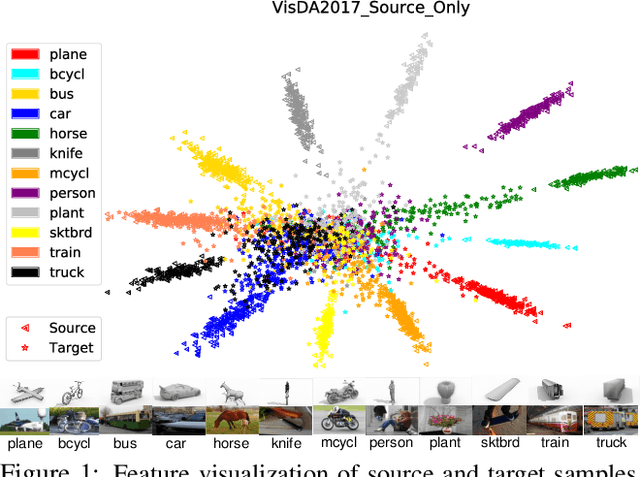
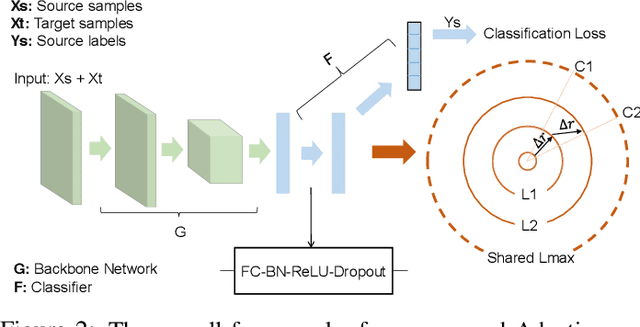
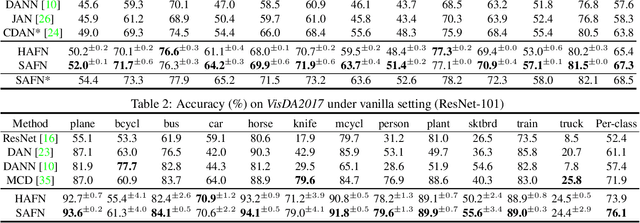
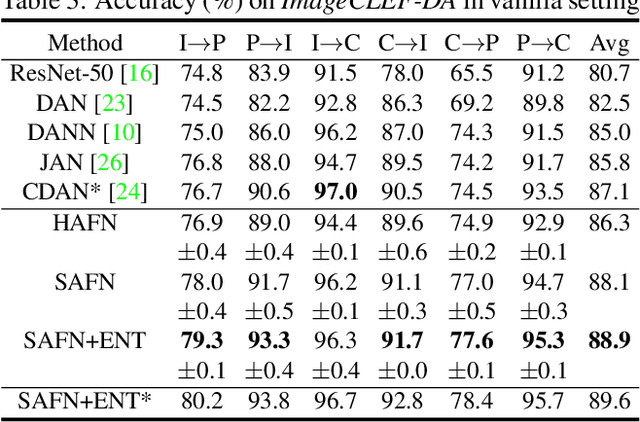
Unsupervised domain adaptation aims to mitigate the domain shift when transferring knowledge from a supervised source domain to an unsupervised target domain. Adversarial Feature Alignment has been successfully explored to minimize the domain discrepancy. However, existing methods are usually struggling to optimize mixed learning objectives and vulnerable to negative transfer when two domains do not share the identical label space. In this paper, we empirically reveal that the erratic discrimination of target domain mainly reflects in its much lower feature norm value with respect to that of the source domain. We present a non-parametric Adaptive Feature Norm AFN approach, which is independent of the association between label spaces of the two domains. We demonstrate that adapting feature norms of source and target domains to achieve equilibrium over a large range of values can result in significant domain transfer gains. Without bells and whistles but a few lines of code, our method largely lifts the discrimination of target domain (23.7\% from the Source Only in VisDA2017) and achieves the new state of the art under the vanilla setting. Furthermore, as our approach does not require to deliberately align the feature distributions, it is robust to negative transfer and can outperform the existing approaches under the partial setting by an extremely large margin (9.8\% on Office-Home and 14.1\% on VisDA2017). Code is available at https://github.com/jihanyang/AFN. We are responsible for the reproducibility of our method.
Deep Cocktail Network: Multi-source Unsupervised Domain Adaptation with Category Shift
Mar 02, 2018
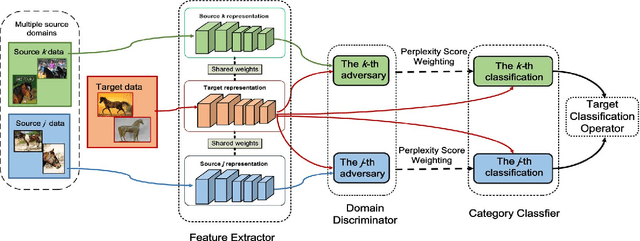
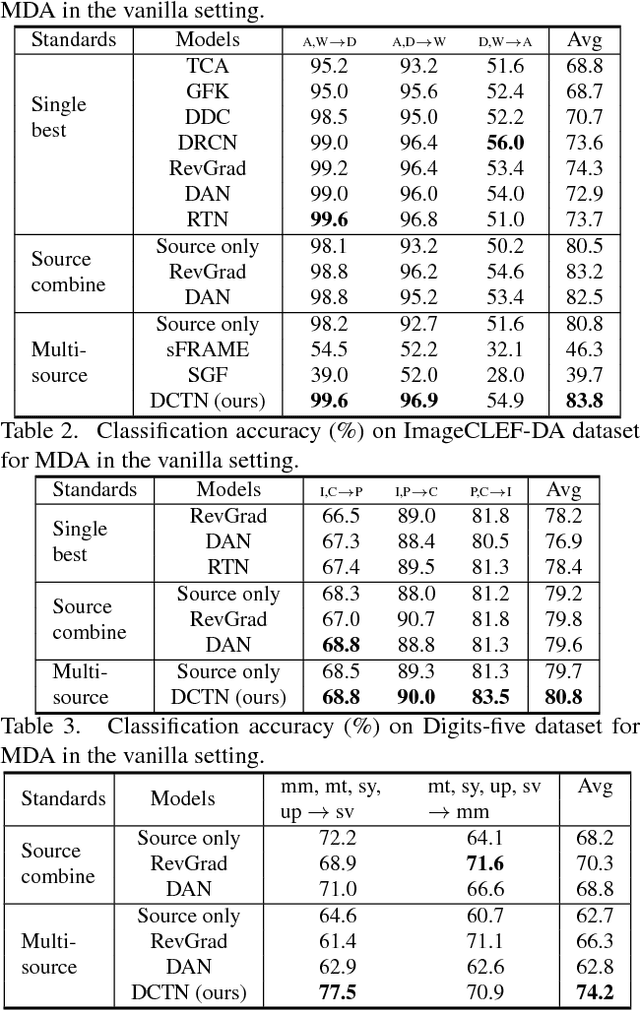

Unsupervised domain adaptation (UDA) conventionally assumes labeled source samples coming from a single underlying source distribution. Whereas in practical scenario, labeled data are typically collected from diverse sources. The multiple sources are different not only from the target but also from each other, thus, domain adaptater should not be modeled in the same way. Moreover, those sources may not completely share their categories, which further brings a new transfer challenge called category shift. In this paper, we propose a deep cocktail network (DCTN) to battle the domain and category shifts among multiple sources. Motivated by the theoretical results in \cite{mansour2009domain}, the target distribution can be represented as the weighted combination of source distributions, and, the multi-source unsupervised domain adaptation via DCTN is then performed as two alternating steps: i) It deploys multi-way adversarial learning to minimize the discrepancy between the target and each of the multiple source domains, which also obtains the source-specific perplexity scores to denote the possibilities that a target sample belongs to different source domains. ii) The multi-source category classifiers are integrated with the perplexity scores to classify target sample, and the pseudo-labeled target samples together with source samples are utilized to update the multi-source category classifier and the feature extractor. We evaluate DCTN in three domain adaptation benchmarks, which clearly demonstrate the superiority of our framework.
Multi-label Image Recognition by Recurrently Discovering Attentional Regions
Nov 08, 2017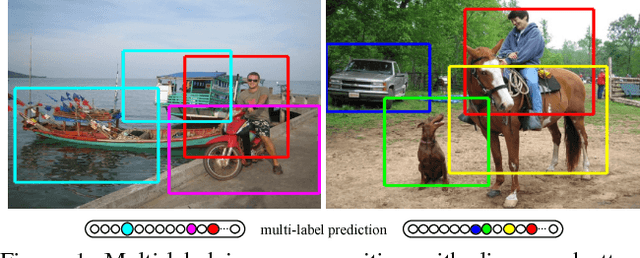


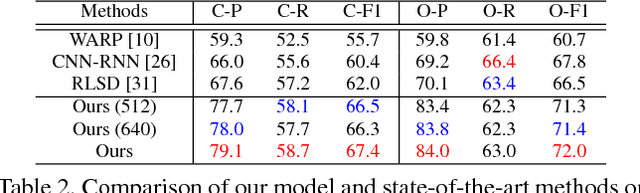
This paper proposes a novel deep architecture to address multi-label image recognition, a fundamental and practical task towards general visual understanding. Current solutions for this task usually rely on an extra step of extracting hypothesis regions (i.e., region proposals), resulting in redundant computation and sub-optimal performance. In this work, we achieve the interpretable and contextualized multi-label image classification by developing a recurrent memorized-attention module. This module consists of two alternately performed components: i) a spatial transformer layer to locate attentional regions from the convolutional feature maps in a region-proposal-free way and ii) an LSTM (Long-Short Term Memory) sub-network to sequentially predict semantic labeling scores on the located regions while capturing the global dependencies of these regions. The LSTM also output the parameters for computing the spatial transformer. On large-scale benchmarks of multi-label image classification (e.g., MS-COCO and PASCAL VOC 07), our approach demonstrates superior performances over other existing state-of-the-arts in both accuracy and efficiency.