 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEDL-U: Uncertainty-aware 3D Automatic Annotator based on Evidential Deep Learning
Sep 18, 2023



Advancements in deep learning-based 3D object detection necessitate the availability of large-scale datasets. However, this requirement introduces the challenge of manual annotation, which is often both burdensome and time-consuming. To tackle this issue, the literature has seen the emergence of several weakly supervised frameworks for 3D object detection which can automatically generate pseudo labels for unlabeled data. Nevertheless, these generated pseudo labels contain noise and are not as accurate as those labeled by humans. In this paper, we present the first approach that addresses the inherent ambiguities present in pseudo labels by introducing an Evidential Deep Learning (EDL) based uncertainty estimation framework. Specifically, we propose MEDL-U, an EDL framework based on MTrans, which not only generates pseudo labels but also quantifies the associated uncertainties. However, applying EDL to 3D object detection presents three primary challenges: (1) relatively lower pseudolabel quality in comparison to other autolabelers; (2) excessively high evidential uncertainty estimates; and (3) lack of clear interpretability and effective utilization of uncertainties for downstream tasks. We tackle these issues through the introduction of an uncertainty-aware IoU-based loss, an evidence-aware multi-task loss function, and the implementation of a post-processing stage for uncertainty refinement. Our experimental results demonstrate that probabilistic detectors trained using the outputs of MEDL-U surpass deterministic detectors trained using outputs from previous 3D annotators on the KITTI val set for all difficulty levels. Moreover, MEDL-U achieves state-of-the-art results on the KITTI official test set compared to existing 3D automatic annotators.
Geometry-aware data augmentation for monocular 3D object detection
Apr 12, 2021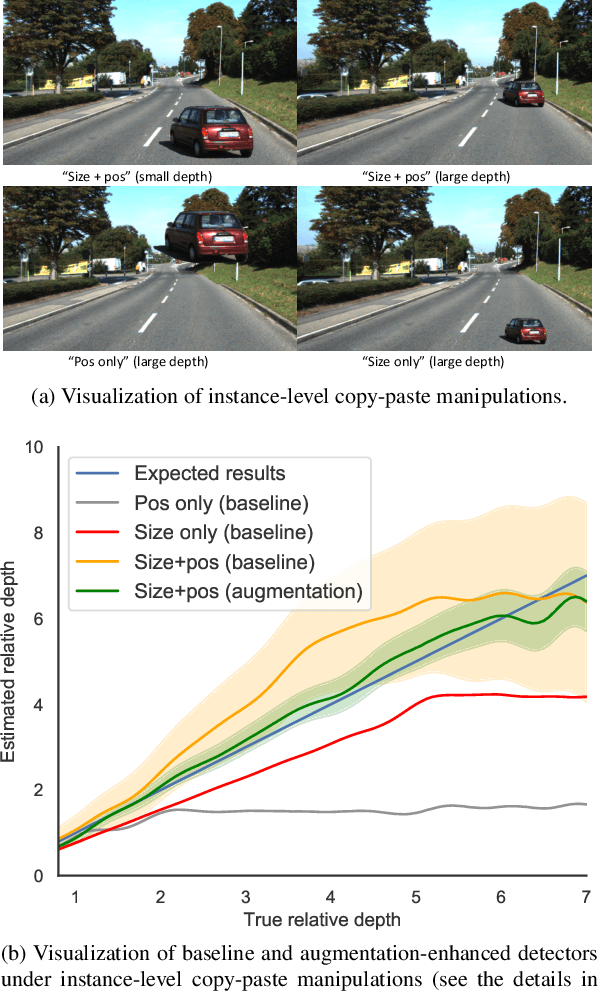
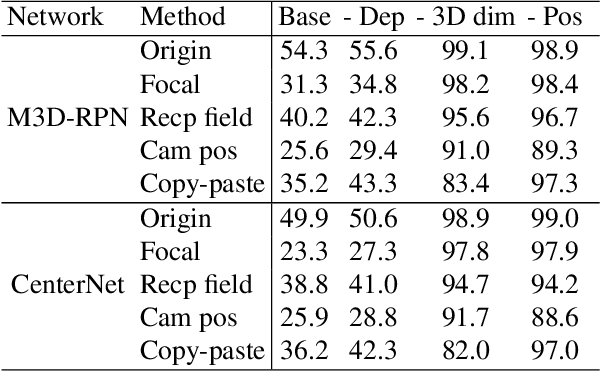

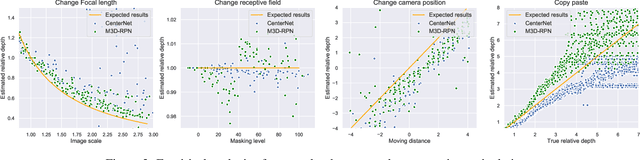
This paper focuses on monocular 3D object detection, one of the essential modules in autonomous driving systems. A key challenge is that the depth recovery problem is ill-posed in monocular data. In this work, we first conduct a thorough analysis to reveal how existing methods fail to robustly estimate depth when different geometry shifts occur. In particular, through a series of image-based and instance-based manipulations for current detectors, we illustrate existing detectors are vulnerable in capturing the consistent relationships between depth and both object apparent sizes and positions. To alleviate this issue and improve the robustness of detectors, we convert the aforementioned manipulations into four corresponding 3D-aware data augmentation techniques. At the image-level, we randomly manipulate the camera system, including its focal length, receptive field and location, to generate new training images with geometric shifts. At the instance level, we crop the foreground objects and randomly paste them to other scenes to generate new training instances. All the proposed augmentation techniques share the virtue that geometry relationships in objects are preserved while their geometry is manipulated. In light of the proposed data augmentation methods, not only the instability of depth recovery is effectively alleviated, but also the final 3D detection performance is significantly improved. This leads to superior improvements on the KITTI and nuScenes monocular 3D detection benchmarks with state-of-the-art results.