 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-aware data augmentation for monocular 3D object detection
Paper and Code
Apr 12, 2021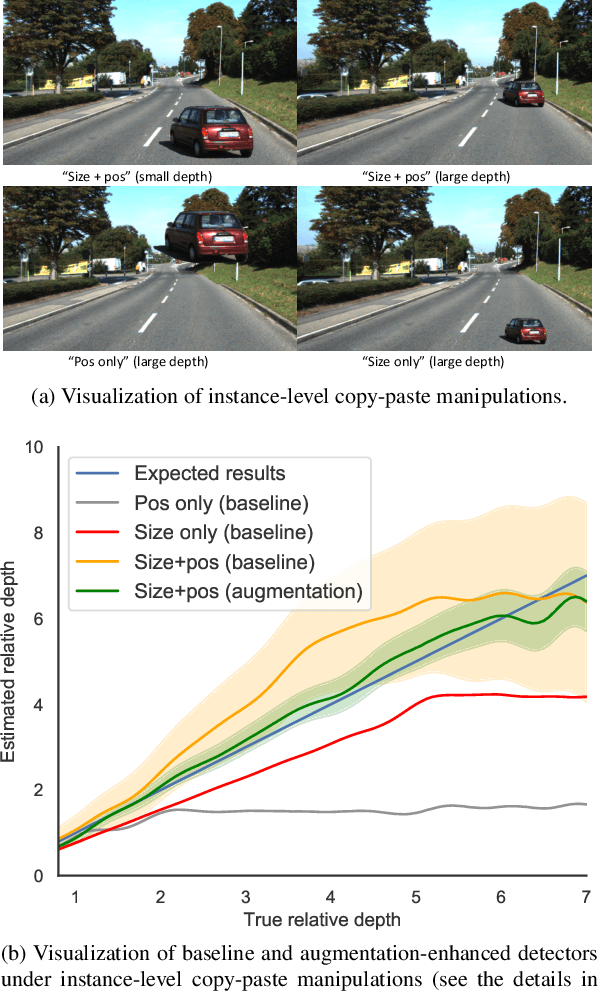
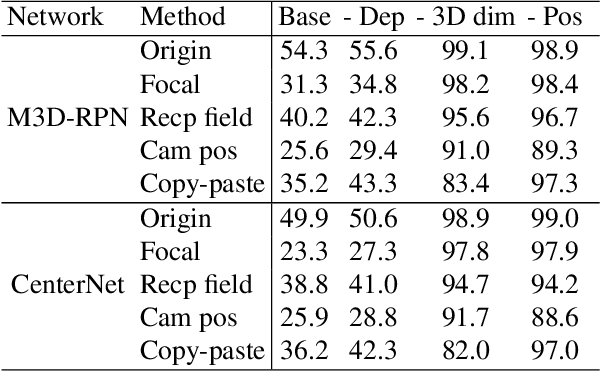

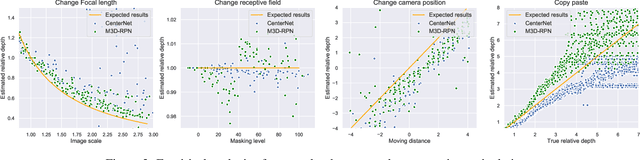
This paper focuses on monocular 3D object detection, one of the essential modules in autonomous driving systems. A key challenge is that the depth recovery problem is ill-posed in monocular data. In this work, we first conduct a thorough analysis to reveal how existing methods fail to robustly estimate depth when different geometry shifts occur. In particular, through a series of image-based and instance-based manipulations for current detectors, we illustrate existing detectors are vulnerable in capturing the consistent relationships between depth and both object apparent sizes and positions. To alleviate this issue and improve the robustness of detectors, we convert the aforementioned manipulations into four corresponding 3D-aware data augmentation techniques. At the image-level, we randomly manipulate the camera system, including its focal length, receptive field and location, to generate new training images with geometric shifts. At the instance level, we crop the foreground objects and randomly paste them to other scenes to generate new training instances. All the proposed augmentation techniques share the virtue that geometry relationships in objects are preserved while their geometry is manipulated. In light of the proposed data augmentation methods, not only the instability of depth recovery is effectively alleviated, but also the final 3D detection performance is significantly improved. This leads to superior improvements on the KITTI and nuScenes monocular 3D detection benchmarks with state-of-the-art results.