 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegration of Self-Supervised BYOL in Semi-Supervised Medical Image Recognition
Apr 16, 2024



Image recognition techniques heavily rely on abundant labeled data, particularly in medical contexts. Addressing the challenges associated with obtaining labeled data has led to the prominence of self-supervised learning and semi-supervised learning, especially in scenarios with limited annotated data. In this paper, we proposed an innovative approach by integrating self-supervised learning into semi-supervised models to enhance medical image recognition. Our methodology commences with pre-training on unlabeled data utilizing the BYOL method. Subsequently, we merge pseudo-labeled and labeled datasets to construct a neural network classifier, refining it through iterative fine-tuning. Experimental results on three different datasets demonstrate that our approach optimally leverages unlabeled data, outperforming existing methods in terms of accuracy for medical image recognition.
Damage GAN: A Generative Model for Imbalanced Data
Dec 08, 2023This study delves into the application of Generative Adversarial Networks (GANs) within the context of imbalanced datasets. Our primary aim is to enhance the performance and stability of GANs in such datasets. In pursuit of this objective, we introduce a novel network architecture known as Damage GAN, building upon the ContraD GAN framework which seamlessly integrates GANs and contrastive learning. Through the utilization of contrastive learning, the discriminator is trained to develop an unsupervised representation capable of distinguishing all provided samples. Our approach draws inspiration from the straightforward framework for contrastive learning of visual representations (SimCLR), leading to the formulation of a distinctive loss function. We also explore the implementation of self-damaging contrastive learning (SDCLR) to further enhance the optimization of the ContraD GAN model. Comparative evaluations against baseline models including the deep convolutional GAN (DCGAN) and ContraD GAN demonstrate the evident superiority of our proposed model, Damage GAN, in terms of generated image distribution, model stability, and image quality when applied to imbalanced datasets.
ResNLS: An Improved Model for Stock Price Forecasting
Dec 02, 2023Stock prices forecasting has always been a challenging task. Although many research projects adopt machine learning and deep learning algorithms to address the problem, few of them pay attention to the varying degrees of dependencies between stock prices. In this paper we introduce a hybrid model that improves stock price prediction by emphasizing the dependencies between adjacent stock prices. The proposed model, ResNLS, is mainly composed of two neural architectures, ResNet and LSTM. ResNet serves as a feature extractor to identify dependencies between stock prices across time windows, while LSTM analyses the initial time-series data with the combination of dependencies which considered as residuals. In predicting the SSE Composite Index, our experiment reveals that when the closing price data for the previous 5 consecutive trading days is used as the input, the performance of the model (ResNLS-5) is optimal compared to those with other inputs. Furthermore, ResNLS-5 outperforms vanilla CNN, RNN, LSTM, and BiLSTM models in terms of prediction accuracy. It also demonstrates at least a 20% improvement over the current state-of-the-art baselines. To verify whether ResNLS-5 can help clients effectively avoid risks and earn profits in the stock market, we construct a quantitative trading framework for back testing. The experimental results show that the trading strategy based on predictions from ResNLS-5 can successfully mitigate losses during declining stock prices and generate profits in the periods of rising stock prices.
In-game Toxic Language Detection: Shared Task and Attention Residuals
Nov 19, 2022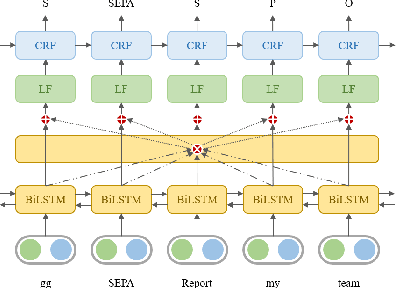
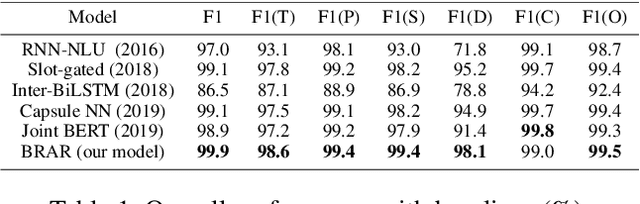
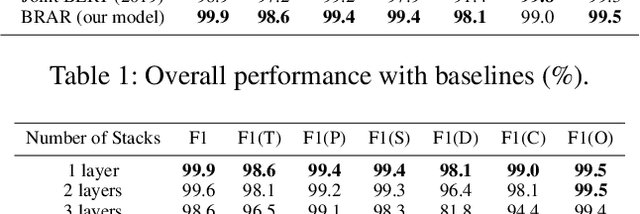
In-game toxic language becomes the hot potato in the gaming industry and community. There have been several online game toxicity analysis frameworks and models proposed. However, it is still challenging to detect toxicity due to the nature of in-game chat, which has extremely short length. In this paper, we describe how the in-game toxic language shared task has been established using the real-world in-game chat data. In addition, we propose and introduce the model/framework for toxic language token tagging (slot filling) from the in-game chat. The data and code will be released.