 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster Regularized Quantization for Deep Networks Compression
Feb 27, 2019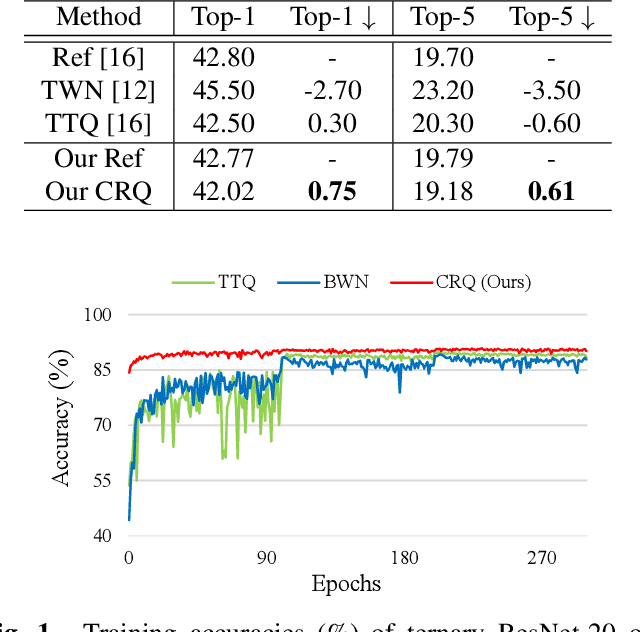


Deep neural networks (DNNs) have achieved great success in a wide range of computer vision areas, but the applications to mobile devices is limited due to their high storage and computational cost. Much efforts have been devoted to compress DNNs. In this paper, we propose a simple yet effective method for deep networks compression, named Cluster Regularized Quantization (CRQ), which can reduce the presentation precision of a full-precision model to ternary values without significant accuracy drop. In particular, the proposed method aims at reducing the quantization error by introducing a cluster regularization term, which is imposed on the full-precision weights to enable them naturally concentrate around the target values. Through explicitly regularizing the weights during the re-training stage, the full-precision model can achieve the smooth transition to the low-bit one. Comprehensive experiments on benchmark datasets demonstrate the effectiveness of the proposed method.