 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillClaw: Let Skills Evolve Collectively with Agentic Evolver
Apr 09, 2026Large language model (LLM) agents such as OpenClaw rely on reusable skills to perform complex tasks, yet these skills remain largely static after deployment. As a result, similar workflows, tool usage patterns, and failure modes are repeatedly rediscovered across users, preventing the system from improving with experience. While interactions from different users provide complementary signals about when a skill works or fails, existing systems lack a mechanism to convert such heterogeneous experiences into reliable skill updates. To address these issues, we present SkillClaw, a framework for collective skill evolution in multi-user agent ecosystems, which treats cross-user and over-time interactions as the primary signal for improving skills. SkillClaw continuously aggregates trajectories generated during use and processes them with an autonomous evolver, which identifies recurring behavioral patterns and translates them into updates to the skill set by refining existing skills or extending them with new capabilities. The resulting skills are maintained in a shared repository and synchronized across users, allowing improvements discovered in one context to propagate system-wide while requiring no additional effort from users. By integrating multi-user experience into ongoing skill updates, SkillClaw enables cross-user knowledge transfer and cumulative capability improvement, and experiments on WildClawBench show that limited interaction and feedback, it significantly improves the performance of Qwen3-Max in real-world agent scenarios.
Where and What Matters: Sensitivity-Aware Task Vectors for Many-Shot Multimodal In-Context Learning
Nov 11, 2025Large Multimodal Models (LMMs) have shown promising in-context learning (ICL) capabilities, but scaling to many-shot settings remains difficult due to limited context length and high inference cost. To address these challenges, task-vector-based methods have been explored by inserting compact representations of many-shot in-context demonstrations into model activations. However, existing task-vector-based methods either overlook the importance of where to insert task vectors or struggle to determine suitable values for each location. To this end, we propose a novel Sensitivity-aware Task Vector insertion framework (STV) to figure out where and what to insert. Our key insight is that activation deltas across query-context pairs exhibit consistent structural patterns, providing a reliable cue for insertion. Based on the identified sensitive-aware locations, we construct a pre-clustered activation bank for each location by clustering the activation values, and then apply reinforcement learning to choose the most suitable one to insert. We evaluate STV across a range of multimodal models (e.g., Qwen-VL, Idefics-2) and tasks (e.g., VizWiz, OK-VQA), demonstrating its effectiveness and showing consistent improvements over previous task-vector-based methods with strong generalization.
Consensus-Based Dynamic Task Allocation for Multi-Robot System Considering Payloads Consumption
Dec 13, 2024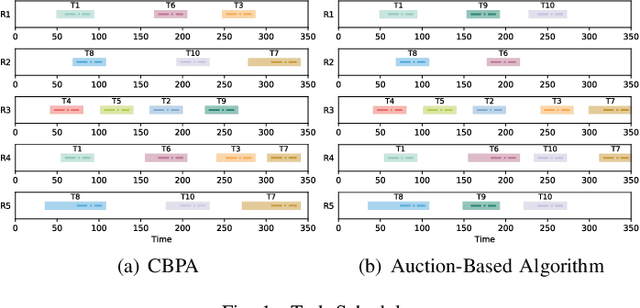

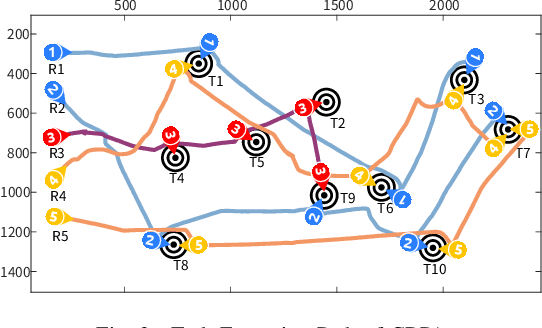
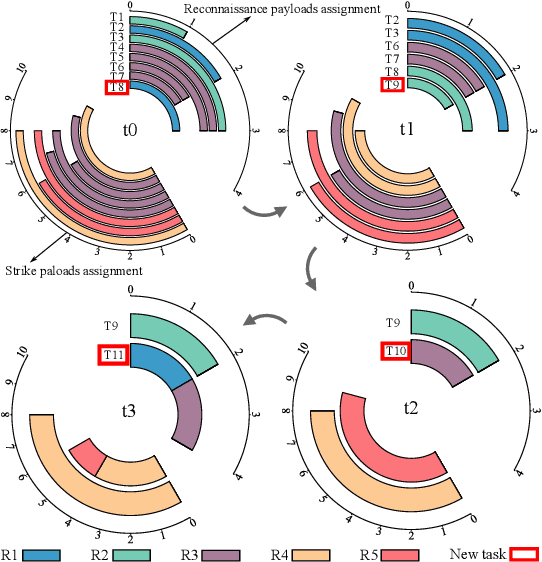
This paper presents a consensus-based payload algorithm (CBPA) to deal with the condition of robots' capability decrease for multi-robot task allocation. During the execution of complex tasks, robots' capabilities could decrease with the consumption of payloads, which causes a problem that the robot coalition would not meet the tasks' requirements in real time. The proposed CBPA is an enhanced version of the consensus-based bundle algorithm (CBBA) and comprises two primary core phases: the payload bundle construction and consensus phases. In the payload bundle construction phase, CBPA introduces a payload assignment matrix to track the payloads carried by the robots and the demands of multi-robot tasks in real time. Then, robots share their respective payload assignment matrix in the consensus phase. These two phases are iterated to dynamically adjust the number of robots performing multi-robot tasks and the number of tasks each robot performs and obtain conflict-free results to ensure that the robot coalition meets the demand and completes all tasks as quickly as possible. Physical experiment shows that CBPA is appropriate in complex and dynamic scenarios where robots need to collaborate and task requirements are tightly coupled to the robots' payloads. Numerical experiments show that CBPA has higher total task gains than CBBA.
MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
Feb 06, 2024We introduce MobileVLM V2, a family of significantly improved vision language models upon MobileVLM, which proves that a delicate orchestration of novel architectural design, an improved training scheme tailored for mobile VLMs, and rich high-quality dataset curation can substantially benefit VLMs' performance. Specifically, MobileVLM V2 1.7B achieves better or on-par performance on standard VLM benchmarks compared with much larger VLMs at the 3B scale. Notably, our 3B model outperforms a large variety of VLMs at the 7B+ scale. Our models will be released at https://github.com/Meituan-AutoML/MobileVLM .
MobileVLM : A Fast, Strong and Open Vision Language Assistant for Mobile Devices
Dec 30, 2023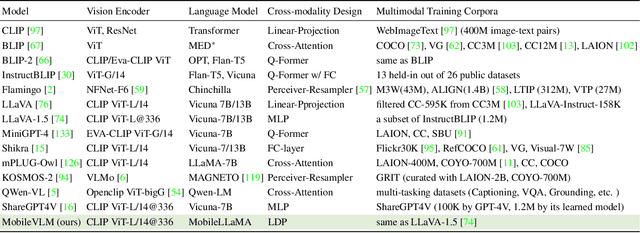
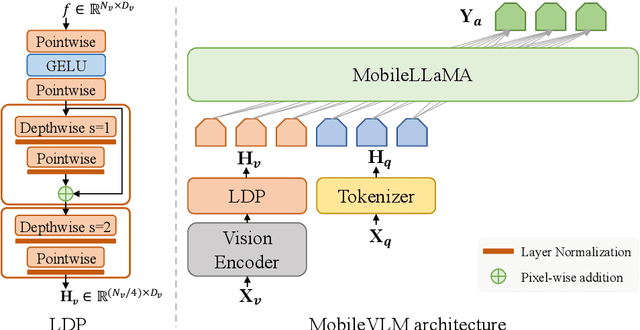
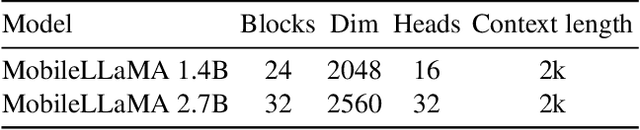
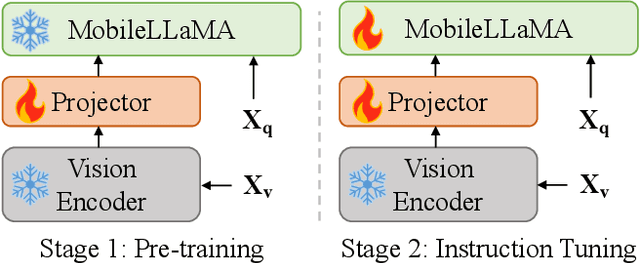
We present MobileVLM, a competent multimodal vision language model (MMVLM) targeted to run on mobile devices. It is an amalgamation of a myriad of architectural designs and techniques that are mobile-oriented, which comprises a set of language models at the scale of 1.4B and 2.7B parameters, trained from scratch, a multimodal vision model that is pre-trained in the CLIP fashion, cross-modality interaction via an efficient projector. We evaluate MobileVLM on several typical VLM benchmarks. Our models demonstrate on par performance compared with a few much larger models. More importantly, we measure the inference speed on both a Qualcomm Snapdragon 888 CPU and an NVIDIA Jeston Orin GPU, and we obtain state-of-the-art performance of 21.5 tokens and 65.3 tokens per second, respectively. Our code will be made available at: https://github.com/Meituan-AutoML/MobileVLM.
Masked Autoencoders Are Robust Neural Architecture Search Learners
Nov 20, 2023



Neural Architecture Search (NAS) currently relies heavily on labeled data, which is both expensive and time-consuming to acquire. In this paper, we propose a novel NAS framework based on Masked Autoencoders (MAE) that eliminates the need for labeled data during the search process. By replacing the supervised learning objective with an image reconstruction task, our approach enables the robust discovery of network architectures without compromising performance and generalization ability. Additionally, we address the problem of performance collapse encountered in the widely-used Differentiable Architecture Search (DARTS) method in the unsupervised paradigm by introducing a multi-scale decoder. Through extensive experiments conducted on various search spaces and datasets, we demonstrate the effectiveness and robustness of the proposed method, providing empirical evidence of its superiority over baseline approaches.
Exploring the impact of weather on Metro demand forecasting using machine learning method
Oct 24, 2022



Urban rail transit provides significant comprehensive benefits such as large traffic volume and high speed, serving as one of the most important components of urban traffic construction management and congestion solution. Using real passenger flow data of an Asian subway system from April to June of 2018, this work analyzes the space-time distribution of the passenger flow using short-term traffic flow prediction. Stations are divided into four types for passenger flow forecasting, and meteorological records are collected for the same period. Then, machine learning methods with different inputs are applied and multivariate regression is performed to evaluate the improvement effect of each weather element on passenger flow forecasting of representative metro stations on hourly basis. Our results show that by inputting weather variables the precision of prediction on weekends enhanced while the performance on weekdays only improved marginally, while the contribution of different elements of weather differ. Also, different categories of stations are affected differently by weather. This study provides a possible method to further improve other prediction models, and attests to the promise of data-driven analytics for optimization of short-term scheduling in transit management.
DPUV3INT8: A Compiler View to programmable FPGA Inference Engines
Oct 08, 2021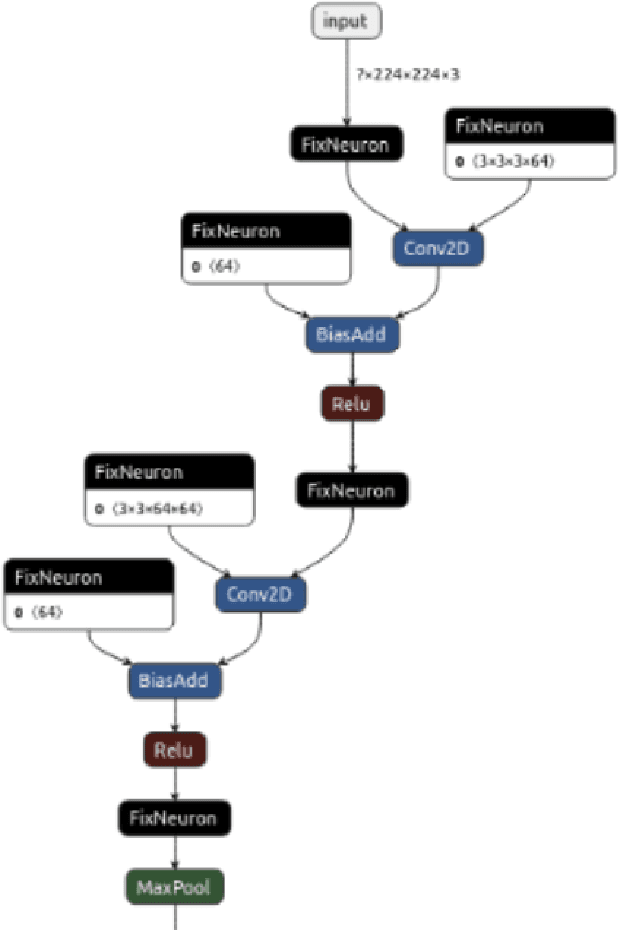
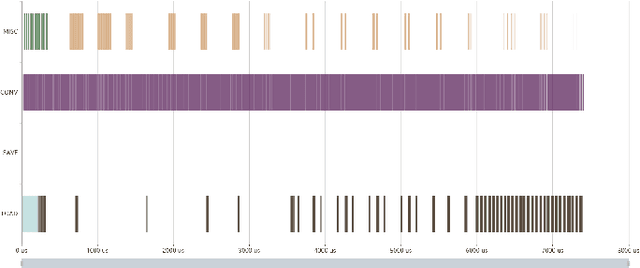
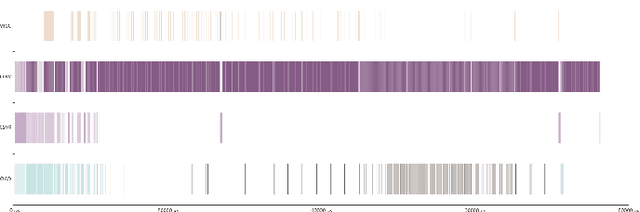
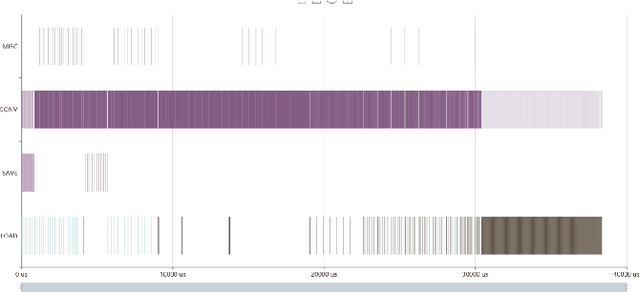
We have a FPGA design, we make it fast, efficient, and tested for a few important examples. Now we must infer a general solution to deploy in the data center. Here, we describe the FPGA DPUV3INT8 design and our compiler effort. The hand-tuned SW-HW solution for Resnet50\_v1 has (close to) 2 times better images per second (throughput) than our best FPGA implementation; the compiler generalizes the hand written techniques achieving about 1.5 times better performance for the same example, the compiler generalizes the optimizations to a model zoo of networks, and it achieves 80+\% HW efficiency.
Angle-based Search Space Shrinking for Neural Architecture Search
May 01, 2020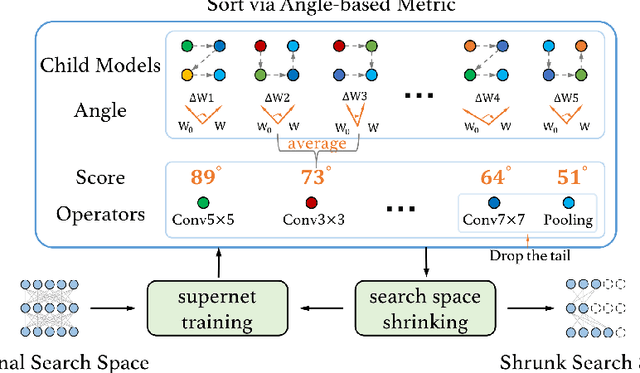


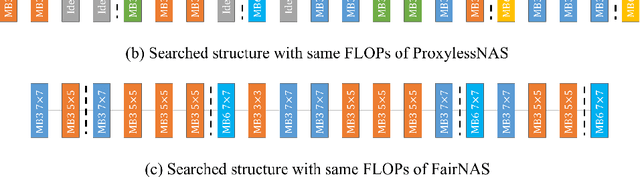
In this work, we present a simple and general search space shrinking method, called Angle-Based search space Shrinking (ABS), for Neural Architecture Search (NAS). Our approach progressively simplifies the original search space by dropping unpromising candidates, thus can reduce difficulties for existing NAS methods to find superior architectures. In particular, we propose an angle-based metric to guide the shrinking process. We provide comprehensive evidences showing that, in weight-sharing supernet, the proposed metric is more stable and accurate than accuracy-based and magnitude-based metrics to predict the capability of child models. We also show that the angle-based metric can converge fast while training supernet, enabling us to get promising shrunk search spaces efficiently. ABS can easily apply to most of popular NAS approaches (e.g. SPOS, FariNAS, ProxylessNAS, DARTS and PDARTS). Comprehensive experiments show that ABS can dramatically enhance existing NAS approaches by providing a promising shrunk search space.
Cluster Regularized Quantization for Deep Networks Compression
Feb 27, 2019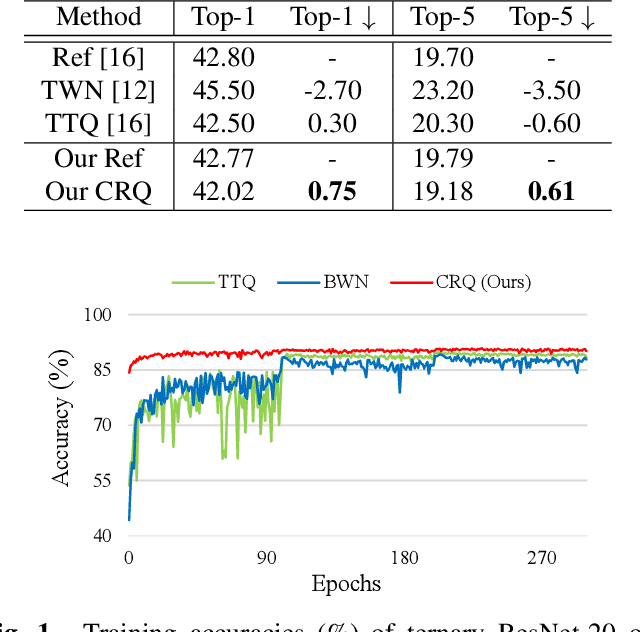


Deep neural networks (DNNs) have achieved great success in a wide range of computer vision areas, but the applications to mobile devices is limited due to their high storage and computational cost. Much efforts have been devoted to compress DNNs. In this paper, we propose a simple yet effective method for deep networks compression, named Cluster Regularized Quantization (CRQ), which can reduce the presentation precision of a full-precision model to ternary values without significant accuracy drop. In particular, the proposed method aims at reducing the quantization error by introducing a cluster regularization term, which is imposed on the full-precision weights to enable them naturally concentrate around the target values. Through explicitly regularizing the weights during the re-training stage, the full-precision model can achieve the smooth transition to the low-bit one. Comprehensive experiments on benchmark datasets demonstrate the effectiveness of the proposed method.