 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPUV3INT8: A Compiler View to programmable FPGA Inference Engines
Oct 08, 2021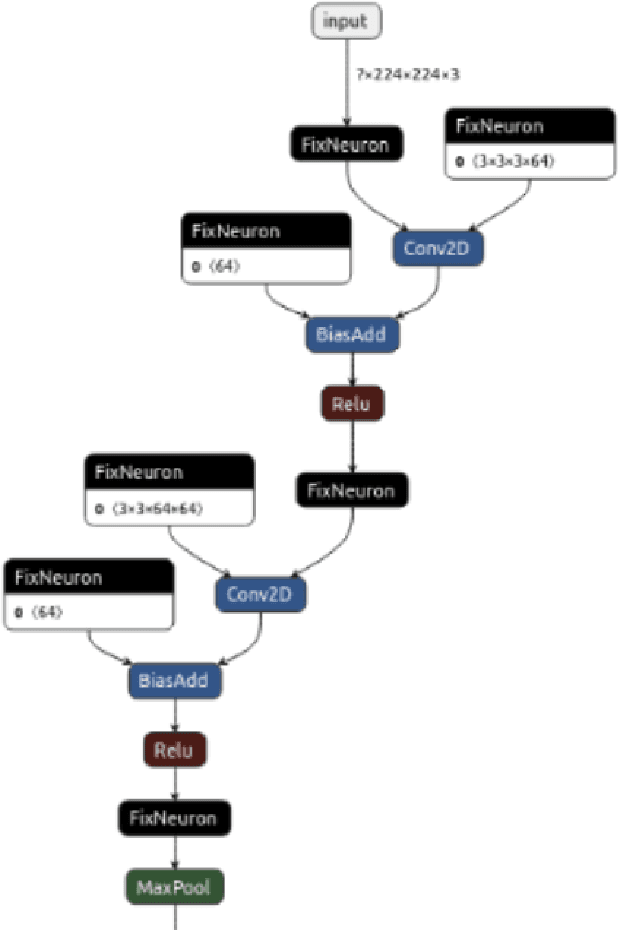
We have a FPGA design, we make it fast, efficient, and tested for a few important examples. Now we must infer a general solution to deploy in the data center. Here, we describe the FPGA DPUV3INT8 design and our compiler effort. The hand-tuned SW-HW solution for Resnet50\_v1 has (close to) 2 times better images per second (throughput) than our best FPGA implementation; the compiler generalizes the hand written techniques achieving about 1.5 times better performance for the same example, the compiler generalizes the optimizations to a model zoo of networks, and it achieves 80+\% HW efficiency.
Quantizing Convolutional Neural Networks for Low-Power High-Throughput Inference Engines
May 21, 2018
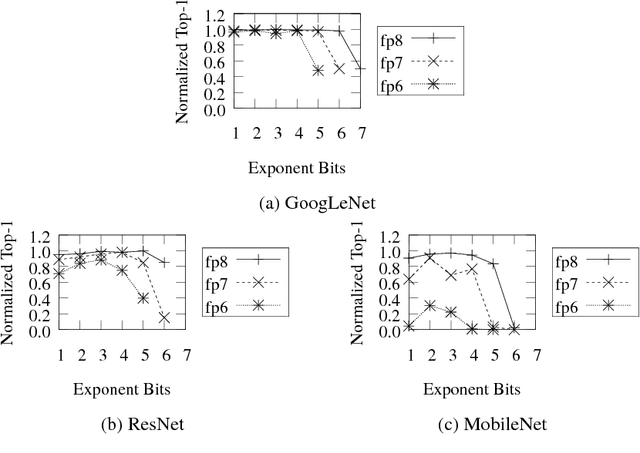
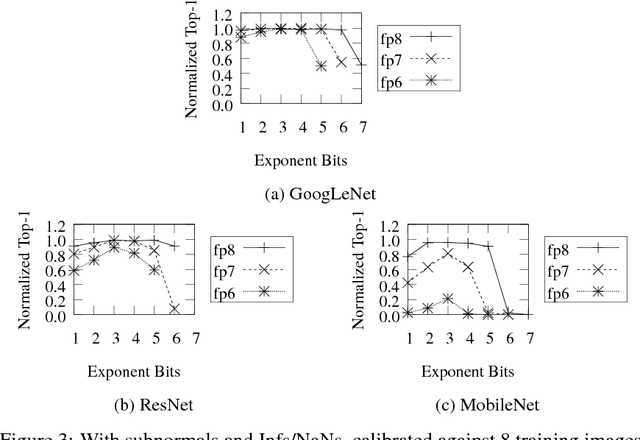
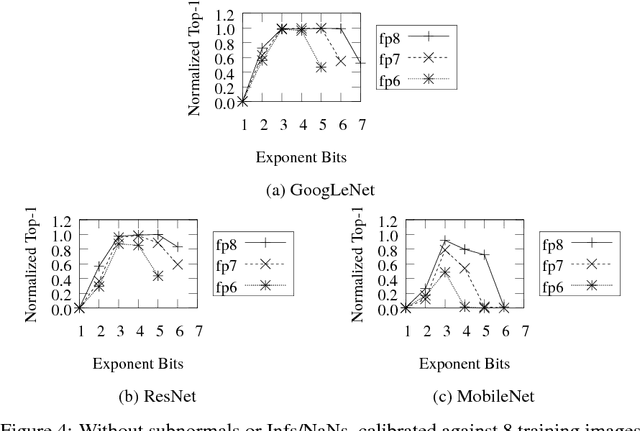
Deep learning as a means to inferencing has proliferated thanks to its versatility and ability to approach or exceed human-level accuracy. These computational models have seemingly insatiable appetites for computational resources not only while training, but also when deployed at scales ranging from data centers all the way down to embedded devices. As such, increasing consideration is being made to maximize the computational efficiency given limited hardware and energy resources and, as a result, inferencing with reduced precision has emerged as a viable alternative to the IEEE 754 Standard for Floating-Point Arithmetic. We propose a quantization scheme that allows inferencing to be carried out using arithmetic that is fundamentally more efficient when compared to even half-precision floating-point. Our quantization procedure is significant in that we determine our quantization scheme parameters by calibrating against its reference floating-point model using a single inference batch rather than (re)training and achieve end-to-end post quantization accuracies comparable to the reference model.