 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeDGS: Aerial Gaussian Splatting for Distant DBH Measurement
Jan 19, 2026Aerial remote sensing enables efficient large-area surveying, but accurate direct object-level measurement remains difficult in complex natural scenes. Recent advancements in 3D vision, particularly learned radiance-field representations such as NeRF and 3D Gaussian Splatting, have begun to raise the ceiling on reconstruction fidelity and densifiable geometry from posed imagery. Nevertheless, direct aerial measurement of important natural attributes such as tree diameter at breast height (DBH) remains challenging. Trunks in aerial forest scans are distant and sparsely observed in image views: at typical operating altitudes, stems may span only a few pixels. With these constraints, conventional reconstruction methods leave breast-height trunk geometry weakly constrained. We present TreeDGS, an aerial image reconstruction method that leverages 3D Gaussian Splatting as a continuous, densifiable scene representation for trunk measurement. After SfM-MVS initialization and Gaussian optimization, we extract a dense point set from the Gaussian field using RaDe-GS's depth-aware cumulative-opacity integration and associate each sample with a multi-view opacity reliability score. We then estimate DBH from trunk-isolated points using opacity-weighted solid-circle fitting. Evaluated on 10 plots with field-measured DBH, TreeDGS reaches 4.79,cm RMSE (about 2.6 pixels at this GSD) and outperforms a state-of-the-art LiDAR baseline (7.91,cm RMSE), demonstrating that densified splat-based geometry can enable accurate, low-cost aerial DBH measurement.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Trained Uniform Quantization for Accurate and Efficient Neural Network Inference on Fixed-Point Hardware
Mar 19, 2019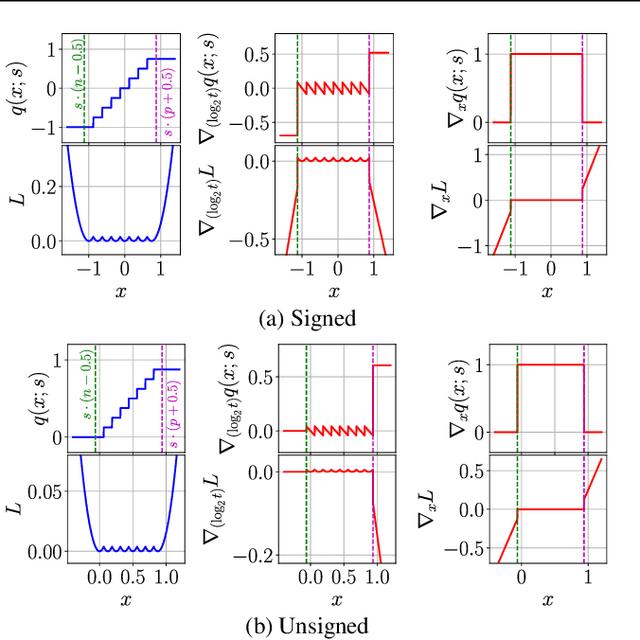
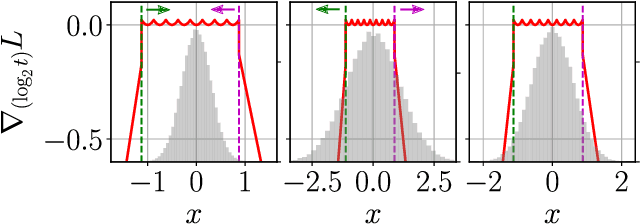

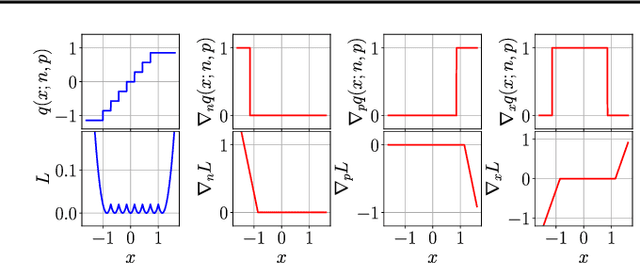
We propose a method of training quantization clipping thresholds for uniform symmetric quantizers using standard backpropagation and gradient descent. Our quantizers are constrained to use power-of-2 scale-factors and per-tensor scaling for weights and activations. These constraints make our methods better suited for hardware implementations. Training with these difficult constraints is enabled by a combination of three techniques: using accurate threshold gradients to achieve range-precision trade-off, training thresholds in log-domain, and training with an adaptive gradient optimizer. We refer to this collection of techniques as Adaptive-Gradient Log-domain Threshold Training (ALT). We present analytical support for the general robustness of our methods and empirically validate them on various CNNs for ImageNet classification. We are able to achieve floating-point or near-floating-point accuracy on traditionally difficult networks such as MobileNets in less than 5 epochs of quantized (8-bit) retraining. Finally, we present Graffitist, a framework that enables immediate quantization of TensorFlow graphs using our methods. Code available at https://github.com/Xilinx/graffitist .
Quantizing Convolutional Neural Networks for Low-Power High-Throughput Inference Engines
May 21, 2018
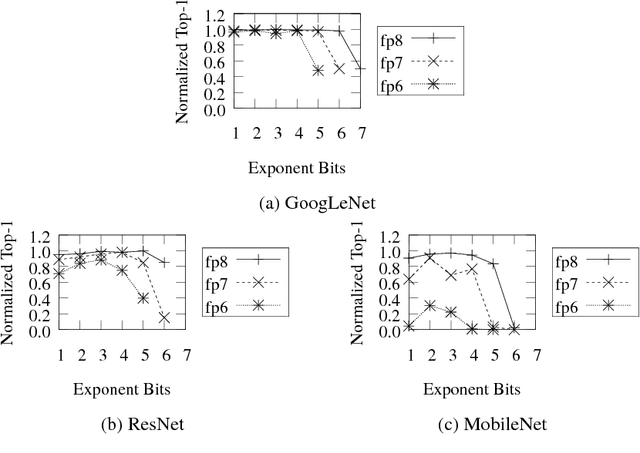
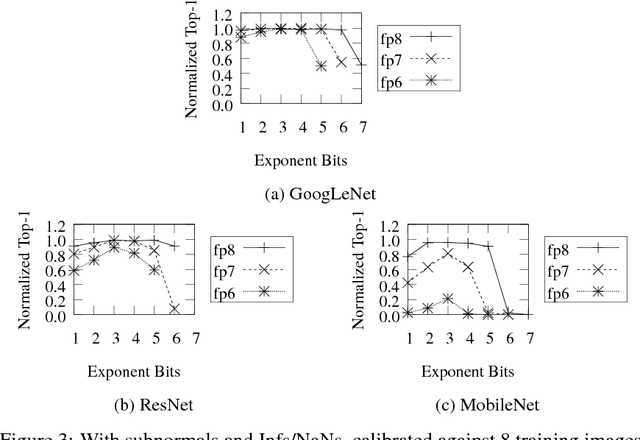
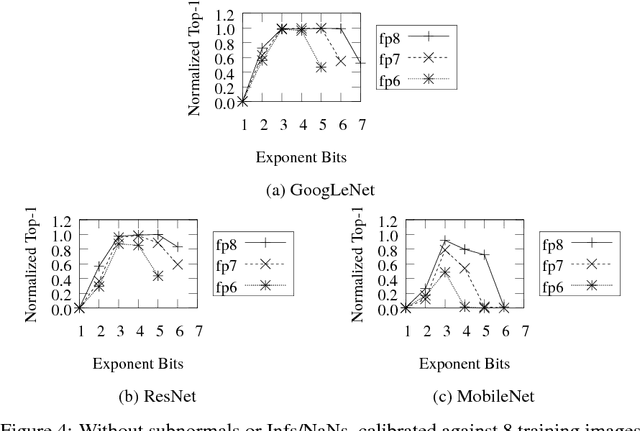
Deep learning as a means to inferencing has proliferated thanks to its versatility and ability to approach or exceed human-level accuracy. These computational models have seemingly insatiable appetites for computational resources not only while training, but also when deployed at scales ranging from data centers all the way down to embedded devices. As such, increasing consideration is being made to maximize the computational efficiency given limited hardware and energy resources and, as a result, inferencing with reduced precision has emerged as a viable alternative to the IEEE 754 Standard for Floating-Point Arithmetic. We propose a quantization scheme that allows inferencing to be carried out using arithmetic that is fundamentally more efficient when compared to even half-precision floating-point. Our quantization procedure is significant in that we determine our quantization scheme parameters by calibrating against its reference floating-point model using a single inference batch rather than (re)training and achieve end-to-end post quantization accuracies comparable to the reference model.