 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Training of Deep Neural Networks for Emerging Memory Technology
Sep 08, 2020



The recent success of neural networks for solving difficult decision talrt has incentivized incorporating smart decision making "at the edge." However, this work has traditionally focused on neural network inference, rather than training, due to memory and compute limitations, especially in emerging non-volatile memory systems, where writes are energetically costly and reduce lifespan. Yet, the ability to train at the edge is becoming increasingly important as it enables real-time adaptability to device drift and environmental variation, user customization, and federated learning across devices. In this work, we address two key challenges for training on edge devices with non-volatile memory: low write density and low auxiliary memory. We present a low-rank training scheme that addresses these challenges while maintaining computational efficiency. We then demonstrate the technique on a representative convolutional neural network across several adaptation problems, where it out-performs standard SGD both in accuracy and in number of weight writes.
Trained Uniform Quantization for Accurate and Efficient Neural Network Inference on Fixed-Point Hardware
Mar 19, 2019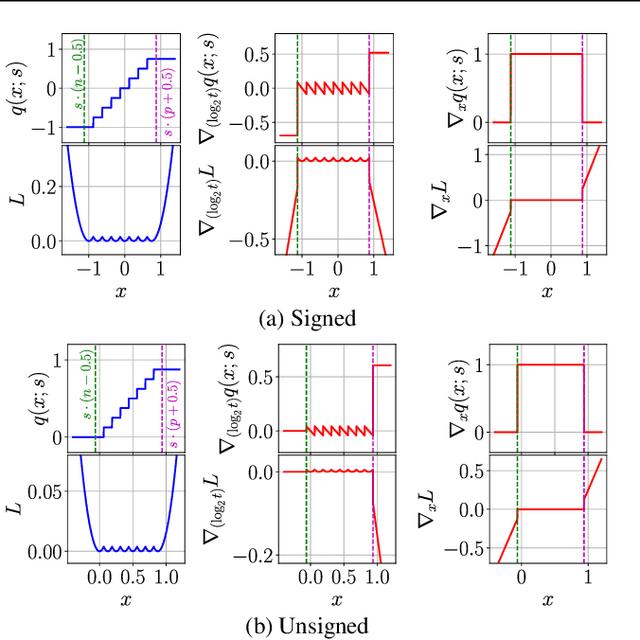
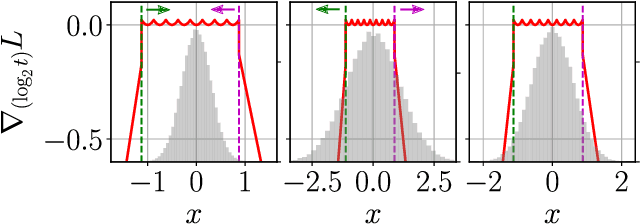

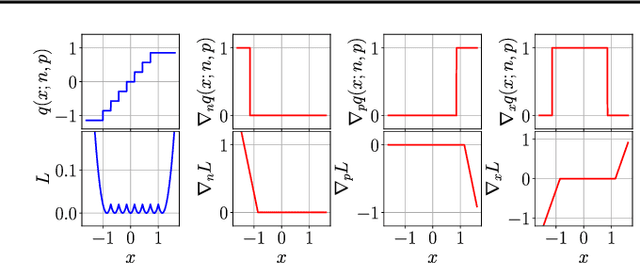
We propose a method of training quantization clipping thresholds for uniform symmetric quantizers using standard backpropagation and gradient descent. Our quantizers are constrained to use power-of-2 scale-factors and per-tensor scaling for weights and activations. These constraints make our methods better suited for hardware implementations. Training with these difficult constraints is enabled by a combination of three techniques: using accurate threshold gradients to achieve range-precision trade-off, training thresholds in log-domain, and training with an adaptive gradient optimizer. We refer to this collection of techniques as Adaptive-Gradient Log-domain Threshold Training (ALT). We present analytical support for the general robustness of our methods and empirically validate them on various CNNs for ImageNet classification. We are able to achieve floating-point or near-floating-point accuracy on traditionally difficult networks such as MobileNets in less than 5 epochs of quantized (8-bit) retraining. Finally, we present Graffitist, a framework that enables immediate quantization of TensorFlow graphs using our methods. Code available at https://github.com/Xilinx/graffitist .