 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Machine: Rethinking Action Recognition in Trimmed Videos
Paper and Code
Dec 17, 2018
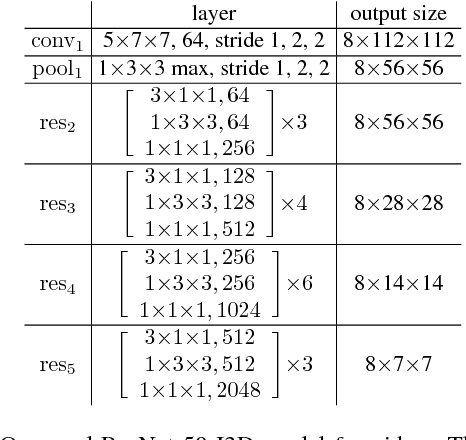
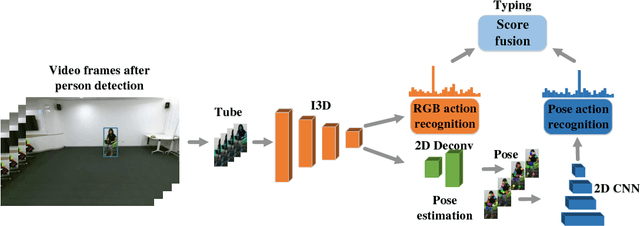

Existing methods in video action recognition mostly do not distinguish human body from the environment and easily overfit the scenes and objects. In this work, we present a conceptually simple, general and high-performance framework for action recognition in trimmed videos, aiming at person-centric modeling. The method, called Action Machine, takes as inputs the videos cropped by person bounding boxes. It extends the Inflated 3D ConvNet (I3D) by adding a branch for human pose estimation and a 2D CNN for pose-based action recognition, being fast to train and test. Action Machine can benefit from the multi-task training of action recognition and pose estimation, the fusion of predictions from RGB images and poses. On NTU RGB-D, Action Machine achieves the state-of-the-art performance with top-1 accuracies of 97.2% and 94.3% on cross-view and cross-subject respectively. Action Machine also achieves competitive performance on another three smaller action recognition datasets: Northwestern UCLA Multiview Action3D, MSR Daily Activity3D and UTD-MHAD. Code will be made available.