 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBe Your Own Red Teamer: Safety Alignment via Self-Play and Reflective Experience Replay
Jan 15, 2026Large Language Models (LLMs) have achieved remarkable capabilities but remain vulnerable to adversarial ``jailbreak'' attacks designed to bypass safety guardrails. Current safety alignment methods depend heavily on static external red teaming, utilizing fixed defense prompts or pre-collected adversarial datasets. This leads to a rigid defense that overfits known patterns and fails to generalize to novel, sophisticated threats. To address this critical limitation, we propose empowering the model to be its own red teamer, capable of achieving autonomous and evolving adversarial attacks. Specifically, we introduce Safety Self- Play (SSP), a system that utilizes a single LLM to act concurrently as both the Attacker (generating jailbreaks) and the Defender (refusing harmful requests) within a unified Reinforcement Learning (RL) loop, dynamically evolving attack strategies to uncover vulnerabilities while simultaneously strengthening defense mechanisms. To ensure the Defender effectively addresses critical safety issues during the self-play, we introduce an advanced Reflective Experience Replay Mechanism, which uses an experience pool accumulated throughout the process. The mechanism employs a Upper Confidence Bound (UCB) sampling strategy to focus on failure cases with low rewards, helping the model learn from past hard mistakes while balancing exploration and exploitation. Extensive experiments demonstrate that our SSP approach autonomously evolves robust defense capabilities, significantly outperforming baselines trained on static adversarial datasets and establishing a new benchmark for proactive safety alignment.
Native Parallel Reasoner: Reasoning in Parallelism via Self-Distilled Reinforcement Learning
Dec 19, 2025We introduce Native Parallel Reasoner (NPR), a teacher-free framework that enables Large Language Models (LLMs) to self-evolve genuine parallel reasoning capabilities. NPR transforms the model from sequential emulation to native parallel cognition through three key innovations: 1) a self-distilled progressive training paradigm that transitions from ``cold-start'' format discovery to strict topological constraints without external supervision; 2) a novel Parallel-Aware Policy Optimization (PAPO) algorithm that optimizes branching policies directly within the execution graph, allowing the model to learn adaptive decomposition via trial and error; and 3) a robust NPR Engine that refactors memory management and flow control of SGLang to enable stable, large-scale parallel RL training. Across eight reasoning benchmarks, NPR trained on Qwen3-4B achieves performance gains of up to 24.5% and inference speedups up to 4.6x. Unlike prior baselines that often fall back to autoregressive decoding, NPR demonstrates 100% genuine parallel execution, establishing a new standard for self-evolving, efficient, and scalable agentic reasoning.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
PISanitizer: Preventing Prompt Injection to Long-Context LLMs via Prompt Sanitization
Nov 13, 2025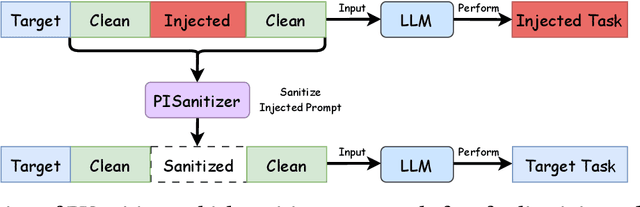
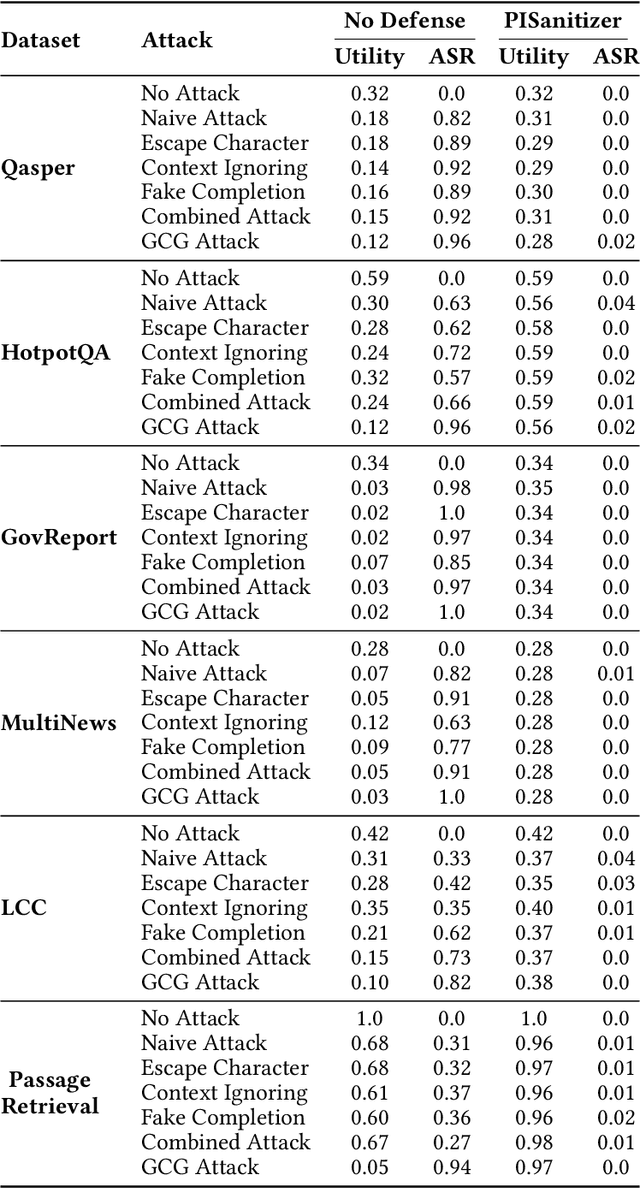
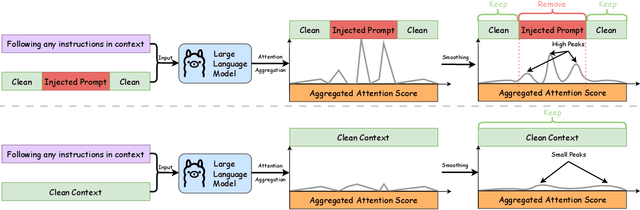

Long context LLMs are vulnerable to prompt injection, where an attacker can inject an instruction in a long context to induce an LLM to generate an attacker-desired output. Existing prompt injection defenses are designed for short contexts. When extended to long-context scenarios, they have limited effectiveness. The reason is that an injected instruction constitutes only a very small portion of a long context, making the defense very challenging. In this work, we propose PISanitizer, which first pinpoints and sanitizes potential injected tokens (if any) in a context before letting a backend LLM generate a response, thereby eliminating the influence of the injected instruction. To sanitize injected tokens, PISanitizer builds on two observations: (1) prompt injection attacks essentially craft an instruction that compels an LLM to follow it, and (2) LLMs intrinsically leverage the attention mechanism to focus on crucial input tokens for output generation. Guided by these two observations, we first intentionally let an LLM follow arbitrary instructions in a context and then sanitize tokens receiving high attention that drive the instruction-following behavior of the LLM. By design, PISanitizer presents a dilemma for an attacker: the more effectively an injected instruction compels an LLM to follow it, the more likely it is to be sanitized by PISanitizer. Our extensive evaluation shows that PISanitizer can successfully prevent prompt injection, maintain utility, outperform existing defenses, is efficient, and is robust to optimization-based and strong adaptive attacks. The code is available at https://github.com/sleeepeer/PISanitizer.
UniC-RAG: Universal Knowledge Corruption Attacks to Retrieval-Augmented Generation
Aug 26, 2025Retrieval-augmented generation (RAG) systems are widely deployed in real-world applications in diverse domains such as finance, healthcare, and cybersecurity. However, many studies showed that they are vulnerable to knowledge corruption attacks, where an attacker can inject adversarial texts into the knowledge database of a RAG system to induce the LLM to generate attacker-desired outputs. Existing studies mainly focus on attacking specific queries or queries with similar topics (or keywords). In this work, we propose UniC-RAG, a universal knowledge corruption attack against RAG systems. Unlike prior work, UniC-RAG jointly optimizes a small number of adversarial texts that can simultaneously attack a large number of user queries with diverse topics and domains, enabling an attacker to achieve various malicious objectives, such as directing users to malicious websites, triggering harmful command execution, or launching denial-of-service attacks. We formulate UniC-RAG as an optimization problem and further design an effective solution to solve it, including a balanced similarity-based clustering method to enhance the attack's effectiveness. Our extensive evaluations demonstrate that UniC-RAG is highly effective and significantly outperforms baselines. For instance, UniC-RAG could achieve over 90% attack success rate by injecting 100 adversarial texts into a knowledge database with millions of texts to simultaneously attack a large set of user queries (e.g., 2,000). Additionally, we evaluate existing defenses and show that they are insufficient to defend against UniC-RAG, highlighting the need for new defense mechanisms in RAG systems.
TracLLM: A Generic Framework for Attributing Long Context LLMs
Jun 06, 2025Long context large language models (LLMs) are deployed in many real-world applications such as RAG, agent, and broad LLM-integrated applications. Given an instruction and a long context (e.g., documents, PDF files, webpages), a long context LLM can generate an output grounded in the provided context, aiming to provide more accurate, up-to-date, and verifiable outputs while reducing hallucinations and unsupported claims. This raises a research question: how to pinpoint the texts (e.g., sentences, passages, or paragraphs) in the context that contribute most to or are responsible for the generated output by an LLM? This process, which we call context traceback, has various real-world applications, such as 1) debugging LLM-based systems, 2) conducting post-attack forensic analysis for attacks (e.g., prompt injection attack, knowledge corruption attacks) to an LLM, and 3) highlighting knowledge sources to enhance the trust of users towards outputs generated by LLMs. When applied to context traceback for long context LLMs, existing feature attribution methods such as Shapley have sub-optimal performance and/or incur a large computational cost. In this work, we develop TracLLM, the first generic context traceback framework tailored to long context LLMs. Our framework can improve the effectiveness and efficiency of existing feature attribution methods. To improve the efficiency, we develop an informed search based algorithm in TracLLM. We also develop contribution score ensemble/denoising techniques to improve the accuracy of TracLLM. Our evaluation results show TracLLM can effectively identify texts in a long context that lead to the output of an LLM. Our code and data are at: https://github.com/Wang-Yanting/TracLLM.
TrojanDec: Data-free Detection of Trojan Inputs in Self-supervised Learning
Jan 07, 2025An image encoder pre-trained by self-supervised learning can be used as a general-purpose feature extractor to build downstream classifiers for various downstream tasks. However, many studies showed that an attacker can embed a trojan into an encoder such that multiple downstream classifiers built based on the trojaned encoder simultaneously inherit the trojan behavior. In this work, we propose TrojanDec, the first data-free method to identify and recover a test input embedded with a trigger. Given a (trojaned or clean) encoder and a test input, TrojanDec first predicts whether the test input is trojaned. If not, the test input is processed in a normal way to maintain the utility. Otherwise, the test input will be further restored to remove the trigger. Our extensive evaluation shows that TrojanDec can effectively identify the trojan (if any) from a given test input and recover it under state-of-the-art trojan attacks. We further demonstrate by experiments that our TrojanDec outperforms the state-of-the-art defenses.
MMCert: Provable Defense against Adversarial Attacks to Multi-modal Models
Apr 02, 2024


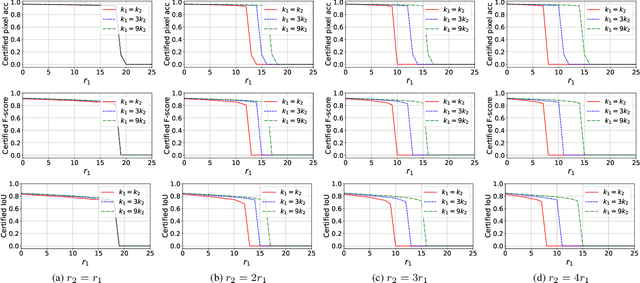
Different from a unimodal model whose input is from a single modality, the input (called multi-modal input) of a multi-modal model is from multiple modalities such as image, 3D points, audio, text, etc. Similar to unimodal models, many existing studies show that a multi-modal model is also vulnerable to adversarial perturbation, where an attacker could add small perturbation to all modalities of a multi-modal input such that the multi-modal model makes incorrect predictions for it. Existing certified defenses are mostly designed for unimodal models, which achieve sub-optimal certified robustness guarantees when extended to multi-modal models as shown in our experimental results. In our work, we propose MMCert, the first certified defense against adversarial attacks to a multi-modal model. We derive a lower bound on the performance of our MMCert under arbitrary adversarial attacks with bounded perturbations to both modalities (e.g., in the context of auto-driving, we bound the number of changed pixels in both RGB image and depth image). We evaluate our MMCert using two benchmark datasets: one for the multi-modal road segmentation task and the other for the multi-modal emotion recognition task. Moreover, we compare our MMCert with a state-of-the-art certified defense extended from unimodal models. Our experimental results show that our MMCert outperforms the baseline.
SFC Deployment in Space-Air-Ground Integrated Networks Based on Matching Game
Mar 02, 2023The space-air-ground integrated network (SAGIN) is dynamic and flexible, which can support transmitting data in environments lacking ground communication facilities. However, the nodes of SAGIN are heterogeneous and it is intractable to share the resources to provide multiple services. Therefore, in this paper, we consider using network function virtualization technology to handle the problem of agile resource allocation. In particular, the service function chains (SFCs) are constructed to deploy multiple virtual network functions of different tasks. To depict the dynamic model of SAGIN, we propose the reconfigurable time extension graph. Then, an optimization problem is formulated to maximize the number of completed tasks, i.e., the successful deployed SFC. It is a mixed integer linear programming problem, which is hard to solve in limited time complexity. Hence, we transform it as a many-to-one two-sided matching game problem. Then, we design a Gale-Shapley based algorithm. Finally, via abundant simulations, it is verified that the designed algorithm can effectively deploy SFCs with efficient resource utilization.